

AI 圈的内卷速度,比夏天升温还快。
大家还在讨论 GPT-4o 的丝滑体验,谷歌这边又悄悄放了个大招。就在昨天,谷歌 CEO Sundar Pichai 亲自发文,宣布 Gemini 2.5 Pro 迎来又一次重磅更新!
如果你还记得,上个版本是 gemini-2.5-pro-preview-05-06。
你再看这个新版本:gemini-2.5-pro-preview-06-05。
这命名方式,简直就是把”月度更新”写在了脸上。谷歌现在不仅要用技术碾压,还要用更新频率告诉所有人:我,Gemini,每个月都比上个月更强。

这次升级的核心看点是什么?简单来说:全面变强,尤其是在代码能力上,直接超越了老对手 Claude 4。
王者归来,重夺性能榜第一
我们先看最直观的证据。
在 AI 模型界”天梯榜”之称的 LMArena.ai 盲测竞技场上,最新的 Gemini 2.5 Pro (06-05) 版本,以 1470 分的 Elo 成绩,再次登顶,重回第一的宝座!
LMArena 官方也发文庆贺,称其为”新的王者”,在文本、视觉、网络开发、硬核问答、编码、数学等几乎所有类别中都名列第一。

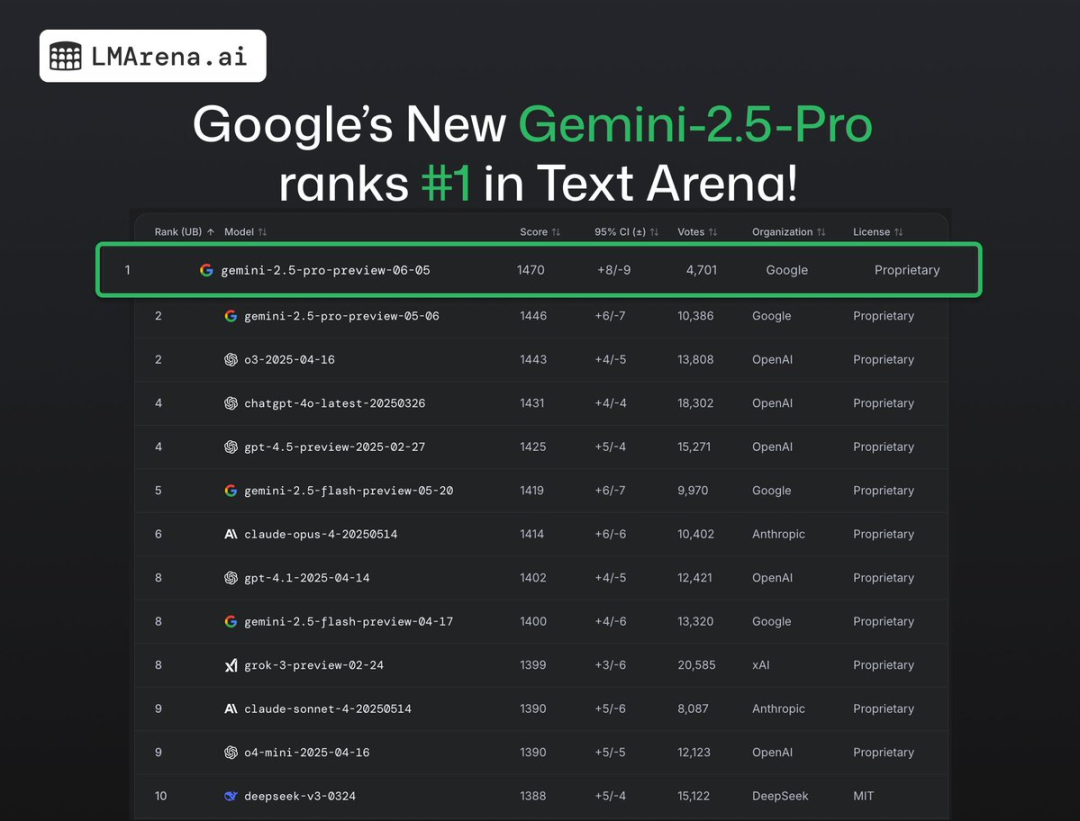
Gemini 2.5 Pro 的综合表现已经超过了包括 GPT-4o、Claude Opus 在内的所有对手。
代码能力,硬刚 Claude 4 并胜出
一直以来,Anthropic 的 Claude 模型都以其强大的代码和长文本处理能力著称。但这一次,谷歌用数据给出了正面回应。
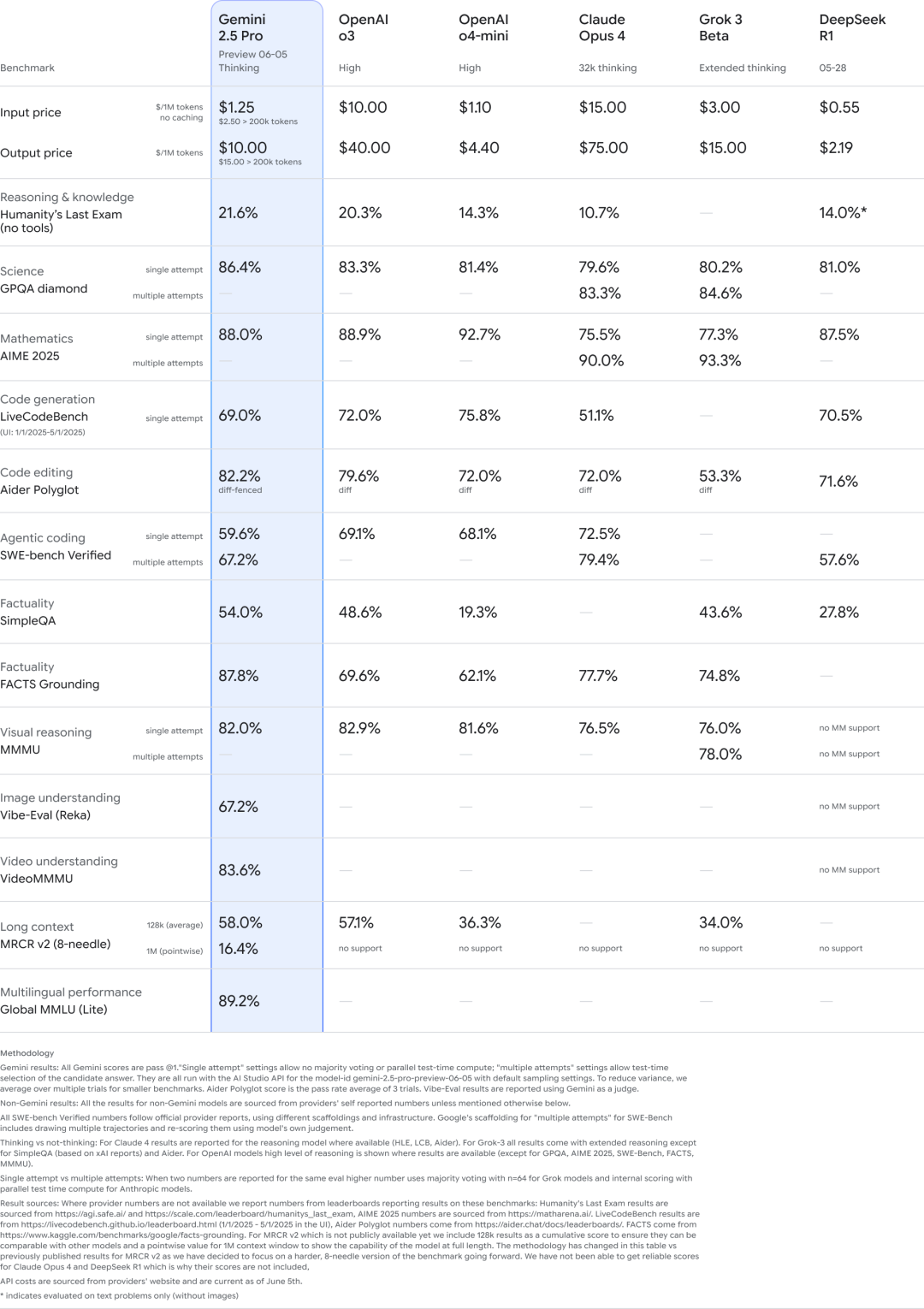
在专门衡量 AI 模型编程能力的权威测试集 Aider Polyglot 上,Gemini 2.5 Pro 的得分高达 82.2%,而 Claude Opus 4 的得分是 72.0%。
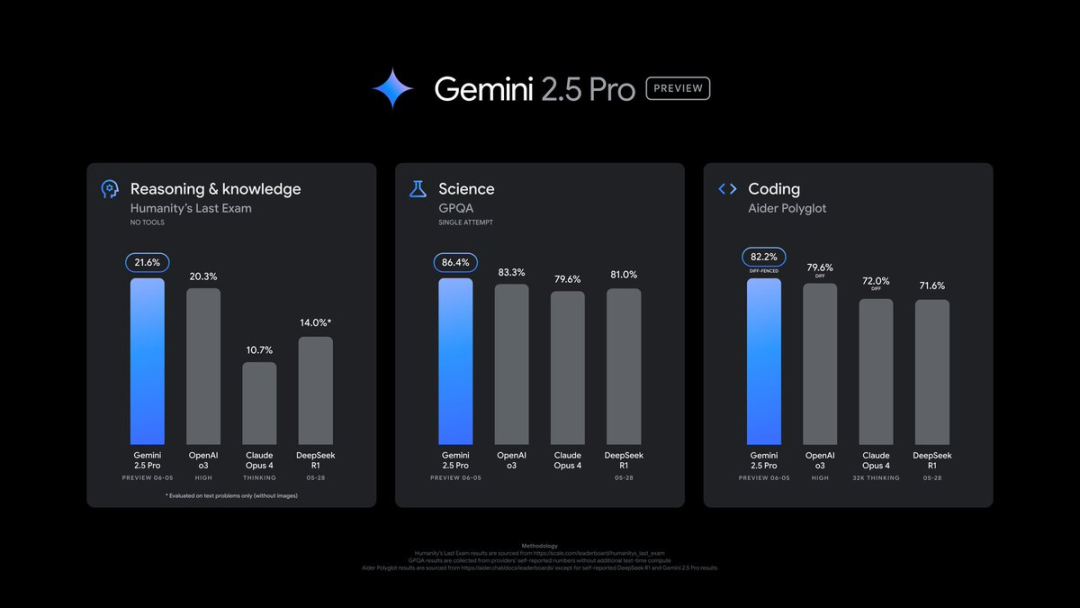
领先整整 10 个百分点,这是一个巨大的优势。
它说明在处理复杂编程任务时,Gemini 2.5 Pro 的准确性和可靠性已经甩开了身后的追赶者。对于开发者来说,这意味着更强的生产力工具。
不止代码,是全方位的”六边形战士”
除了代码能力的巨大飞跃,Gemini 2.5 Pro 在其他领域的表现同样顶级。
-
• 科学能力 (GPQA 测试): 得分 86.4%,领先于 OpenAI o3 和 Claude Opus 4。 -
• 推理和知识 (Humanity’s Last Exam 测试): 得分 21.6%,同样名列前茅。
谷歌在官方博客中提到,这次更新还听取了用户的反馈,改进了模型的写作风格和回答结构,让它的回复更有创造力,格式也更美观。
简单来说,Gemini 2.5 Pro 不再是一个”偏科生”,而是一个在编码、推理、多模态理解等各方面都表现出色的”六边形战士”。
如何体验?
目前,最新的 Gemini 2.5 Pro 预览版已经可以通过 Google AI Studio 和 Vertex AI 使用。同时,它也正在向 Gemini app (原 Bard) 推送。
在 Google AI Studio 上体验:https://aistudio.google.com/prompts/new_chat
谷歌表示,这个版本将在几周后成为正式版,为企业级规模的应用做好准备。
AI 的军备竞赛已经进入白热化。谷歌用每月一次的迭代速度,不断给市场带来惊喜 (和惊吓)。
这次 Gemini 2.5 Pro 的强势回归,无疑又给 OpenAI 和 Anthropic 带来了巨大的压力。
参考资料:
-
• https://blog.google/products/gemini/gemini-2-5-pro-latest-preview/ -
• https://x.com/GoogleDeepMind/status/1930656243346976925 -
• https://x.com/lmarena_ai/status/1930658518560133435 -
• https://x.com/sundarpichai/status/1930656033237823862
(文:AI智见录)