



论文:Magistral
链接:https://mistral.ai/static/research/magistral.pdf
为什么说这是推理模型的革命?
关键突破:完全抛弃现成解题数据,仅用数学题和编程题作为题库,通过RL让模型自主探索解题路径,最终在AIME数学竞赛题上准确率提升50%!
纯强化学习的三大方法
-
算法魔改GRPO:抛弃PPO的“监工” critic 模型,用群体平均分作基准(省算力+稳定训练)。公式中红色部分是灵魂改动: 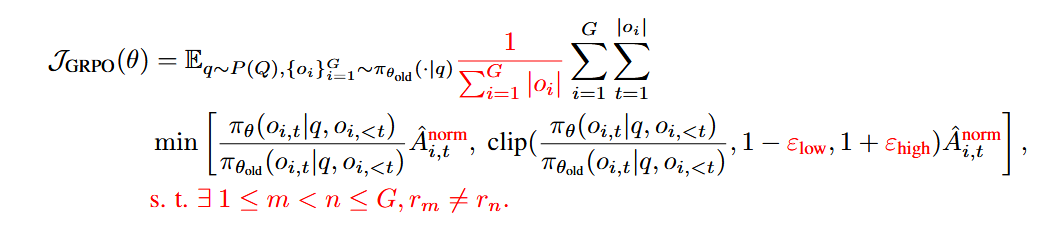 关键操作:放松上限ε
关键操作:放松上限ε(允许探索冷门解题思路)+ 剔除零分小组(避免无效训练)。 -
多语言自由切换:10%题目翻译成6种语言,用语言一致性奖励强制模型用用户语言推理。结果:中文解题也能丝滑输出! 
-
格式严师出高徒:答案必须用 <think>标签包裹,数学答案装进\boxed{},代码用三重引号——格式错直接零分!
训练效率翻倍的方案
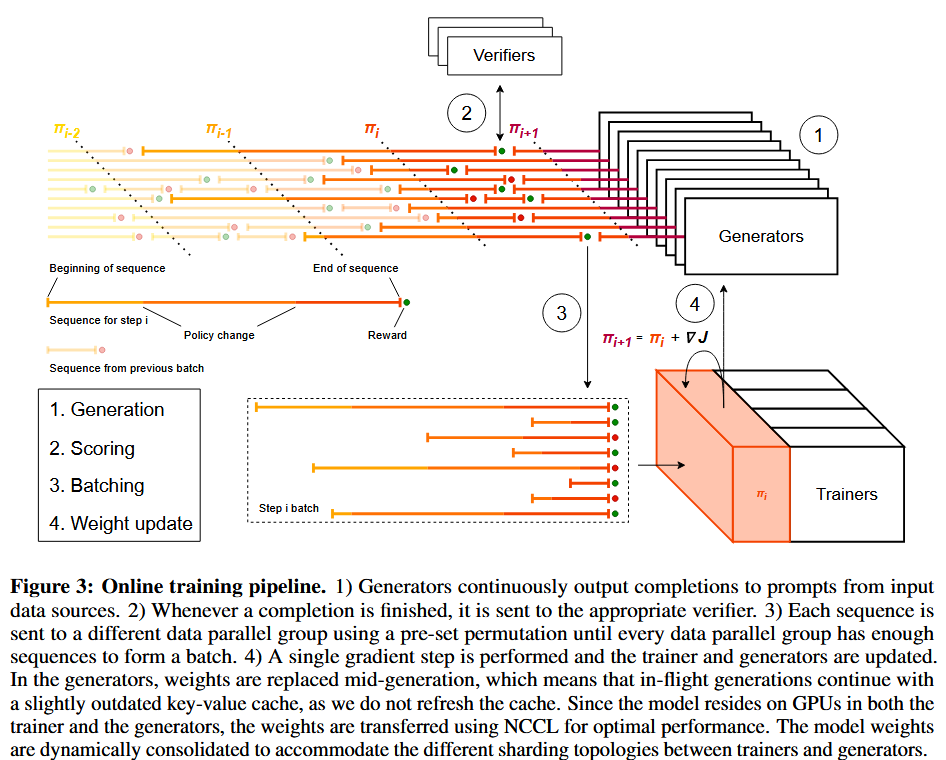
异步流水线架构解决RL训练最大痛点:生成答案速度不均(有的1秒写完,有的卡壳5分钟), 进而会导致生成器频繁空闲,流水线效率低下。
-
三大工人分工: -
Generator(持续生成答案,不等训练器完成更新) -
Verifier(秒批卷子打分) -
Trainer(实时更新模型权重) -
关键技巧: -
权重更新不中断生成 -
权重在生成中途被替换后回继续续使用旧的 KV 缓存 -
利用NCCL 在 GPU 间广播(Broadcast)(单次更新<5秒),GPU利用率拉满!
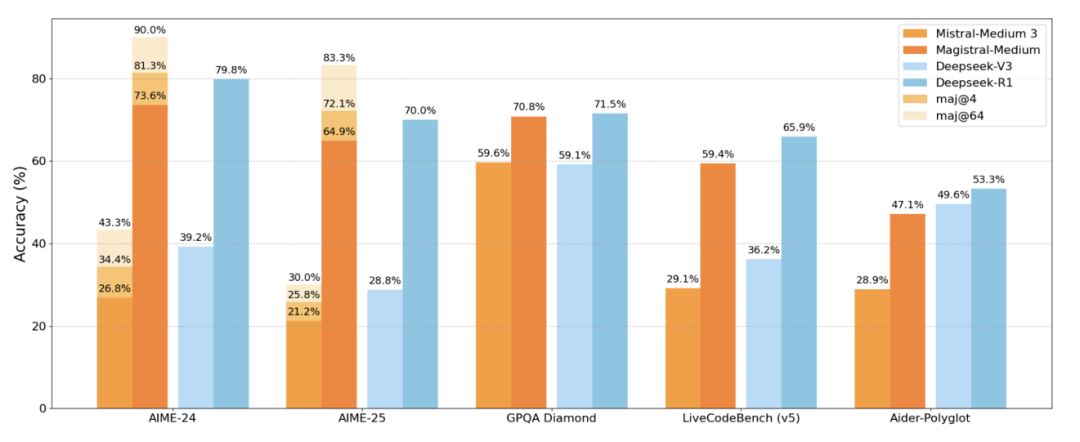
性能炸裂的实锤数据
-
推理能力:Magistral Medium在AIME数学竞赛题上73.6分(原模型仅26.8),超越DeepSeek-R1。 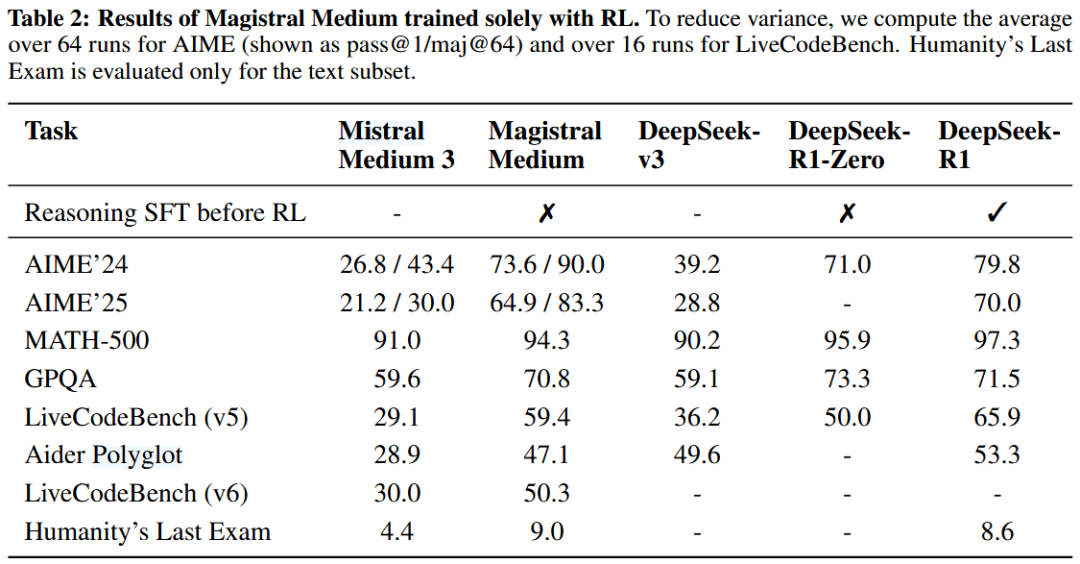
-
跨领域通吃:纯数学训练的模型,编程能力竟自动提升15.6%(反哺效应惊人)。 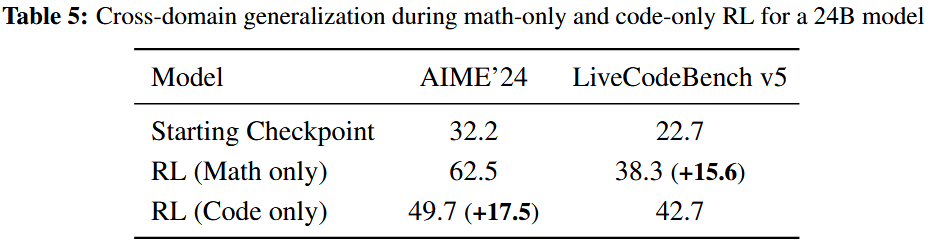
-
多语言环境下的推理能力:相较于英文版本,非英文版本上的表现下降了 4.3% 到 9.9% (中文63.7% vs 英语73.6%),但仍是突破! 
意外发现:多模态的“免费午餐”
最反直觉结论:纯文本训练竟提升图像理解力!
-
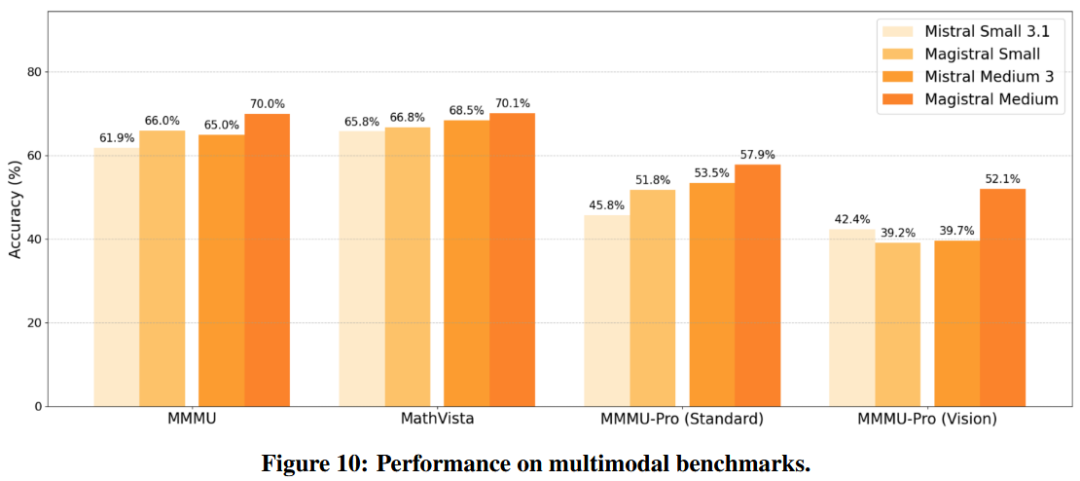
多模态基准MMMU-Pro视觉部分暴涨12% -
原理:文本推理的思维链能力迁移到图像问题(案例:光折射/化学键/植物病理分析)



开源小模型的逆袭
Magistral Small(24B参数)开源!
-
三步打造性价比之王:
1️⃣ 用Magistral Medium生成题库
2️⃣ 教给小模型(SFT蒸馏)
3️⃣ RL强化训练 -
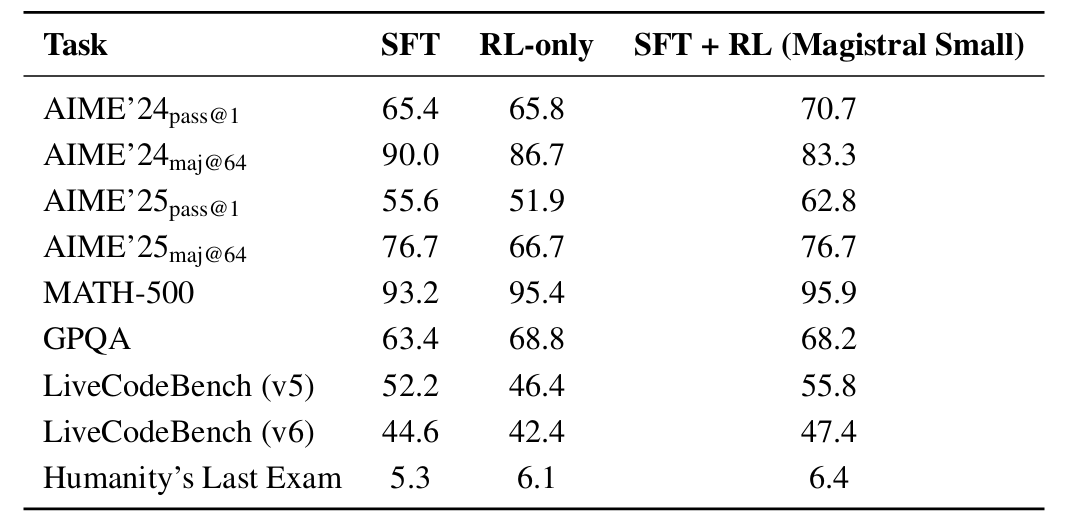
结果:小模型在多项基准逼平大模型,代码能力反超5.8%!
失败经验同样宝贵
-
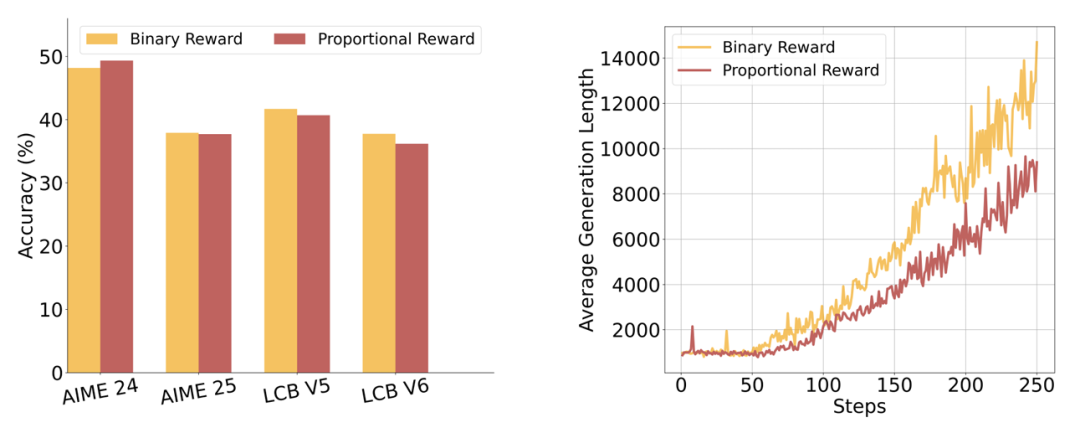
比例奖励陷阱:编程题按测试通过率给分 → 性能反降2%(模糊信号干扰学习) -
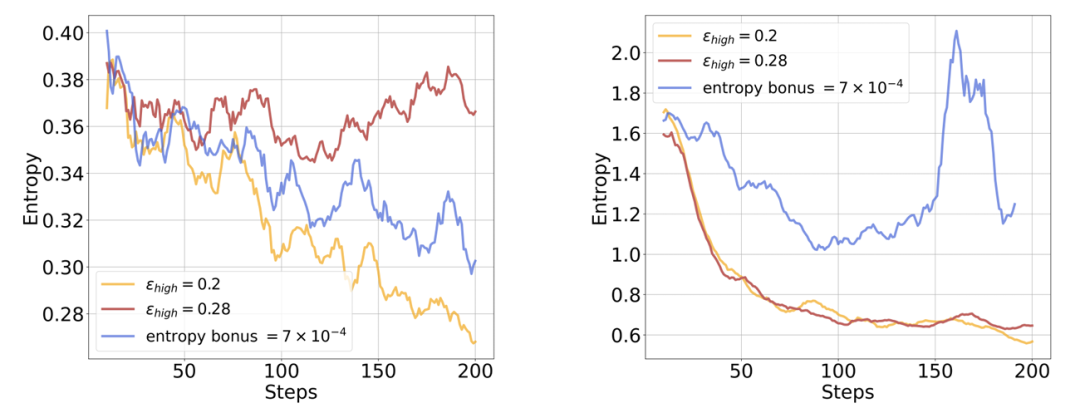
熵惩罚翻车:加熵鼓励探索 → 数学任务有效,编程任务熵值爆炸!
未来已来:RL的无限可能
Magistral证明:
-
工具调用能力未受损(87.4%→87.2%) -
自主刷题式训练将是下一代AGI核心路径 -
下一步:更大规模RL + 多模态代理 + 自我进化推理
(文:机器学习算法与自然语言处理)