
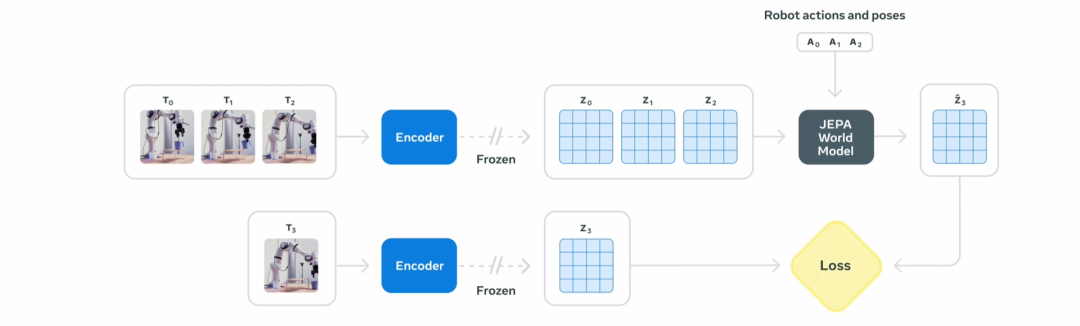
meta 又发了新模型——V-JEPA 2 (Video Joint Embedding Predictive Architecture 2),这是个视频理解模型,能判断视频中正在发生什么并进行一定程度的预测。并且亮点应用是零样本机器人控制(如果用yolo需要针对训练,但是大模型的知识具有迁移性,视觉中出现新东西不用训练也能操作)。根据官方报告,这个模型的技术创新有:
-
自我监督学习:模型不需要大量标注数据,而是通过”自己教自己”的方式学习 -
遮挡预测机制:模型通过”填空题”的方式学习 – 遮住视频的某些部分,让模型预测被遮住的内容 -
抽象表征学习:模型不是简单地记忆像素,而是学习视频的”抽象含义” -
世界模型架构:模型构建了对物理世界的内在理解,能够”想象”物体如何运动和互动 -
高效的迁移能力:模型学会基础的物理理解后,可以快速适应新任务
参考文献:
[1] 模型地址:https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6
[2] blog:https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)