

Yann LeCun的世界模型终于打脸质疑者!

Meta刚刚发布的V-JEPA 2不仅有高达10亿参数的版本,在某些基准测试上的推理速度还比英伟达Cosmos快了整整30倍,让质疑者们集体闭嘴。
这个基于Vision Transformer架构的世界模型,正是被称为「AI教父」的Yann LeCun倡导多年的JEPA(联合嵌入预测架构)路线的最新成果。只需要62小时的机器人数据训练,就能在完全陌生的环境中执行各种任务。
「反叛」终于有了答案
作为Meta首席AI科学家和图灵奖得主,Yann LeCun一直是AI界最「叛逆」的声音。当所有人都在追捧大语言模型时,他却公开唱反调。
在今年的英伟达GTC大会上,LeCun直接把LLM称为「token生成器」,并预言五年内没人会再用它们。
他在Newsweek的采访中更是语出惊人:
「如果我们能在三到五年内让这个工作起来,我们将拥有一个更好的范式,用于能够推理和规划的系统。」
他甚至建议年轻开发者:「别做LLM了。这些模型都在大公司手里,你没什么可贡献的。你应该研究下一代AI系统,克服LLM的局限性。」
网友们可没少嘲笑他。
在Hacker News上,有人毫不客气地指出:
「在这一点上,不管你对LLM有什么看法:总的来说,相信LeCun的话不是个好主意。再加上LeCun领导的AI实验室有以下巨大问题:1. 在拥有相似资源的大实验室中LLM最弱(而且比资源更少的实验室还弱:比如DeepSeek)」
但V-JEPA 2的发布,让这些质疑声音瞬间消失了。
20年磨一剑的世界模型
V-JEPA 2(Video Joint Embedding Predictive Architecture 2)是LeCun倡导的JEPA架构在视频领域的最新实现。
这不是心血来潮。
LeCun在Meta的博客中透露:「通过训练系统预测视频中将要发生的事情来理解世界如何运作的想法是非常古老的。我至少以某种形式研究了20年。」
o-mega.ai(@o_mega___)详细解释了V-JEPA 2的技术突破:
V-JEPA 2通过独特地结合超过一百万小时的在线视频和目标真实世界数据,实现了零样本机器人规划,让机器人能够在陌生情况下预测和行动,无需事先重新训练。它的联合嵌入预测架构现在可以在视频序列上训练,并在某些基准测试上产生比Nvidia Cosmos快30倍的推理速度——需要注意的是基准测试是任务相关的。
最少只需要几个小时的机器人交互数据就足以泛化技能,比如工具使用,这反映了其他模型很少见的「常识」适应能力,将机器人技术推向了新的效率前沿。
Vision Transformer的极致演绎
V-JEPA 2基于Vision Transformer架构,提供了多个模型规模:
-
ViT-L/16:3亿参数,256分辨率 -
ViT-H/16:6亿参数,256分辨率 -
ViT-g/16:10亿参数,256分辨率 -
ViT-g/16(384版):10亿参数,384分辨率
这种架构选择绝非偶然。与生成式方法不同,V-JEPA 2不在像素级别进行预测,而是在抽象表示空间中进行。

LeCun解释道:「与其预测视频中发生的所有事情,我们基本上是训练系统学习视频的表示,并在该表示空间中进行预测。这种表示消除了视频中许多不可预测或无法弄清楚的细节。」
碾压竞争对手的性能
V-JEPA 2在多个基准测试上都创造了新纪录:
视觉理解任务:
-
EK100(动作预测):39.7%,之前最佳仅为27.6%(PlausiVL) -
SSv2(视频理解):77.3%,超越了InternVideo2-1B的69.7% -
Diving48(动作识别):90.2%,超过InternVideo2-1B的86.4% -
MVP(视频问答):44.5%,超越InternVL-2.5的39.9% -
TempCompass(视频问答):76.9%,超过Tarsier 2的75.3%
机器人控制任务:
-
到达目标位置:100%成功率(Cosmos只有80%) -
抓取杯子:60%成功率(Octo 10%,Cosmos 0%) -
拾取并放置杯子:80%成功率(Octo 10%,Cosmos 0%) -
拾取并放置盒子:50%成功率(Octo 10%,Cosmos 0%)
两阶段训练的巧妙设计
V-JEPA 2采用了巧妙的两阶段训练方法:

第一阶段:自监督预训练
编码器和预测器通过自监督学习从海量视频数据中进行预训练。Meta使
用了掩码潜在特征预测目标,利用丰富的自然视频来引导物理世界的理解和预测。
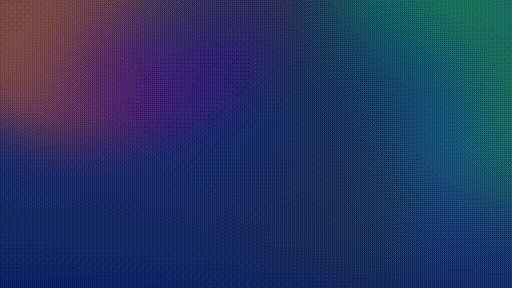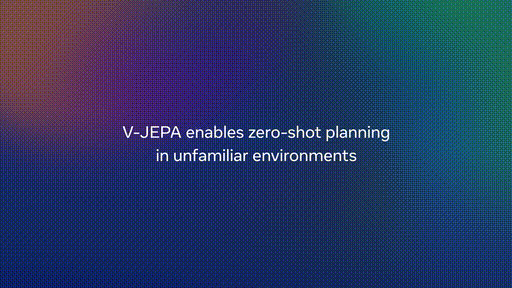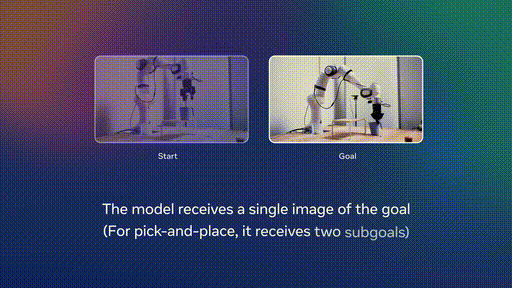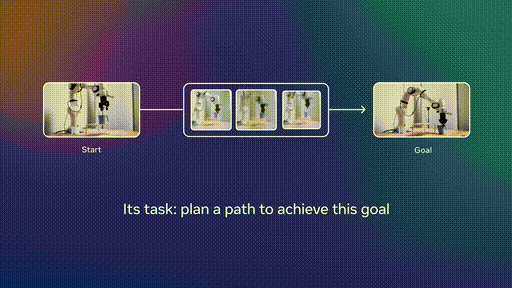
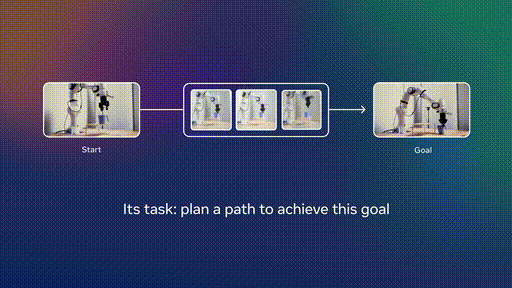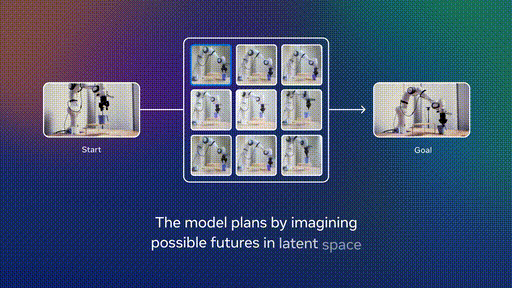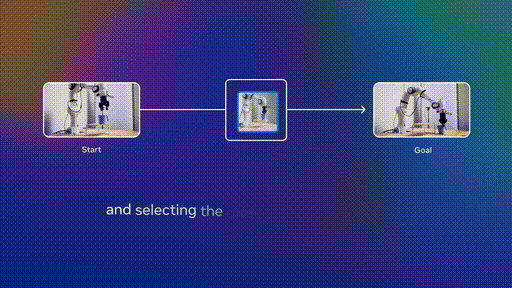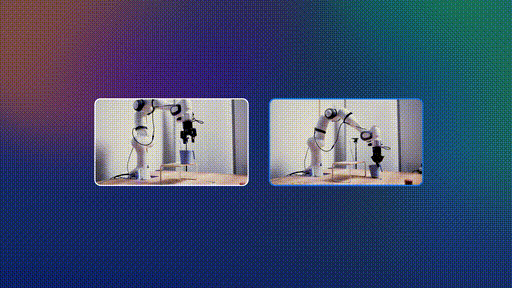
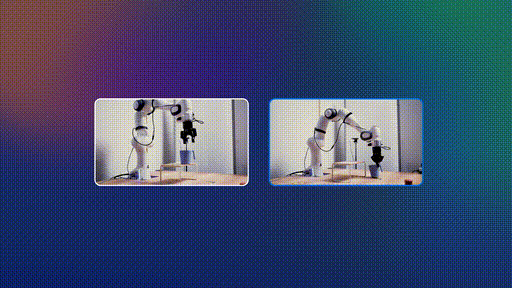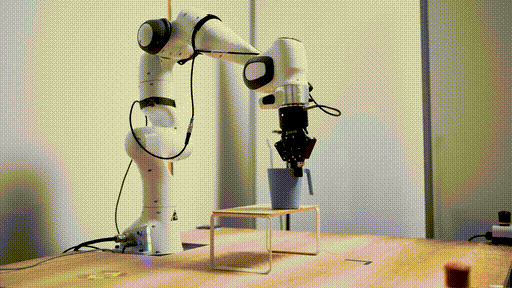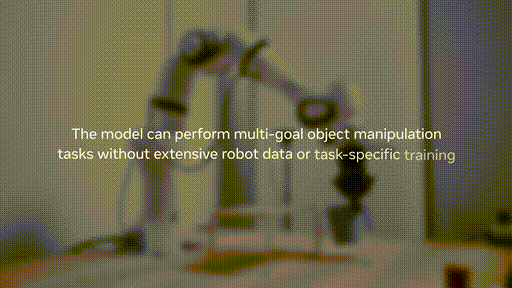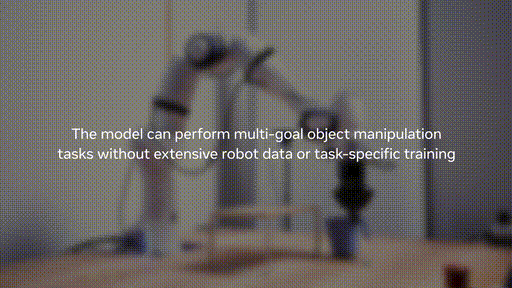
第二阶段:机器人数据微调
在少量机器人数据上进行微调,实现高效规划。这种方法的妙处在于,不需要收集大规模的专家机器人演示数据。
开发者可以通过多种方式使用V-JEPA 2:
import torch
# 预处理器
processor = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_preprocessor')
# 模型
vjepa2_vit_large = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_large')
vjepa2_vit_huge = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_huge')
vjepa2_vit_giant = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_giant')
社区热议
TuringPost(@TheTuringPost)激动地评论:
JEPA模型沉寂了很长时间,现在突然爆发!这是今天最好的消息👏
idk(@DataDon89382)感叹:
太棒了,我都不知道还有JEPA 1,但架构越多越好
但也有人提出了深刻的问题。Orbital Nymph(@GoddessAria94)询问:
进展令人印象深刻,但V-JEPA 2在陌生环境中规划时如何处理对齐和价值规范?这对安全部署似乎至关重要。
Anthony Harley(@anthony_harley1)则提出了一个有趣的挑战:
解决魔方应该成为这些世界/机器人模型的图灵测试。通用智能模型做到这个了吗?
Cloud Seeder(@cloudseedingtec)虽然对Meta有些成见,但也承认:
不错哈哈,我差点要问你们是否需要帮助,因为我对OpenAI太失望了,我需要美国有更多竞争对手,但我很抱歉我还是有点偏见……被Facebook搞得太惨了,所以我提供帮助是不负责任的,我会作弊的<3
打脸时刻
回想起之前对Yann LeCun的种种质疑,现在看来,或许都成了打脸时刻。
那些说他「不切实际」的人,那些嘲笑JEPA是「空中楼阁」的人,那些认为Meta在AI竞赛中落后的人,现在都沉默了。
V-JEPA 2的成功证明了LeCun的远见:真正的智能不是生成看起来合理的文本,而是理解和预测物理世界。
如LeCun所说:「每次试图通过训练系统在像素级别预测视频来理解世界或建立世界心智模型的尝试都失败了。」
但V-JEPA 2成功了,因为它选择了正确的道路——在抽象表示空间中进行预测。
AIMEME(@AI69ME)用诗意的方式总结:
V-JEPA 2:为机器人新世界重新定义视觉理解和预测。立即下载并革新你的研究。
Ghandeepan M(@ghandeepan_3789)简洁地说:
新的世界模型!!!!
GEMerald BTC(@GemeraldBTC)的评价虽然简短但中肯:
这相当不错
Yann LeCun用20年的坚持,证明了什么叫「时间会给出答案」。
V-JEPA 2 官方页面: https://ai.meta.com/vjepa/
[2]V-JEPA 2 研究论文: https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
[3]V-JEPA 2 GitHub 代码仓库: https://github.com/facebookresearch/vjepa2
[4]V-JEPA 2 HuggingFace 模型集合: https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6
[5]ViT-L/16 模型 (300M参数): https://dl.fbaipublicfiles.com/vjepa2/vitl.pt
[6]ViT-H/16 模型 (600M参数): https://dl.fbaipublicfiles.com/vjepa2/vith.pt
[7]ViT-g/16 模型 (1B参数): https://dl.fbaipublicfiles.com/vjepa2/vitg.pt
[8]ViT-g/16 384分辨率版本 (1B参数): https://dl.fbaipublicfiles.com/vjepa2/vitg-384.pt
[9]V-JEPA 2-AC 动作条件模型: https://dl.fbaipublicfiles.com/vjepa2/vjepa2-ac-vitg.pt
[10]SSv2 ViT-L/16 评估模型: https://dl.fbaipublicfiles.com/vjepa2/evals/ssv2-vitl-16x2x3.pt
[11]Diving48 ViT-L/16 评估模型: https://dl.fbaipublicfiles.com/vjepa2/evals/diving48-vitl-256.pt
[12]EK100 ViT-L/16 评估模型: https://dl.fbaipublicfiles.com/vjepa2/evals/ek100-vitl-256.pt
[13]Meta AI 博客:V-JEPA 2 世界模型和基准测试: https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks
[14]Yann LeCun 的 LinkedIn 帖子: https://www.linkedin.com/posts/yann-lecun_introducing-v-jepa-a-method-for-teaching-activity-7163961516650647552-w3yA
[15]V-JEPA 1 介绍: https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
(文:AGI Hunt)