
在数字化时代,文档处理是企业和开发者日常工作中不可避免的挑战。Word、PDF、扫描件、Excel表格等格式繁多,整理为统一格式耗时费力。
今天给大家推荐一款 ISPRAS 团队开源的全能型文档提取与转换工具:Dedoc。

Dedoc凭借先进的机器学习和OCR技术,不仅能处理Office文档,还能从PDF、扫描件中智能提取表格、文本格式和逻辑结构,堪称文档处理领域的“瑞士军刀”。
支持将任意文档自动转为统一结构化 JSON 格式,方便二次处理、索引、摘要、问答等场景。
核心功能亮点
-
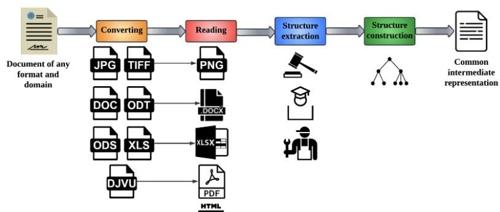
• 多文档格式支持:解析DOC/DOCX、PPTX、PDF、Excel、CSV、TXT、PNG/JPG、HTML等,覆盖90%+文档场景。 -
• 文档逻辑结构提取:自动识别标题层级、嵌套列表。 -
• 复杂表格解析:智能识别和提取表格数据,支持复杂多页表格。 -
• OCR扫描件处理:Tesseract 5.0+图像预处理,自动纠正文档方向,解析无文本层PDF/图片。 -
• 元数据与格式:提取字体、缩进、粗体等样式,附加page_id等元数据。 -
• 批量与嵌套处理:处理ZIP/RAR压缩包内文档,自动解析附件。
快速入手
Dedoc的安装和使用非常友好,官方提供Demo体验、Docker部署、pip安装及详细文档指南。
新手建议直接使用官方Demo网站,只需要设置好相关参数,上传文档即可快速处理。
Demo 地址:https://dedoc-readme.hf.space
该项目有一个REST API,还可以在Docker容器中运行它。
# 拉取镜像
docker pull dedocproject/dedoc
# 运行容器
docker run -p 1231:1231 --rm dedocproject/dedoc python3 /dedoc_root/dedoc/main.py当API服务运行成功后,就可以在本地进行调用:
with open(filename, "rb") as file:
files = {"file": (filename, file)}
r = requests.post("http://localhost:1231/upload", files=files, data=dict())
result = r.content.decode("utf-8")然后会以json输出解析内容。

还可以使用 pip 安装dedoc(Python环境3.8版本及以上)
pip install "dedoc[torch]"更多API使用可以参考文档来进行操作。
使用文档:https://dedoc.readthedocs.io/en/latest
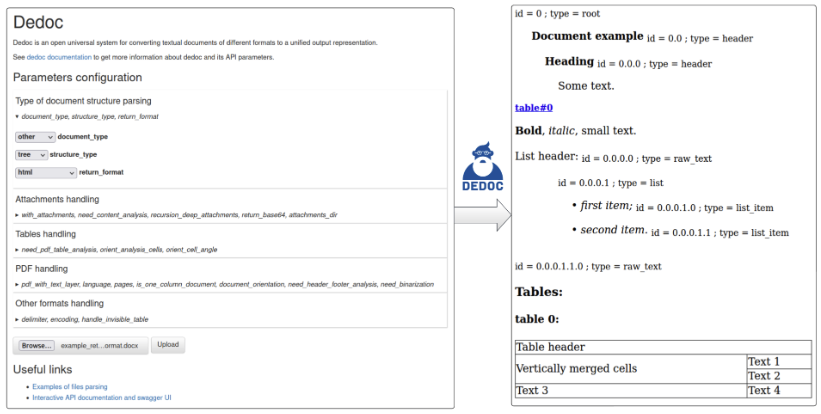
结构提取器展示:

写在最后
Dedoc 作为ISPRAS团队的开源力作,以其强大的多格式支持、智能结构提取和OCR能力,为文档处理带来了革命性突破。
无论是处理复杂PDF、扫描件,还是提取表格和元数据,Dedoc都能提供高效、精准的解决方案。
其灵活的部署方式和对RAG的天然支持,使其成为开发者构建智能文档系统的理想选择之一,适合配合 LLM 做一些文档智能问答、摘要、内容重建等任务。
GitHub 项目地址:https://github.com/ispras/dedoc

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)