

端侧长文本模型迎来了真正的革命性时刻。
面壁智能联合清华大学刚刚发布的MiniCPM 4.0,用一个让人难以置信的数字宣告了端侧长文本时代的到来:极限场景下220倍加速!

这不是简单的性能提升,而是从「龟速爬行」到「疾速飞驰」的质变。
作为一个只有一台4090、还要在上面部署一堆模型的GPU Poor,我从MiniCPM 2.5开始就一直混迹于官方群24群,并密切关注这个项目的每一次更新——各个量化版本我都详细测试过,就为了找到性价比最高的那个。

当时就有种预感:MiniCPM 会走出一条不同于其他大模型的路,而最有可能的就是端侧大模型。所以看到MiniCPM 4.0发布的那一刻,心里暗叹:
终于来了!
实测视频:220倍加速不是吹的
这个对比测试视频展示了三轮真实场景下的速度较量:
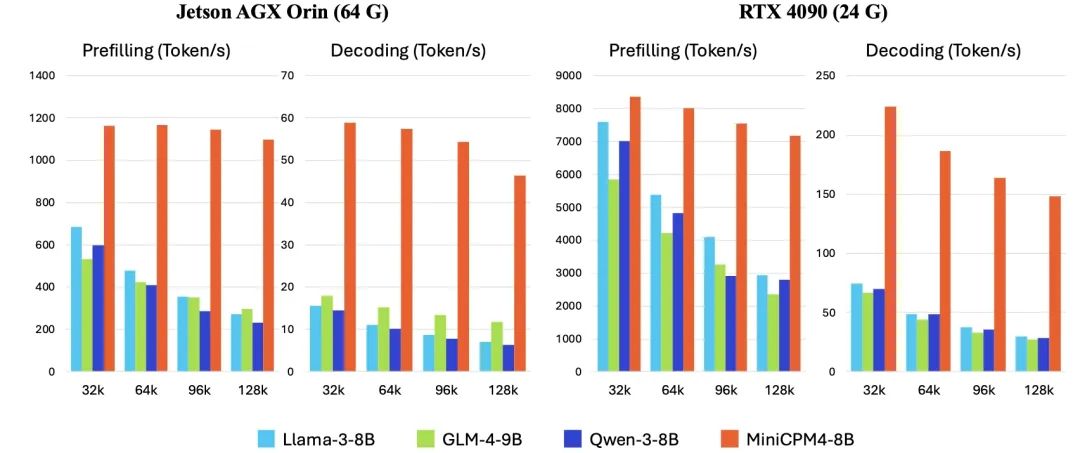
第一轮:140K+超长文本极限测试(RTX 4090显存不足场景)
-
预填充阶段:MiniCPM 4.0达到6288.81 tokens/s,Qwen3-8B仅348.29 tokens/s,快18倍 -
解码阶段:MiniCPM 4.0保持121.58 tokens/s,Qwen3-8B几乎卡死在0.55 tokens/s,快220倍
第二轮:128K长文本常规场景(RTX 4090)
-
预填充:6365.62 vs 2745.69 tokens/s,快2倍 -
解码:126.38 vs 29.32 tokens/s,快4倍
第三轮:边缘设备测试(Jetson AGX Orin)
-
预填充:961.54 vs 235.86 tokens/s,快4倍 -
解码:39.07 vs 6.82 tokens/s,快6倍
国外网友们又双叒叕沸腾了
OpenBMB(@OpenBMB) 发布消息后,国外网友们又是瞬间沸腾:
Xeophon(@TheXeophon) 直接送上祝贺:
恭喜!!!
Secret AI(@SecretAILabs) 最关心实用性:
太棒了!!!GGUF格式什么时候发布?
elie(@eliebakouch) 来自Hugging Face的认可:
令人印象深刻!🚀

而网友Tsukuyomi(@doomgpt) 则忍不住调侃:
5倍速?看来我们离AI跑马拉松只有一步之遥了。只希望它不要在这个过程中超越我们。
技术揭秘:原生稀疏的威力
MiniCPM 4.0最核心的创新在于首个原生稀疏模型的发布。
这是一次从架构到系统的全方位革新:
InfLLM v2:重新定义注意力机制

传统Transformer需要每个词元都和序列中所有词元进行相关性计算,计算复杂度是O(n²)。而InfLLM v2通过创新的分块注意力机制,实现了惊人的5%稀疏度:
-
智能分块:将上下文按64个token一组进行分块 -
语义核选择:每个查询只选择Top-64个最相关的块进行计算 -
双频换挡:短文本(<8192 tokens)用稠密注意力,长文本自动切换到稀疏模式
相比DeepSeek的NSA架构,InfLLM v2的上下文选择计算开销降低60%,且不增加额外参数。
CPM.cu:面壁自研的端侧推理利器

CPM.cu不是又一个推理框架,而是专为端侧极致优化的CUDA推理引擎。
与vLLM、TensorRT-LLM等通用框架不同,CPM.cu从设计之初就瞄准了端侧场景的痛点:
独特优势:
-
原生稀疏支持:业界首个完整支持InfLLM v2稀疏注意力的推理框架,稀疏算子性能比通用实现快3倍
-
极致内存优化:静态内存池管理,零拷贝推理,显存占用降低40%
-
投机采样融合:将FR-Spec投机采样深度集成,不是简单调用,而是算子级融合
-
量化推理一体:原生支持BitCPM的1.58bit三值量化,无需转换即可推理
这就是为什么在极限测试中,同样的硬件,CPM.cu能让MiniCPM 4.0达到220倍加速的秘密。
三级火箭推理加速体系

第一级:FR-Spec投机采样
-
创新词表剪枝策略,草稿模型专注高频词汇
-
语言模型输出头计算开销降低75%
-
整体推理速度提升2倍以上
第二级:BitCPM极致量化
-
业界首个1.58bit三值量化方案
-
模型瘦身90%,性能保持率超过85%
-
在0.5B规模上,性能竟然超越Qwen3-0.6B全精度模型
第三级:系统级优化
-
算子融合:注意力计算、激活函数、归一化层深度融合
-
访存优化:利用共享内存和寄存器,减少全局内存访问
-
动态批处理:自适应调整batch size,最大化GPU利用率
性能炸裂:小参数大能力
基准测试全面碾压
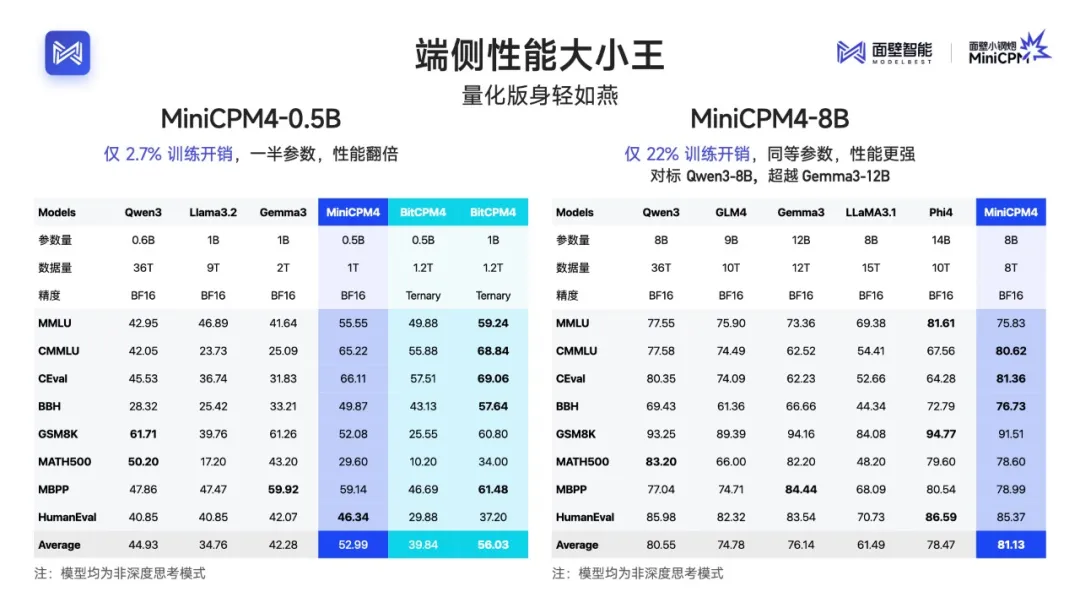
MiniCPM4-8B性能数据:
-
MMLU:75.83(超越GLM4-9B的75.90)
-
CMMLU:80.62(中文理解能力冠绝群雄)
-
CEval:81.36(再次证明中文实力)
-
BBH:76.73(推理能力比肩Phi4-14B)
-
GSM8K:91.51(数学能力接近GPT-4水平)
-
HumanEval:85.37(代码生成超越Gemma3-12B)
训练效率对比:
-
Qwen3-8B:36T tokens训练数据
-
MiniCPM4-8B:仅8T tokens,效率提升4.5倍
长文本能力:真正的杀手锏
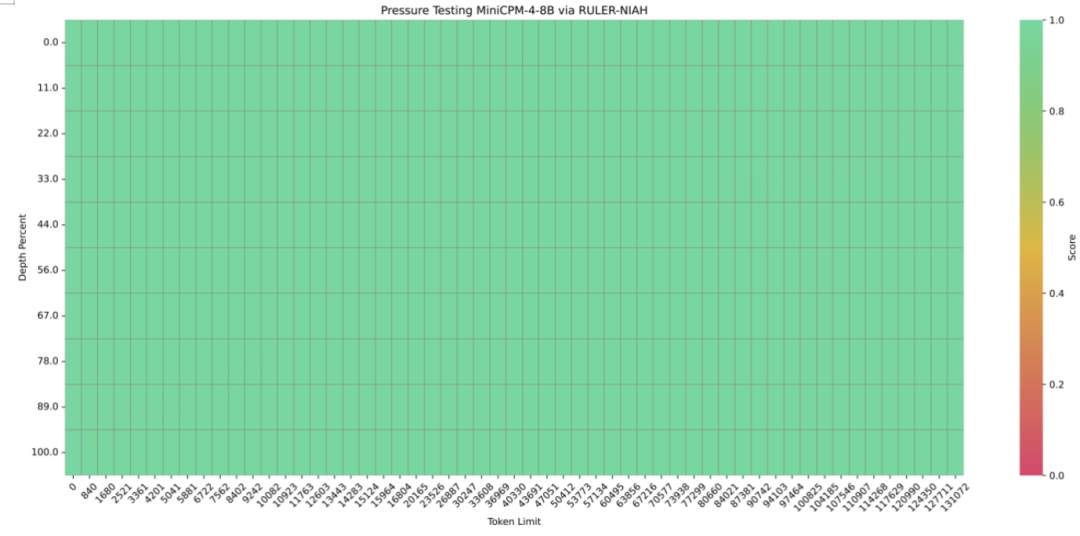
-
原生支持32K上下文
-
通过YaRN扩展至128K,准确率100%
-
128K场景下,缓存占用仅为Qwen3-8B的1/4
-
配合LLMxMapReduce,理论上可处理无限长度文本
落地部署:触手可及的AI
全平台适配
MiniCPM 4.0已完成主流芯片适配:
-
移动端:高通骁龙、联发科天玑、苹果M系列
-
PC端:Intel、AMD、NVIDIA全系列
-
国产芯片:华为昇腾、寒武纪等
三分钟快速部署
方式一:CPM.cu(推荐,享受完整加速)
git clone https://github.com/OpenBMB/CPM.cu.git --recursive
cd CPM.cu
python3 setup.py install
# 测试长文本推理
python3 tests/long_prompt_gen.py
python3 tests/test_generate.py --prompt-file prompt.txt
方式二:HuggingFace(最简单)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model = AutoModelForCausalLM.from_pretrained(
'openbmb/MiniCPM4-8B',
torch_dtype=torch.bfloat16,
device_map='cuda',
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM4-8B')
# 启用InfLLM v2稀疏注意力
model.config.sparse_config = {
"topk": 64,
"block_size": 64,
"dense_len": 8192
}
应用爆发:不只是聊天机器人
MiniCPM4-Survey:AI 科研助手
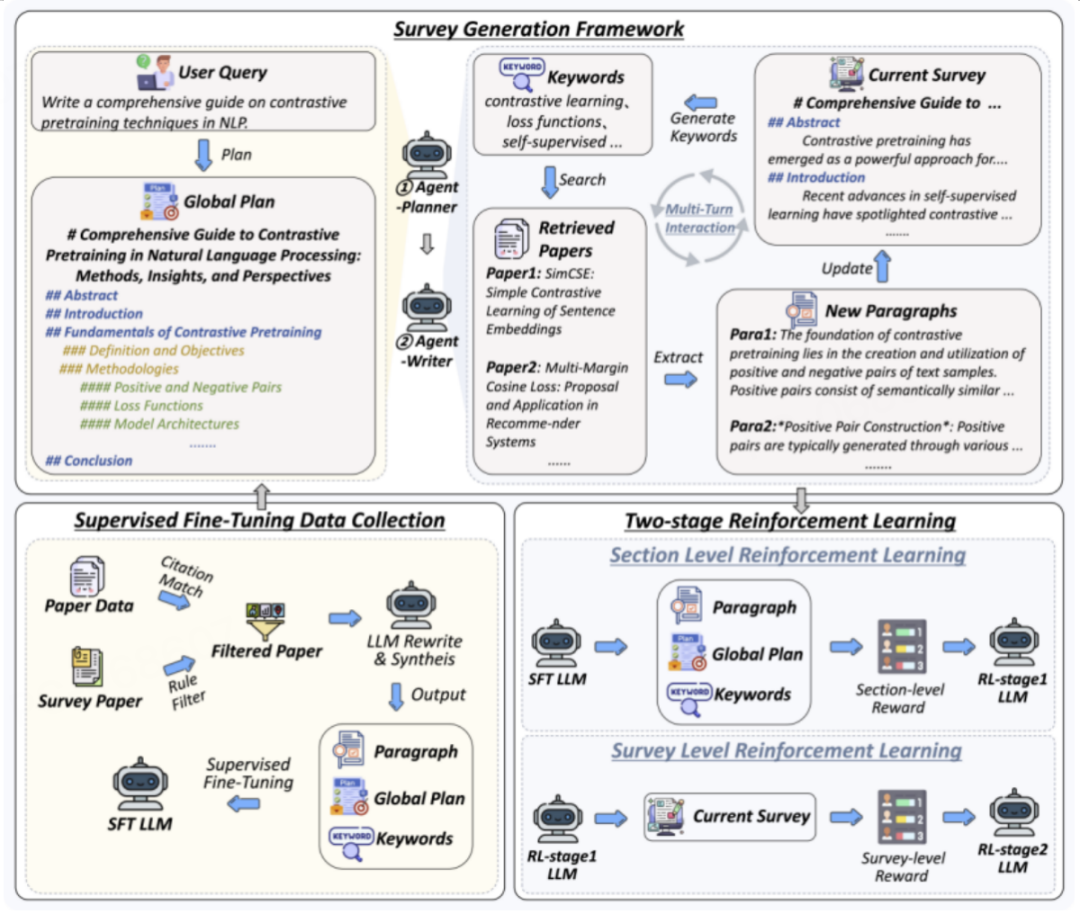
-
自主生成高质量综述论文
-
FactScore评分68.73,所有系统最高
-
性能与OpenAI Deep Research持平
-
完全本地运行,数据不出端
MiniCPM4-MCP:万能工具调用
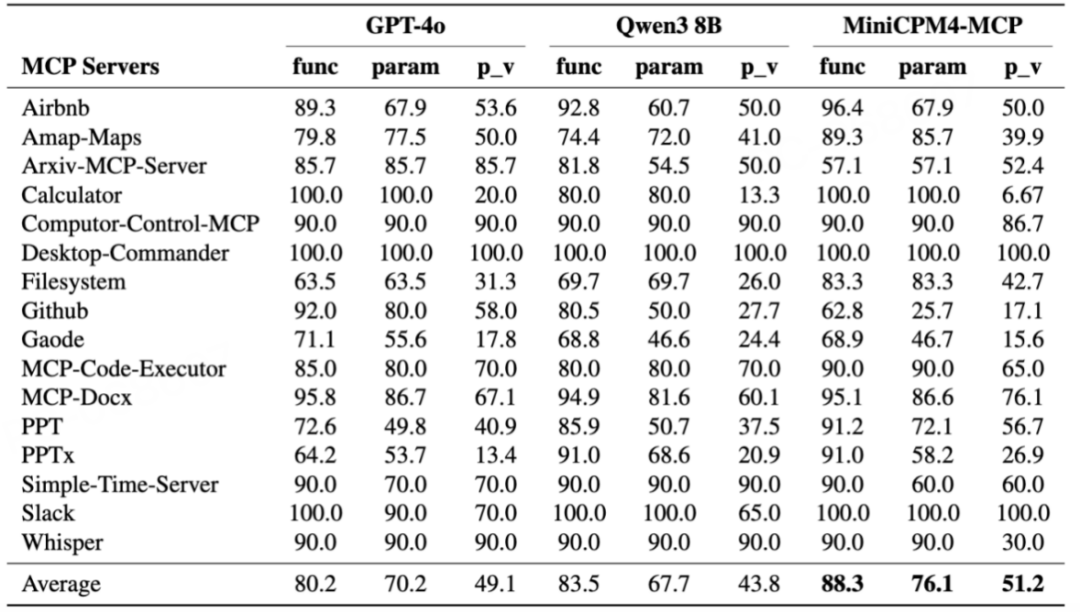
在Berkeley Function Calling排行榜上:
-
总体准确率:76.03%
-
超越Llama3.1-8B(73.28%)
-
碾压Phi-3.5-mini(48.44%)
-
支持15个MCP服务器,覆盖办公、生活、通讯全场景

行业格局:端侧AI的分水岭
曾经风光无限的「AI六小龙」格局已变。
零一万物将大模型交给阿里训练,明确不再追逐AGI,放弃预训练转向应用。「大家都看得很清楚,只有大厂能够烧超大模型。」李开复在接受采访时这样表示。
百川智能则专注医疗垂类赛道,在字节、阿里、腾讯等大厂争相上新基础模型时,其基础大模型进入了静默期。
剩下的智谱AI、MiniMax、月之暗面和阶跃星辰,虽仍在坚守,但在DeepSeek 冲击之下,或已难复当年勇纷纷寻找新的垂直出路——曾经的AI六小龙,已经在新一轮大模型竞赛中滑落成了新的「AI 四小强」。
而在这个格局剧变的时刻,面壁智能选择了一条完全不同的道路。
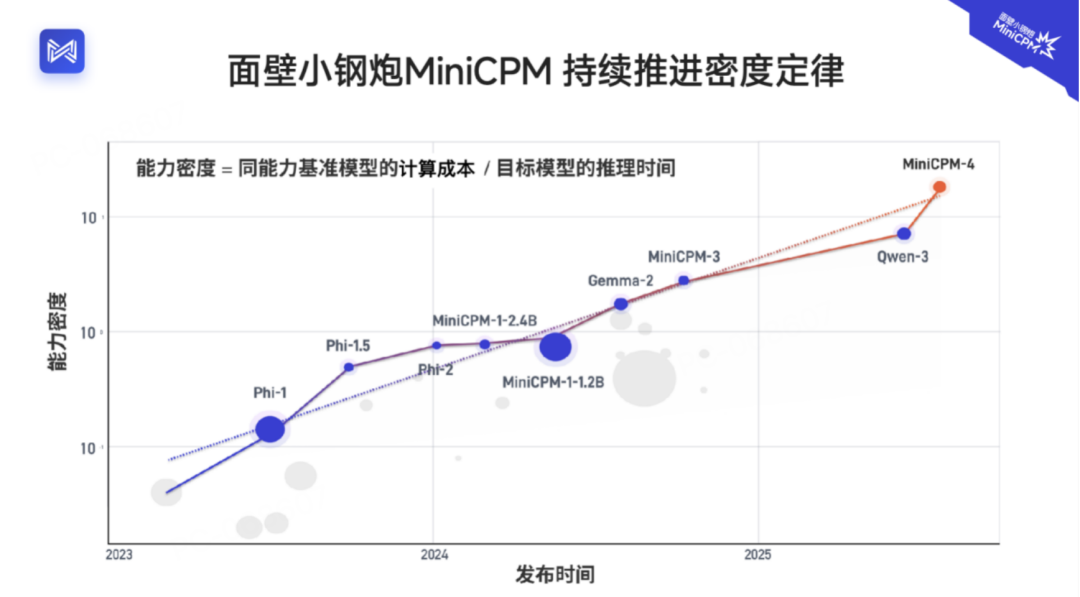
不在云端烧钱拼参数,而是用系统级创新在端侧实现极致效率。继DeepSeek在云端证明稀疏模型的成本效益后,面壁在端侧将「高效」路线推向了新的高峰。
从UltraClean数据筛选到ModelTunnel 2.0训练优化,从InfLLM v2架构创新到BitCPM极致量化,再到CPM.cu推理框架的自研突破,这是一整套端侧AI的方法论。

当别人还在比拼参数规模时,面壁已经在思考如何让AI真正走进每个人的设备。
端侧长文本时代,不是将要来,而是已经来了。
当你的手机能在几秒内处理十万字的文档,当AI助手可以完全离线理解你的所有聊天记录,当隐私和效率不再是选择题——这就是MiniCPM 4.0带来的新世界。
端侧模型的比赛,结束了!
相关链接
GitHub仓库: https://github.com/OpenBMB/MiniCPM
[2]技术报告: https://github.com/OpenBMB/MiniCPM/blob/main/report/MiniCPM_4_Technical_Report.pdf
[3]CPM.cu推理框架: https://github.com/OpenBMB/CPM.cu
[4]Hugging Face模型集合: https://huggingface.co/collections/openbmb/minicpm-4-6841ab29d180257e940baa9b
[5]ModelScope模型集合: https://www.modelscope.cn/collections/MiniCPM-4-ec015560e8c84d
[6]MiniCPM4-8B (HF): https://huggingface.co/openbmb/MiniCPM4-8B
[7]MiniCPM4-0.5B (HF): https://huggingface.co/openbmb/MiniCPM4-0.5B
[8]MiniCPM4-Survey: https://huggingface.co/openbmb/MiniCPM4-Survey
[9]MiniCPM4-MCP: https://huggingface.co/openbmb/MiniCPM4-MCP
[10]InfLLM v2稀疏注意力实现: https://github.com/OpenBMB/infllmv2_cuda_impl
[11]UltraFineWeb数据集: https://huggingface.co/datasets/openbmb/Ultra-FineWeb
[12]LLMxMapReduce: https://github.com/thunlp/LLMxMapReduce
[13]MiniCPM技术博客: https://openbmb.vercel.app/?category=Chinese+Blog
[14]MiniCPM知识库: https://modelbest.feishu.cn/wiki/D2tFw8Pcsi5CIzkaHNacLK64npg
[15]Discord社区: https://discord.gg/3cGQn9b3YM
[16]发布推特: https://twitter.com/OpenBMB/status/1930983161577754747
(文:AGI Hunt)