


昨天,我们让国内的几个大模型做了今年的高考数学题(全国一卷),大家都很想看看国内和国外的大模型同台竞技,然后看看排行。

行,没问题,今天就多搞点大模型来对比。
但是这次我们就不测简单的题了,就专门测解答题,毕竟解答题是数学考试中最难的部分,也是分值最高的部分,同时也最考验模型的数学能力。
本次参考的大模型考生有:DeepSeek-R1(问小白版)、豆包Seed1.5、Qwen3、混元T1、Kimi K1.5、智谱Z1、跃问Step-R1、讯飞星火X1、GPT o4-mini、Gemini 2.5 pro(0605)、Claude 4、Grok3,全部为推理模型。
缺考考生依旧为DeepSeek官方版(不能上传图片)和文心X1-Turbo(上传图片必须打开联网功能)。

考试规则
考试规则基本还是昨天的规则,我也给大家放在下面,毕竟有很多朋友可能没看过昨天的贴。
以下是考试规则:
1.本次测试直接用图片输入,不改变题目内容,也不做任何Prompt引导。
2.本次题型全部为解答题,而且选择的是解道题的最后两道,没有什么别的意思,单纯是因为这两道最难。
3.解答题第一题有两个问,计40分(其中第二问中两个小问各计10分),解答题第二题有三个问,计60分,这样刚好是100分,答错一个小问扣20分。
4.各模型每题只跑一次,毕竟现实中,每位考生也只有一次的作答机会。
5.将超时问题加入评判标准,如果模型陷入无限循环则计为0分。
6.所有模型都选择推理模式,不开联网,不允许写代码沙盒计算(相当于带计算器)。

考试试题
本次考试共两题,都是解答题,选自全国卷一。
1)解答题一

2)解答题二


考试结果
1)解答题一
标准答案:
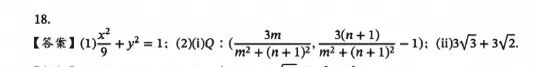
问小白版DeepSeek-R1,依旧做题做到一半就歇菜了,我估计是Token被限制了。

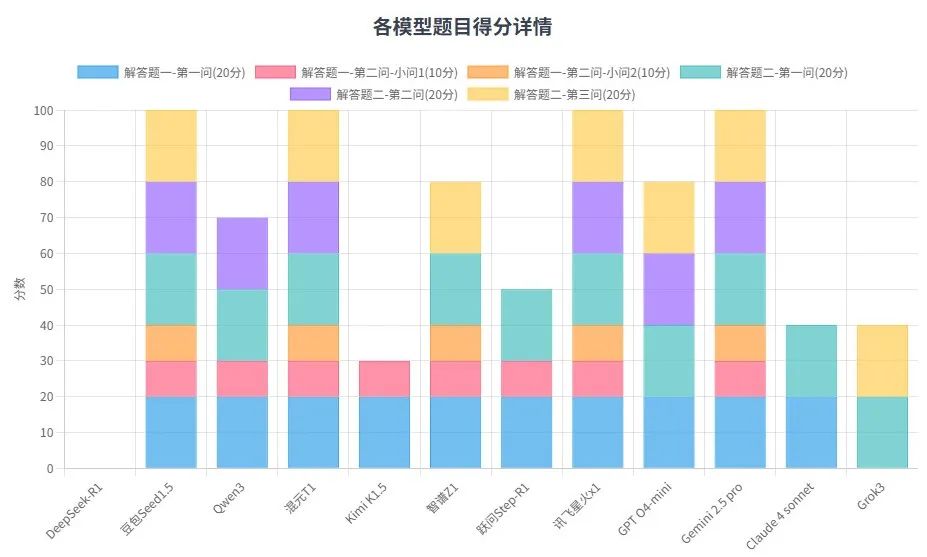
豆包Seed1.5全对。

Qwen3错了第二问的第二小问。

混元T1全对。

Kimi K1.5也是错了第二问的第二小问。

智谱Z1全对。

跃问Step-R1也是错了第二问的第二小问。

讯飞星火X1全对。

GPT o4-mini只答对了第一问,差点答对第二问的第一小问,只差一个正负号的差距。
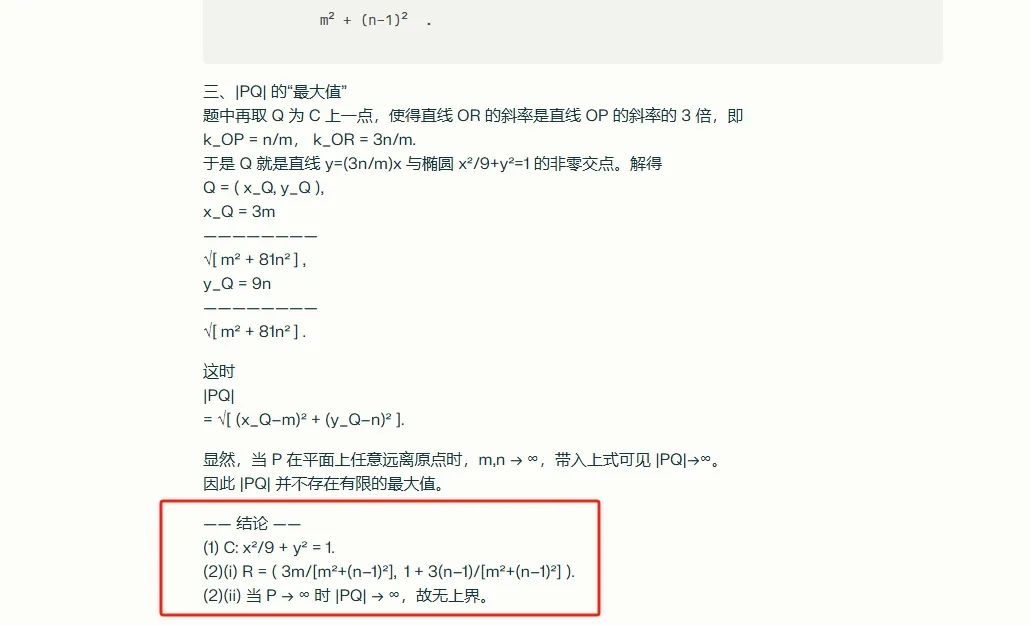
Gemini 2.5pro全对。



Claude 4 sonnet只答对了第一问。

Grok3不仅思考时三个问题就全做错了,回到答案时更是只回答了一个就停下了。

国内的,豆包Seed1.5、混元T1、智谱Z1、讯飞星火X1都是全对,国外只有Gemini全对。
国内还有三个同样只错了第二问的第二个小问的,要不是都算出来不一样,我都要判他们抄袭了。
2)解答题二
标准答案:

问小白版DeepSeek-R1还是做题做到一半又歇菜了,这给每个问题的Token也分配的太少了吧。

豆包Seed1.5全对。

Qwen3错了第三问。

混元T1全对。

Kimi K1.5又是做题做到一半就歇菜了,应该也是分配给每个问题的Token用完了。

智谱Z1错了第二问。

跃问Step-R1错了第二问和第三问。

讯飞星火X1全对。

GPT o4-mini全对。

Gemini 2.5 pro全对。

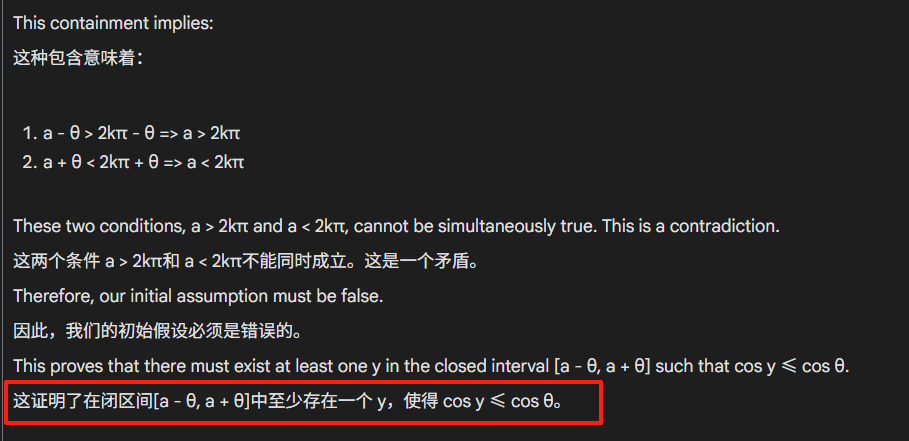
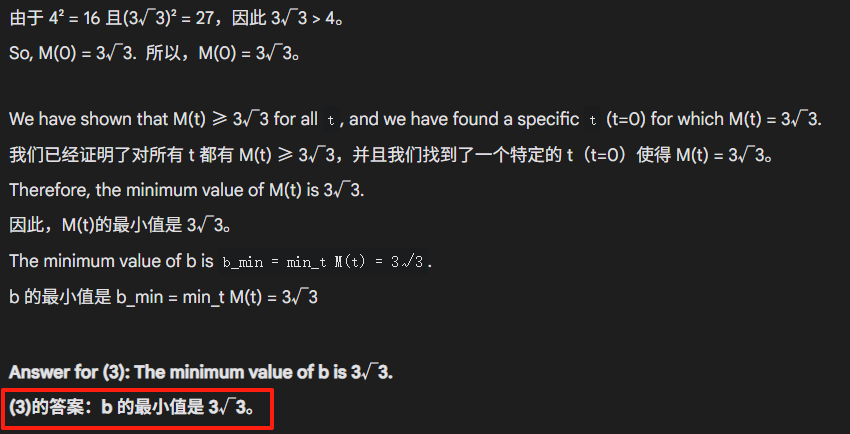
Claude 4 sonnet错了第二问和第三问。

Grok3错了第二问。

本题国内模型全对的有豆包Seed1.5、混元T1和讯飞星火X1,国外的GPT o4-mini和Gemini 2.5 pro也是全对,错的就五花八门了,一二三问都有模型出错。
最后统计下来,所有大模型的得分如下:
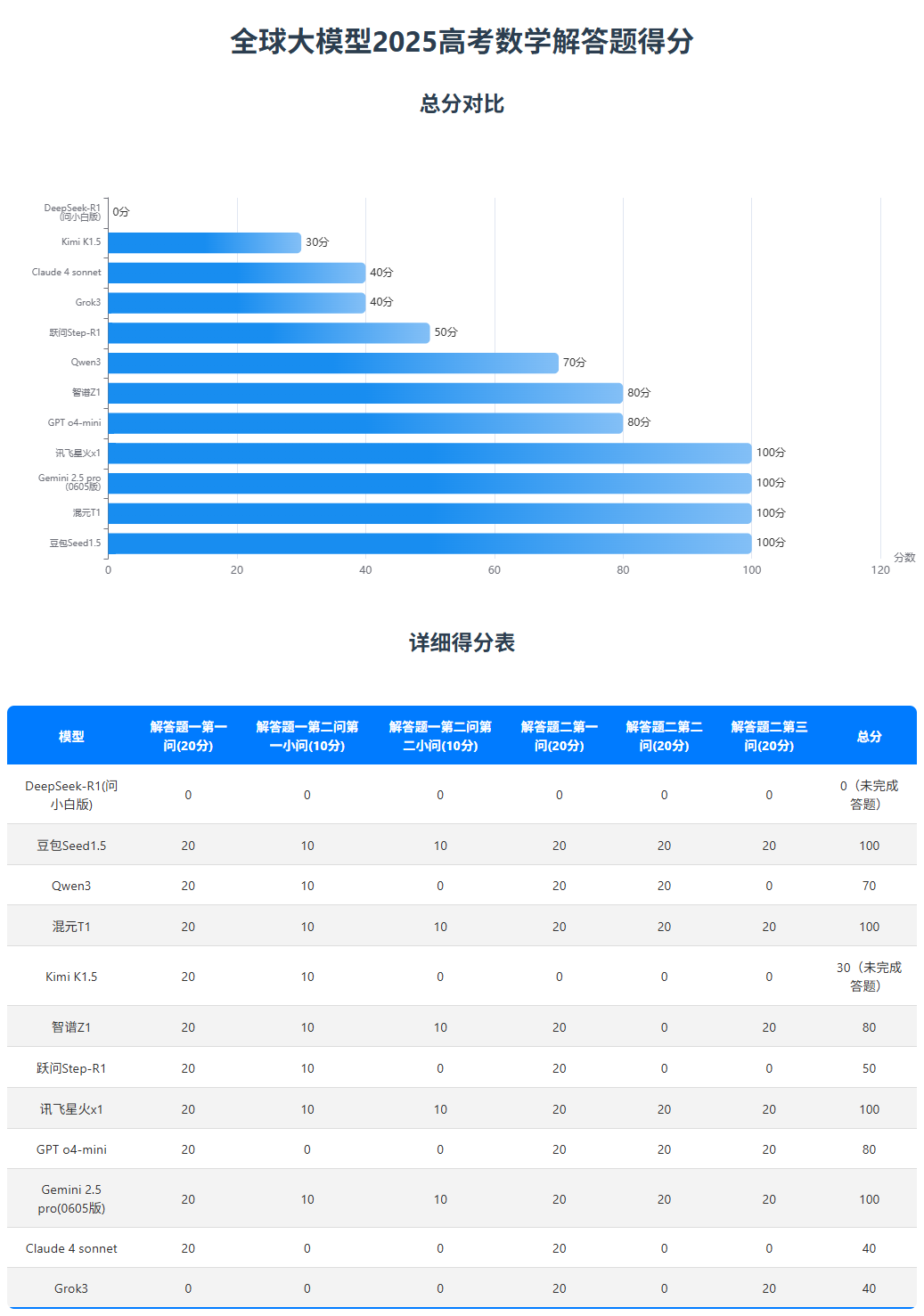

写在最后
看来做数学题这一方面,豆包Seed1.5、混元T1、讯飞星火x1和Gemini 2.5 pro确实是个中好手,一题没错拿了满分。
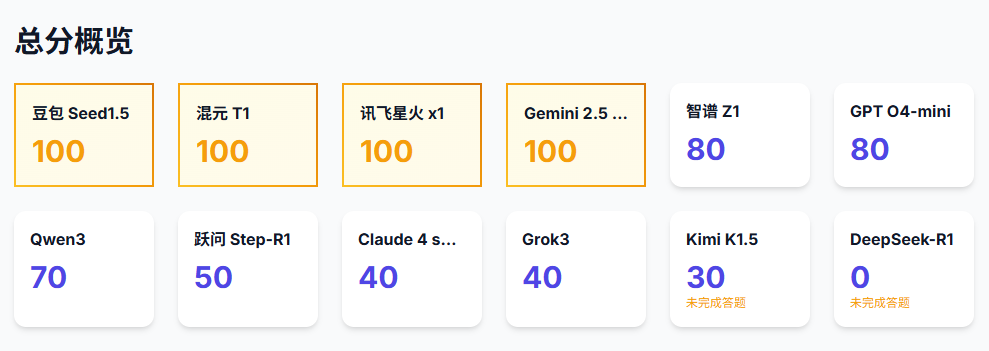
第二梯队则是智谱Z1和GPT o4-mini,都按到了80分这个优异的成绩。
第三梯队则是Qwen3,至少是达到及格分以上了。
第四梯队有Kimi K1.5、跃问Step-R1、Claude 4 sonnet和Grok 3,都没及格。
至于0分的DeepSeek,我相信这肯定不是它的真实实力,但是没办法,答题停止是测试中真实发生的情况,我也改变不了。
总的来说,国内国外都有有优秀的数学能力的大模型,但还是能够看出有些大模型的数学能力依然差了那么一截。最后我想吐槽的是,为什么DeepSeek和Kimi给定的Token连一道题都跑不完啊。
我希望明年再来一轮测试,以目前AI发展的速度,我估计到时候所有大模型做高考数学题都是没有难度的了。
最后的最后,我希望不要因为AI越来越牛使得我们失去创造力与学习能力,大家要永远走在学习的道路上,要永远保有一颗对未知事物的好奇心。
(文:沃垠AI)