


新智元报道
新智元报道
【新智元导读】推理模型开始「自言自语」、量子计算进入临界点……AI大航海时代已然启航,这不是一次产品发布会,而是未来的预言书。巴黎GTC大会,黄仁勋开讲了!这次他脱下了皮衣。
「AI是世界上创造的最伟大的平等工具。」
在巴黎,黄仁勋这样说道。
他表示,人工智能既不会引发反乌托邦式灾难,也不会导致垄断,它是解放人类的工具。

再巴黎GTC会议后的新闻发布会上,黄仁勋认为AI的确改变了职场,但驳斥了Dario Amodei最近关于AI导致大裁员的预测:
每个人的工作都会发生变化。虽然部分岗位会被替代,但也会涌现出大量新职业……
当公司更具生产力时,他们会雇佣更多人。

这次英伟达还签了个大单:直接卖了1万块GPU!
这些GPU将用于在德国建设全球首个工业AI云平台,加速欧洲工业巨头的制造应用。

英伟达2026财年第一季度财报出来时,黄仁勋表示欧洲AI意识觉醒,算力需求爆发。他将拜访多个欧洲国家首脑。
这次欧洲之行,英伟达收获满满,包括与法国、德国、意大利等国家达成合作。
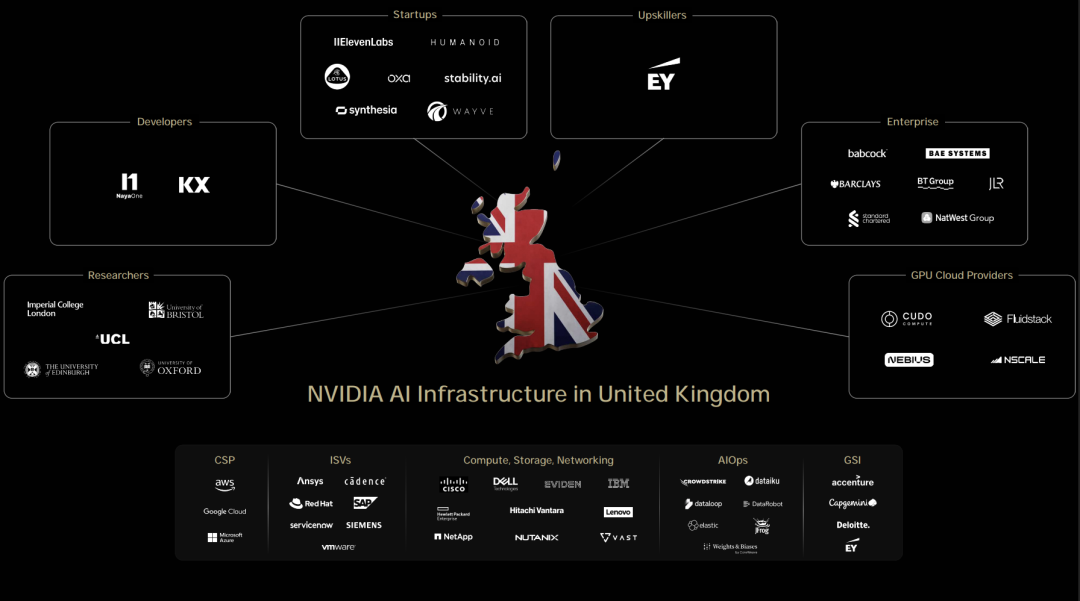
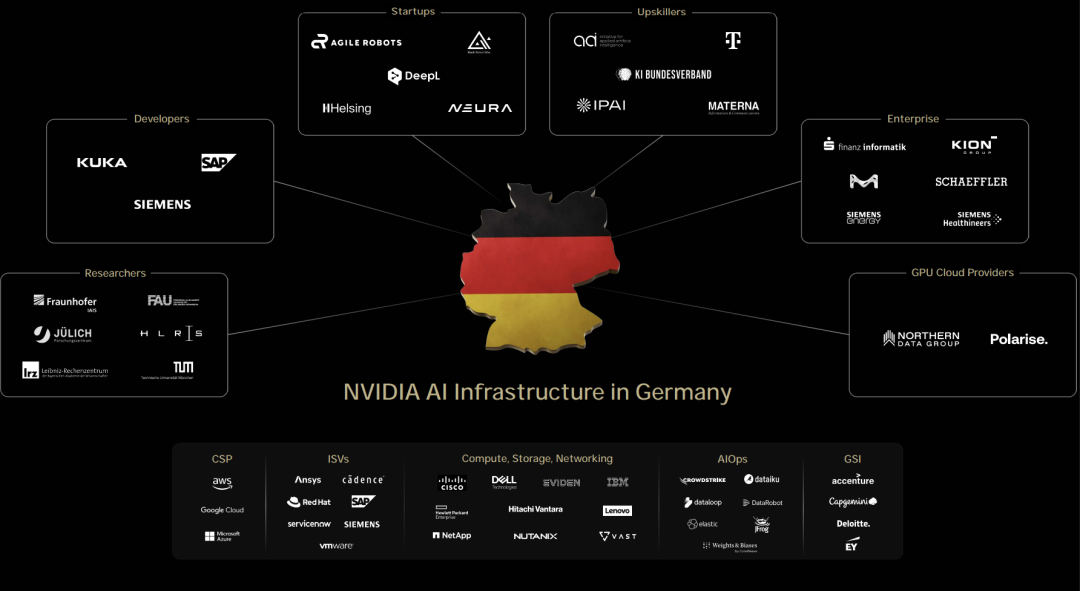
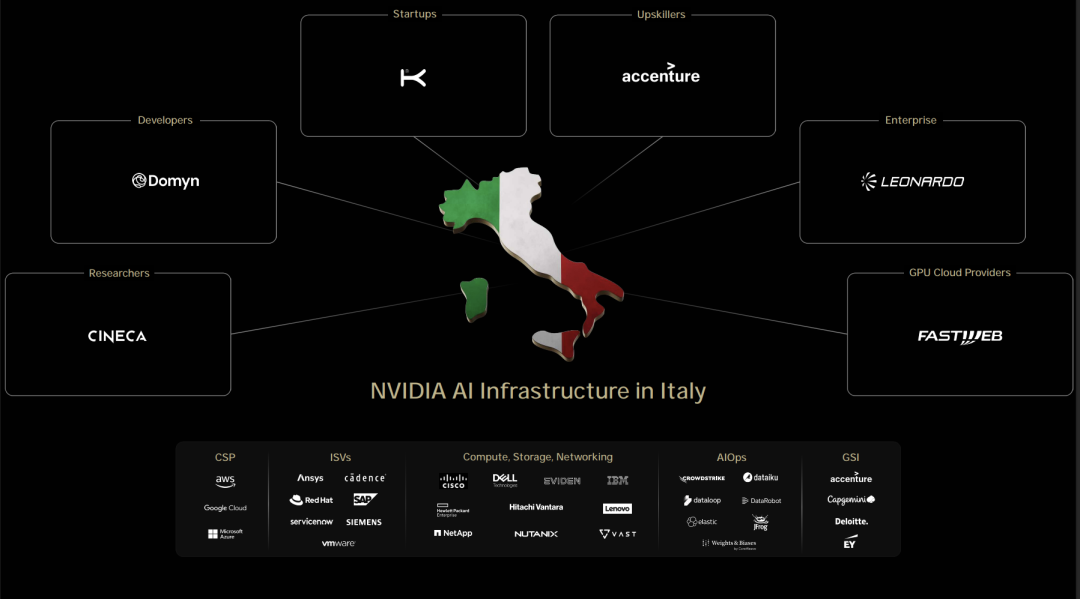
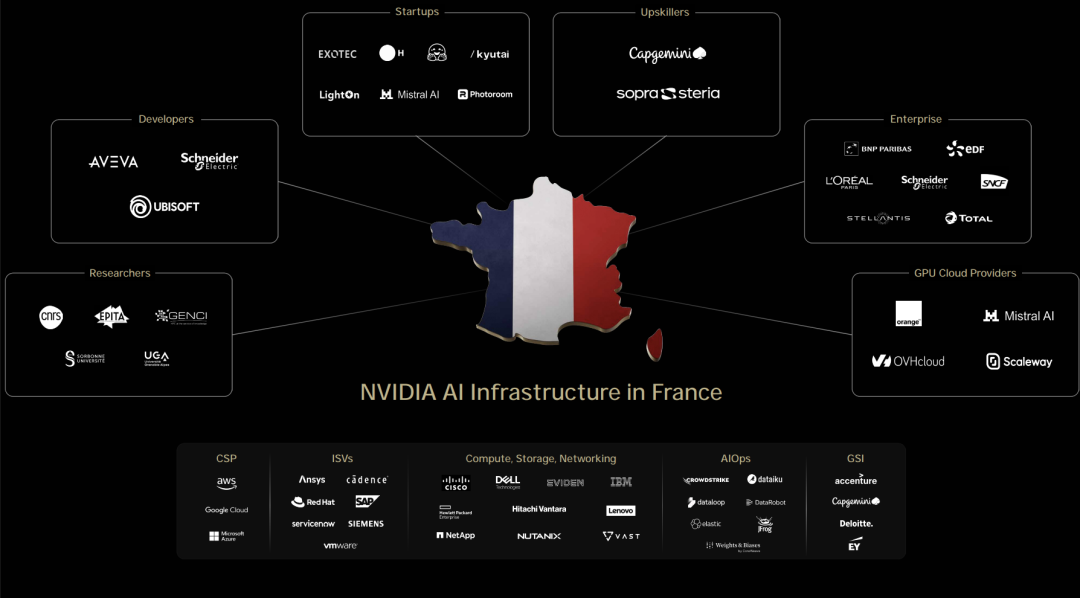
左右滑动查看
此外,与多家公司和研究机构建立了合作关系,包括与Mistral合作开发AI云服务等。
黄仁勋还宣布了DGX Lepton项目,助力欧洲扩大AI影响力:
DGX Cloud Lepton正在连接欧洲开发者与全球AI基础设施。我们正在与来自欧洲的伙伴共同打造AI工厂网络,供开发者、研究人员和企业将本地的突破性成果扩展为全球性创新。
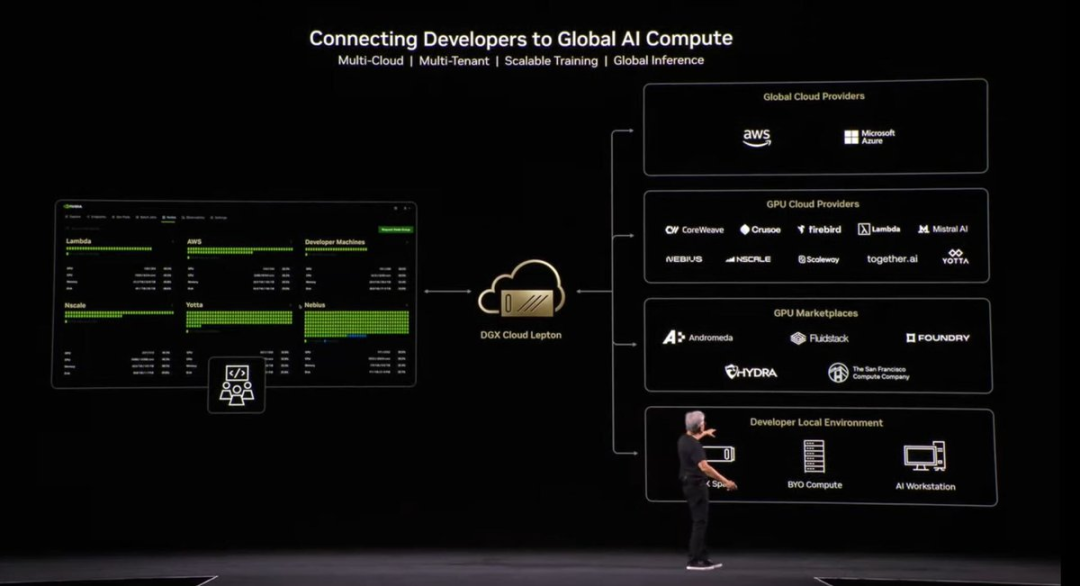
这意味着客户能够自动将推理工作负载从不同的云平台之间转移,同时理论上保持相同的软件用户界面和体验。
如果DGX Lepton成功,它将为所有新云(neocloud)创建标准的用户体验、价值和性能水平,这将导致这些新云陷入激烈的价格战,最终使利润降至极低的商品水平。
这是英伟达首次在巴黎举行GTC大会,拉开2025年VivaTech的序幕,揭示了从智能体系统到AI工厂的下一阶段AI计算。


正是英伟达的GPU,使AI革命成为可能。
而AI,早已是英伟达关注的重点。
在巴黎GTC上,黄仁勋回顾了AI的发展,强调了AI在理解、感知、推理、规划和执行任务方面的进步。

AI的第一波浪潮:感知智能
回到2012年,那时英伟达与开发者合作,「深度学习」的新算法横空出世,诞生了AlexNet,这被认为是AI的宇宙大爆炸时刻。
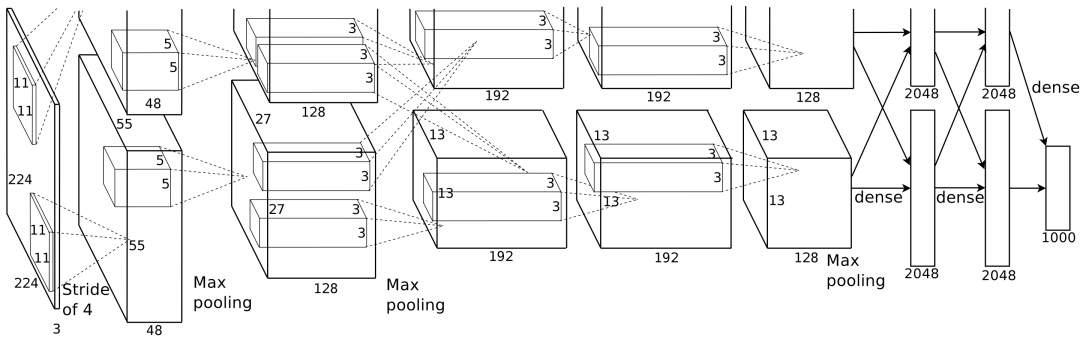
AlexNet由Alex Krizhevsky, Ilya Sutskever,和「深度学习教父」Hinton使用Cuda和C++开发
在过去15年,AI的进展非常迅速。
第一阶段是让计算机看懂图像、听懂语音、识别模式。这就是「感知智能」。
第二波浪潮:生成式人工智能(Generative AI)
最近这五年,AI进入了第二阶段——生成式人工智能GenAI。
AI不只是识别,还能生成图像、生成语言内容。
它拥有「多模态」能力——能够同时理解图像和文字,所以我们可以用文字“提示”AI去创作图像。
这项能力极大地提升了我们生产内容的效率。
AI能写、能画、能说、能演,这开启了「内容生成革命」。
为了支持开源生态,让开发者与企业也能拥有世界一流的大模型,于是英伟达打造了NeMo框架和Nemotron项目。
NeMo是NVIDIA开发的全栈大模型平台,而Nemotron是提升开源模型质量的专项计划。
LLaMA Nemotron针对性强化了开源的Llama模型,效率和准确率大幅度提升。
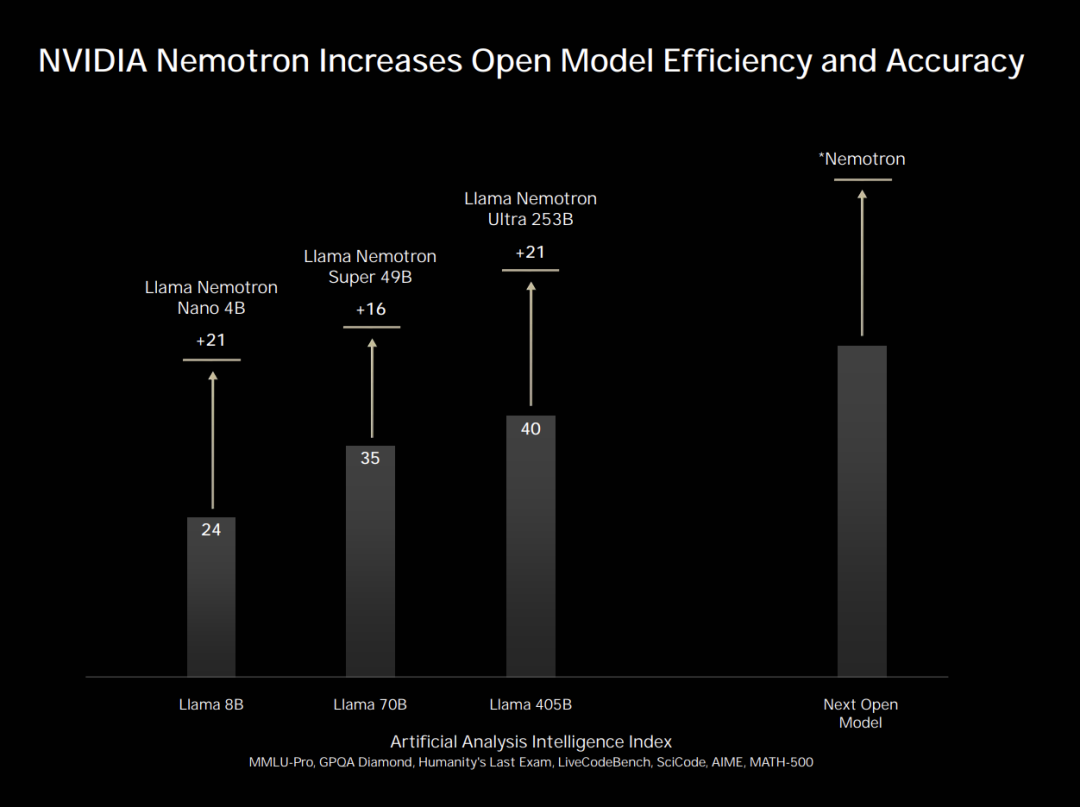
在多个领域,Nemotron模型排名领先,性能优异。

第三波浪潮:Agentic AI
现在进入了第三波浪潮 —— 智能体AI(Agentic AI)。
智能不仅仅是识别或生成内容,更是能“理解、推理、规划并执行任务”。
我们正在开启新一波AI浪潮。
从根本上说,智能是关于理解、感知、推理、规划任务(如何解决问题),然后执行任务。
真正的智能包括三个核心循环:
-
感知(Perception)
-
推理(Reasoning)
-
规划(Planning)
它允许应用一些以前学过的规则,来解决从未见过的问题。
这就是聪明人之所以聪明的原因,他们能够解决复杂问题,将问题一步步分解,思考如何解决问题;也许会进行研究,也许会学习一些新信息,获得一些帮助;使用工具,并一步步解决问题。
智能体AI(Agentic AI)具备这些能力,它能将所学知识应用到新问题中,逐步拆解复杂问题,找到解决方案。比如:
面对没见过的问题,AI可以自己想步骤、找工具、搜索资料、调用其他智能体、整合上下文,并一步步完成任务。
英伟达提供了完整的Agent平台。
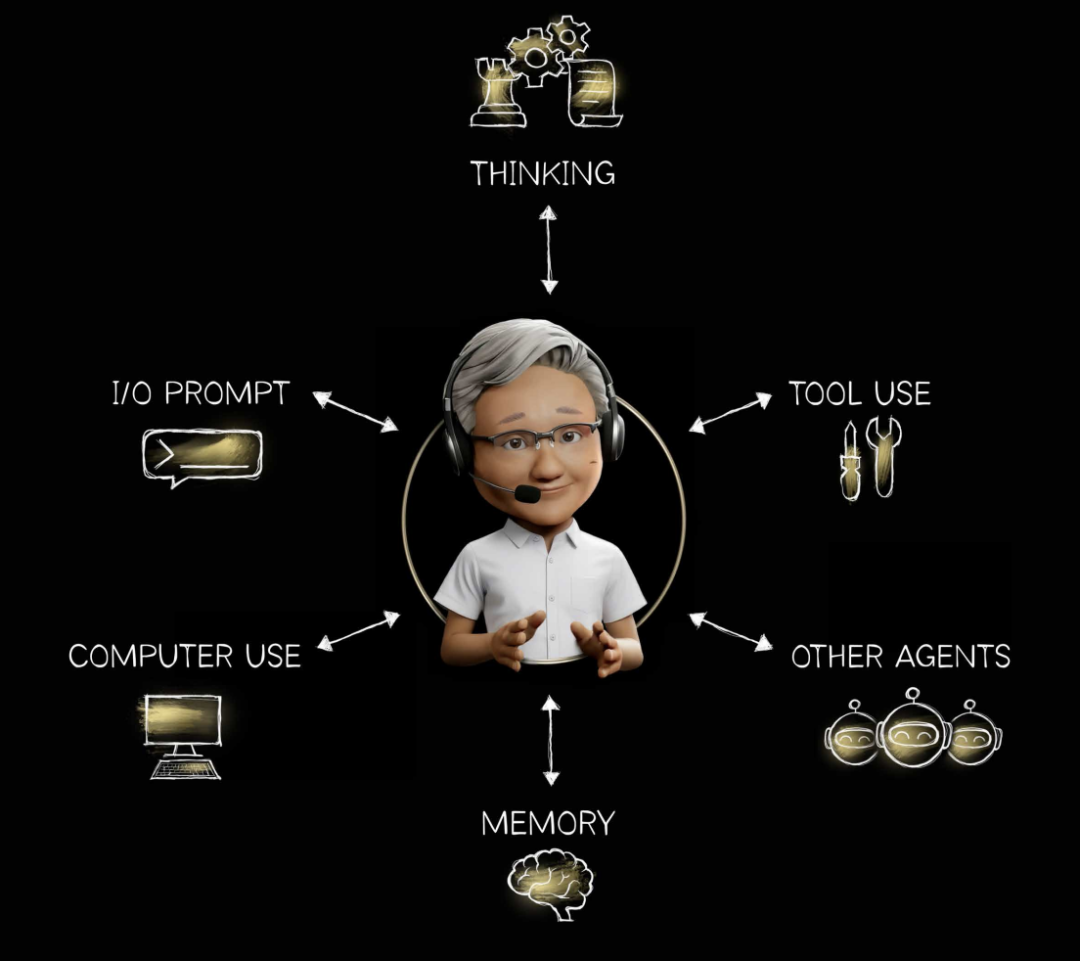
企业客户正在用它构建专属Agent系统:
-
Cisco(思科):用于企业安全情报的AI平台;
-
SAP:将AI集成到业务自动化;
-
DeepL:用于翻译系统的AI平台;
-
PhotoRoom:用于AI图像与视频编辑;
-
Kodo(前Kodium):AI代码助手;
-
Iola:语音交互系统;
-
全球最大临床试验自动化平台:也使用NeMo构建智能体。
第四波浪潮:进入机器人时代
在实际实现中,智能体AI的具身化以及现在的生成能力正在生成运动。
这种AI不是生成视频、图像或文本,而是生成局部运动。它能够行走,或者伸手抓取东西,使用工具。AI以物理形式具身化的能力基本上就是机器人技术。

这些能力,即实现智能体(基本上是信息机器人)和具身化AI(物理机器人)的基本技术,现在已经摆在我们面前。
从虚拟世界走向现实,这就是「具身智能」(Embodied AI)的世界。机器人就是这种智能的物理体现。
目前,我们正处于两个核心AI领域交汇的时刻:
(1)信息型机器人(像ChatGPT这样的聊天助手);
(2)实体型机器人(可以在物理世界中行动的AI)。
这两类智能体现在都已经成为现实,我们正在迎来AI发展的全新时代!
对于AI来说,这真是令人兴奋的时刻。
但这一切都始于都始于英伟达的第一张显卡:GeForce 256。

GeForce 256
GeForce带来了计算机图形。
这是有史以来开发的第一个加速计算应用程序,计算机图形的发展令人难以置信。
GeForce将CUDA带给世界,这使得机器学习研究人员和AI研究人员能够推进深度学习。

随后,深度学习彻底改变了计算机图形,并使我们将计算机图形提升到全新的水平成为可能。
黄仁勋展示了计算机模拟:光子模拟、物理模拟、粒子模拟。
所有一切从根本上来说都是模拟,而不是动画,也不是艺术。
它之所以看起来如此美丽,是因为世界本身就是美丽的,数学也是美丽的。
那么,让我们一起来看看吧。
这本质上就是模拟,而且看起来非常美丽。
现在能够模拟几乎所有事物的规模和速度,可以将所有事物都变成数字孪生。
因为所有事物都可以被数字孪生,我们可以在将其投入物理世界之前,完全以数字方式进行设计、规划、优化和操作。
一切都在软件中构建,英伟达将这一想法现在已经成为现实:
所有物理事物都将以数字方式构建。
所有宏伟的事物都将以数字方式构建。
所有以巨大规模运行的事物都将首先以数字方式构建,并且会有数字孪生来操作它们。
现在的「GB300 NVL 72」看起来是这样的。

该计算设备重两吨半,1.2万个零件,大约300万美元。120千瓦,由150家工厂制造,200家技术合作伙伴与英伟达合作完成
它已经完全投入生产。它被设计成一台思考机器。
这意味着它能够推理、规划,并且像人一样,花费大量时间自言自语。

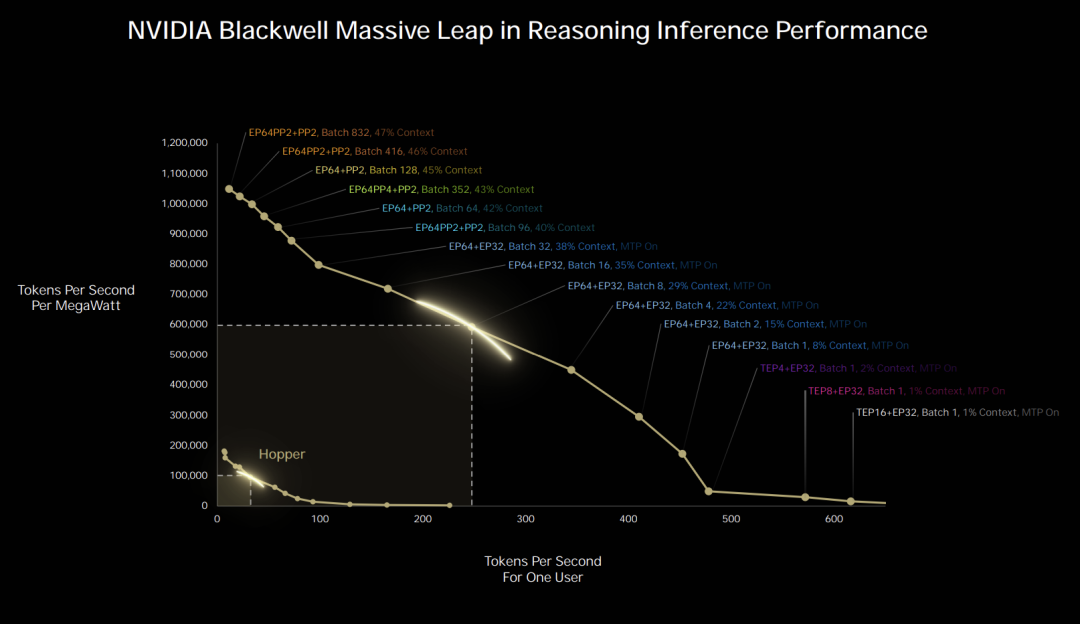
推理模型正在自言自语,我们需要30到40倍的性能提升。
它不再是那种一问一答的ChatGPT,现在是推理模型,当思考时,它会生成更多的token。
它会一步步地分解问题、推理;尝试各种不同的路径:也许是思维链(chain of thoughts),也许是思维树(tree of thoughts)的最佳结果。
它会反思自己的答案。
可能你已经看到这些研究模型在反思答案,说「这是一个好答案吗?你能做得更好吗?」然后推理模型会说:「哦,是的,我能做得更好。」然后回去思考更多。
因此,这些思考模型、推理模型实现了令人难以置信的性能,但这需要更多的算力。
而最终的结果,MVLink 72 Blackwells的架构,带来了性能的巨大飞跃,在仅仅一代之内实现30到40倍的性能提升。

根据摩尔定律,半导体物理学,每三到五年只有大约两倍的性能提升。
而解读下图的方式是:X轴代表它思考的速度。Y轴代表工厂在同一时间支持大量用户时的产出量。
英伟达曾经梦想,创建全新的计算平台,去完成传统计算机无法完成的任务。
他们加速了CPU,创造了一种全新的计算方式,称为「加速计算」。
他们最初的应用之一是分子动力学模拟。从那以后,他们走过了漫长的道路,开发了无数的库。
事实上,使加速计算与众不同的原因在于,它不仅仅是一个新的处理器,也不仅仅是你编译代码就能运行的软件。
你必须彻底重新设计你的计算方式,重新构思你的算法。而这对大多数人来说极其困难——
要将软件和算法重新构建为高度并行化的形式并不容易。
所以,他们创建了各种库,帮助每一个行业、每一个应用领域实现加速。
每一个这样的库都为开发者打开了新的可能。
比如:
-
计算光刻,也许是今天半导体设计中最重要的应用之一;它在台积电、三星等大型晶圆厂中运行,在芯片制造之前会运行一个基于反物理算法的流程,称为Computational Lithography(计算光刻)。
-
稀疏求解器、代数多重网格求解器等。
-
cuOpt:刚刚开源的应用库,它能加速决策制定,优化数百万变量和约束的问题,比如旅行商问题。
这些只是他们提供的部分库。

他们有400多个类似的库,每一个都加速特定的应用领域,每一个都为行业打开新的可能。
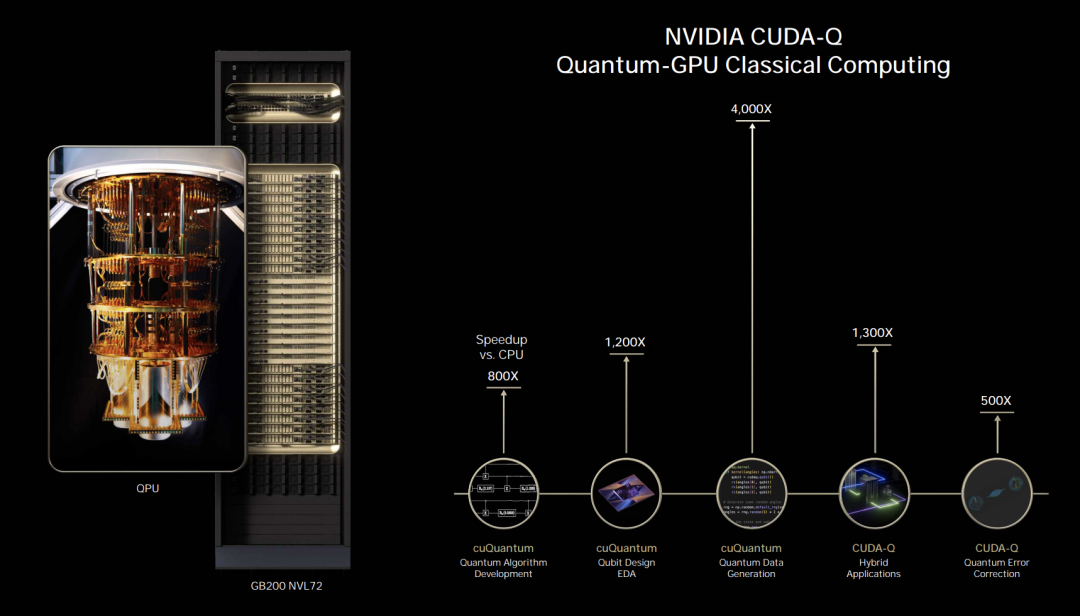
另一个极其重要的是CUDA Q。它将CUDA扩展到量子经典领域。
英伟达开发CUDAQ已经好几年了。
黄仁勋认为:「量子计算正在发生拐点。」
众所周知,在近30年前,第一个物理量子比特就被演示了。
第一一个纠错算法于1995年被发明,而在2023年,将近30年后,世界上第一个逻辑量子比特由谷歌演示。从那时起,几年后,逻辑量子比特的数量(由大量带纠错的物理量子比特表示)开始增长。
就像摩尔定律一样,完全可以预期每5年逻辑量子比特增加10倍,每10年增加100倍。这些逻辑量子比特将得到更好的纠错,更健壮,性能更高,更有弹性,当然也将继续可扩展。
英伟达与世界各地的量子计算公司以多种不同的方式合作,而欧洲相关从业者最多。

现在,英伟达很清楚:「我们已经触手可及,能够在未来几年将量子计算,量子经典计算应用于可以解决一些有趣问题的领域。」
这是真正激动人心的时刻。
在接下来的几年里,或者至少是下一代超级计算机,都将配备QPU,并且QPU将连接到GPU。QPU当然会进行量子计算,而GPU将用于预处理、控制、纠错(这将是计算密集型的)、后处理等。
就像加速CPU一样,现在有QPU与GPU协同工作,以实现下一代计算。
(文:新智元)