

想象你要指挥一个机器人点击手机上的“购物车”图标。传统Agent怎么做?它会像报经纬度一样输出:x=0.345, y=0.721。这带来三大问题:
-
定位死板:按钮内任意位置都能点,AI偏要死磕一个点; -
缺乏空间感:AI靠猜数字而非“看懂”界面; -
兼容性差:换个屏幕尺寸就懵圈。
就像让人用坐标点外卖,不如直接说“第三排第二个”直观!

论文:GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents
链接:https://arxiv.org/pdf/2506.03143
革命:GUI-Actor的“无坐标交互”
微软团队从人类行为获得灵感——我们从不计算坐标,而是用眼睛锁定目标后直接点!于是他们打造了GUI-Actor:
关键技术 1:<ACTOR>令牌——AI的“虚拟手指”
-
在指令中加入特殊标记 <ACTOR> (例:“点击 <ACTOR> 购物车图标”); -
AI用注意力机制将 <ACTOR> 与屏幕图像区块关联,自动锁定目标区域。
相当于给AI装了个“激光笔”,指哪打哪!
关键技术 2:多区块监督——容忍合理误差
-
传统方法:只认1个坐标点,偏移就判错; -
GUI-Actor:把按钮覆盖的所有图像区块(约28×28像素)都视为正确目标。
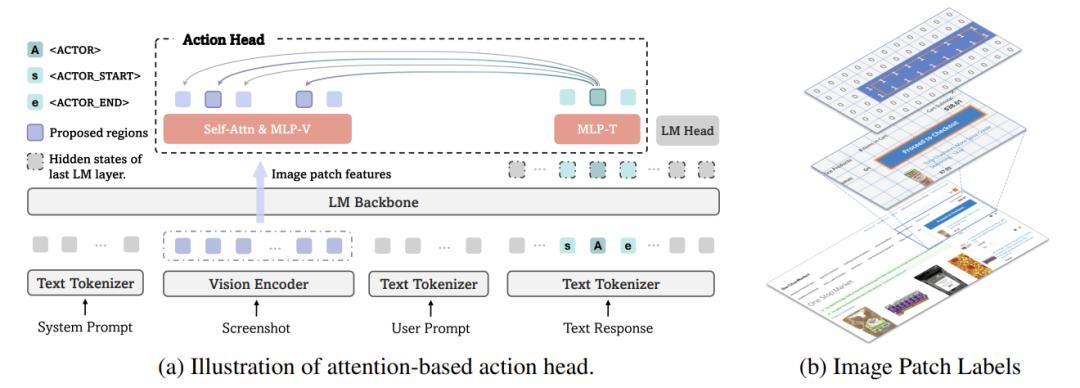
就像教孩子点按钮:“这一片都能点,不用非戳中心!”
关键技术 3:验证器——AI的“二次确认”
-
从注意力图中选多个候选区(如高亮区域); -
轻量验证器快速判断哪个最符合指令。
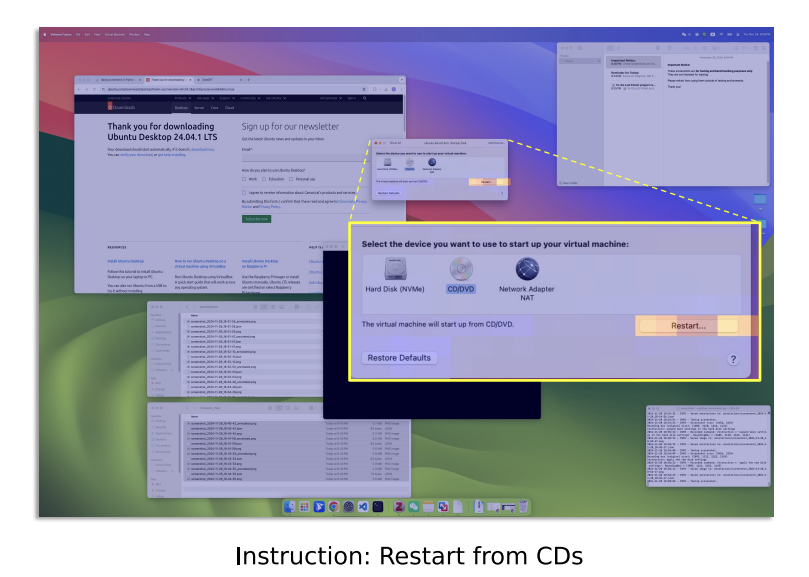
类似人类点按钮前扫一眼:“嗯,这个图标长得像购物车!”
实验:小模型暴打巨头
在三大权威测试集上,GUI-Actor全面碾压前SoTA:
-
ScreenSpot-Pro(高难度专业软件测试): -
7B参数模型 44.6分 vs 前冠军72B模型 38.1分 -
少90%参数,性能反超17% ! 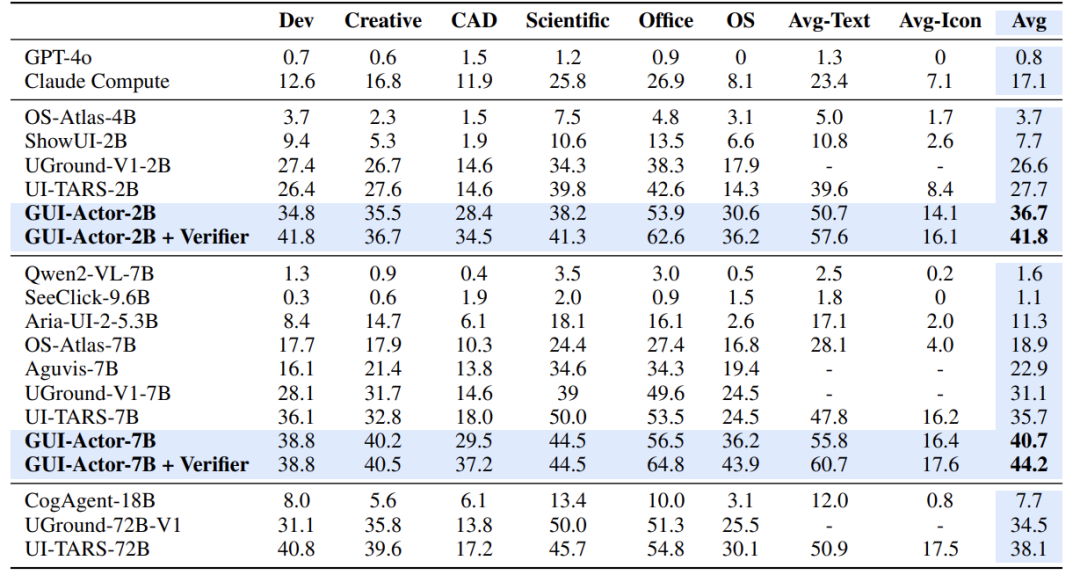
-
跨平台泛化能力: -
面对陌生分辨率/布局,GUI-Actor波动更小(传统模型早衰明显),下图c。 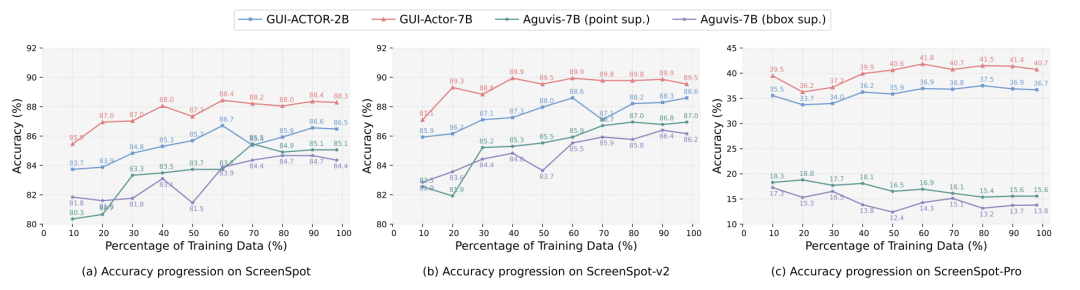
省钱!少数据、低算力友好
-
训练数据省60% :仅用60%数据达到传统模型100%数据的效果; -
冻结大模型:只微调新增的1亿参数(7B模型仅动1.4%参数),性能媲美全调优模型; 
-
推理零额外成本:一次前向传播生成多候选区,无需重复计算。
未来:AI助理的“人机交互革命”
-
手机助手:说“清空后台”自动关APP; -
自动化办公:口头指令操作Excel/PS; -
无障碍技术:视障用户语音操控界面。
试想未来:对着电脑喊“帮我P掉照片路人”,AI直接鼠标咔咔操作!
(文:机器学习算法与自然语言处理)