

【编者按】作为深度学习三巨头之一,图灵奖得主、AI 教父 Yoshua Bengio 在 2025 北京智源大会上,他表示:AI 能完成的任务时长,每七个月就翻一番,大约五年后,AI 就将达到人类水平,通用人工智能(AGI)或将在五年内到来,而人类社会却尚未在规则、立法乃至全球治理层面达成一致。
自从 ChatGPT 横空出世,AI 进入了加速进化的轨道。从最初能写代码、生成文案,到如今能上网查资料、远程操控家电,它早就不再是那个只会聊天解闷的“电子嘴替”。它开始自己“思考”任务,能在多个软件之间协同操作,甚至具备控制电脑、读写数据库的能力。AI 从幕后算法,变成了贴身助手,再逐步演化成能自主执行复杂操作的“智能体”——从“听话”走向“行动”,它正成为一个真正能“做事”的多面选手。
听起来是不是挺酷?但也不免让人隐隐担忧:当我们满心期待 AGI 时代的到来,畅想着 AI 能帮我们解决一切难题时,另一个更棘手的问题也在浮现——如果有一天,它不再听从人类的指令,那该由谁来“踩刹车”?
在 6 月 6 日举行的北京智源大会上,蒙特利尔大学教授、图灵奖得主 Yoshua Bengio 就提出了这样一个发人深省的问题。在题为《如何从失控的 AI “心智”中拯救人类的未来》的主旨演讲中,他直言:具备行动能力的 AI 一旦失控,可能引发系统性灾难,输家只会是全人类。

他呼吁,我们正处在一个关键的时间窗口,必须尽快建立可验证、安全、负责任的控制机制。
演讲伊始,Bengio 教授便分享了一段深刻的个人心路历程。他坦言,在亲身体验 ChatGPT 并目睹 AI 飞速进化后,深感此前对 AI 失控风险的认知不足。而一个特殊的时刻,让他彻底警醒的是:
2023 年 1 月,我开始不由自主地想到我的孩子,还有我那刚满一岁的孙子。我当时想,20年后,我们几乎肯定会迎来通用人工智能,拥有比人类更聪明的机器。可我却不敢确定,我的孙子是否还能拥有属于他的未来。于是,我决心调整我的研究方向和所有工作,倾尽所能去化解这些风险。尽管这违背了我过去的许多言论、信念和立场,但我知道,这是唯一正确的事。”
这份对子孙未来的深切忧虑,促使这位 AI 巨匠毅然调整了科研方向,将目光聚焦于 AI 安全这一关乎人类命运的议题。
Bengio 分享了许多关于 AI 演化路径、技术治理的精彩观点:
1、AGI 离我们并不遥远:Bengio 警示,AI 的发展速度远超预期,我们可能在 20 年内迎来比人类更聪明的通用人工智能;
以下为演讲全文:
哈喽大家好,谢谢刚刚的介绍。
我今天想和大家分享一段自己的心路历程。这段历程始于两年多前,也就是在 ChatGPT 刚发布不久的那个时候。当时我边试用边在思考:我们可能真的低估了 AI 的进化速度。
那一刻我突然意识到,距离通用人工智能(AGI)真正到来,可能比我们想象中要短得多。
我们已经有了能基本掌握语言、甚至能够通过图灵测试的机器。几年前,这还像是科幻小说,但现在却变成了现实。
ChatGPT 发布之后,我意识到一个问题:我们并不知道该怎么真正控制这些系统。我们可以训练它们,但没法保证它们始终按照我们的意图去行动。那如果有一天,它们比我们更聪明,而且更在乎自己的生存,而不是我们的命运,会发生什么?没人知道答案,但我很清楚:这是一个我们无法承担的风险。
真正让我彻底警醒的是 2023 年 1 月。那段时间,我总会情不自禁地想到自己的孩子,还有刚满一岁的孙子。我心里在想:再过二十年,我们很可能就会迎来通用人工智能,一个比人类更聪明的机器时代。可我却不确定,我的孙子还能不能拥有一个属于他的未来。
那一刻,我下定了决心:我要调整我的研究方向,改变我所有的工作重心,把全部的精力投入到一个目标上——尽我所能去降低这项技术可能带来的风险。哪怕这意味着我得放弃自己过去的一些看法、信念甚至立场,我也觉得这是必须做的。
到了 2023 年底,我正式被任命为《国际 AI 安全报告》的主席。这份报告背后,是一个由来自 30 个国家、欧盟、联合国、经合组织的专家组成的团队——当然也包括了中国和美国的专家。
我们聚焦在三个核心问题上:
-
第一是能力,也就是 AI 现在到底能做什么?未来几年又会发展到什么程度?
-
第二是风险,也就是能力提升所带来的潜在问题是什么?
-
第三是对策,我们现在能做些什么?我们在哪些研究领域、社会机制上,应该提前布好防护网,来应对这些风险?
说到能力这个问题,大家一定要认识到:AI 的进步速度远比我们想象得要快。很多人总是只盯着现在的 AI 水平在讨论问题,但这其实是个错误的出发点。我们真正应该想的是,一年后、三年后、五年后甚至十年后,AI 会变成什么样?虽然没人能未卜先知,但趋势已经非常明显——AI 的能力正在以惊人的速度提升。
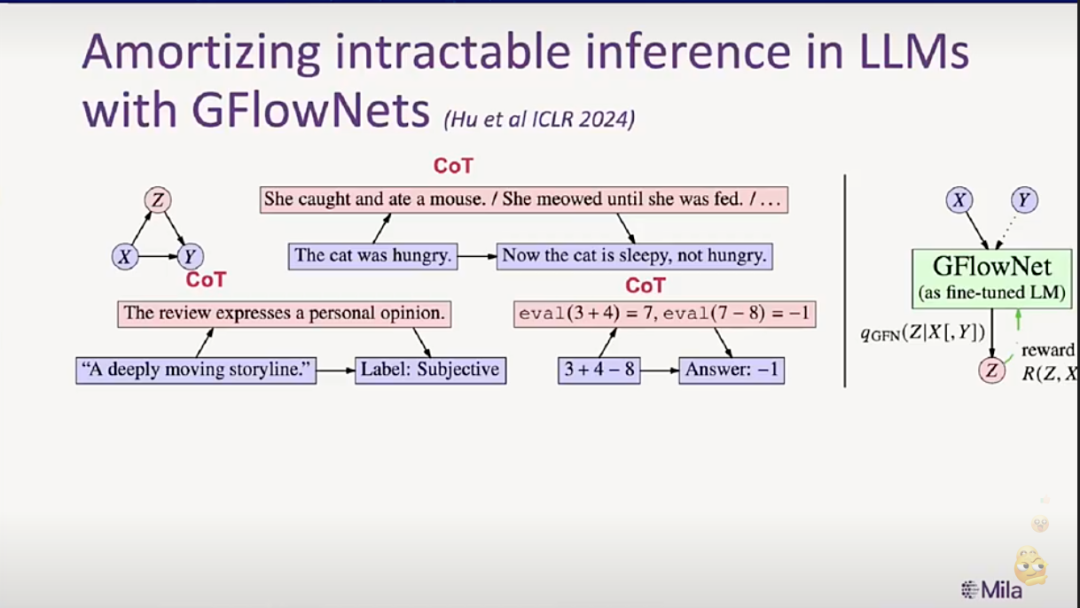
我接下来展示的这张图,是关于 AI 达到人类水平的时间线。在过去一年左右,AI 已经取得了巨大的进步,其中最重要的一项突破,是“思维链”(chain-of-thought)推理模型的出现。它极大提升了 AI 在数学、计算机科学,乃至各类科学问题上的推理和表现能力。
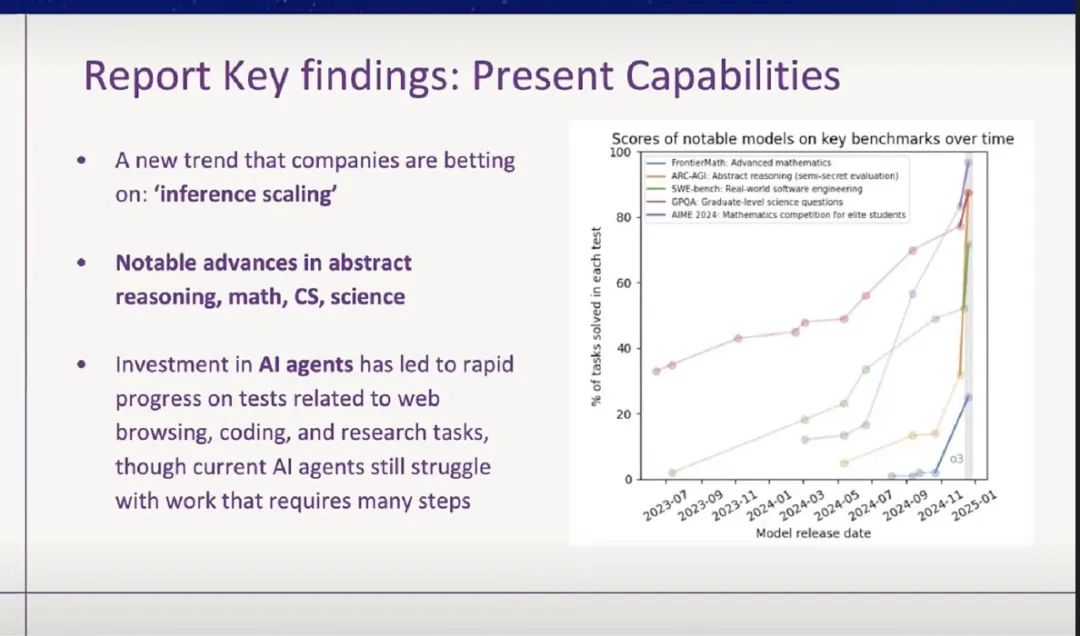
还有一个我特别关注的趋势,就是“自主心智”(Agency)。AI 不再只是一个聊天机器人,它开始具备了做事的能力。它能编程、能浏览网页、能操控电脑、控制家用电器,甚至能读写数据库。这些能力的出现,让 AI 更像是一个可以“行动”的智能体。
其中我尤其想强调的是“规划能力”。这是目前 AI 在认知层面上,跟人类差距还比较大的一个方面,所以我们必须密切关注它的进展。比如 MITRE 公司最近做了一项研究,展示了 AI 规划能力的增长趋势。横轴是过去五年,纵轴是 AI 完成一项任务所需的“时长”,用人类完成同样任务所需的时间来衡量。你们看这条线,乍一看像是直线,但其实这是一条对数刻度的图,也就是说,它真正呈现的是一个指数级的增长。
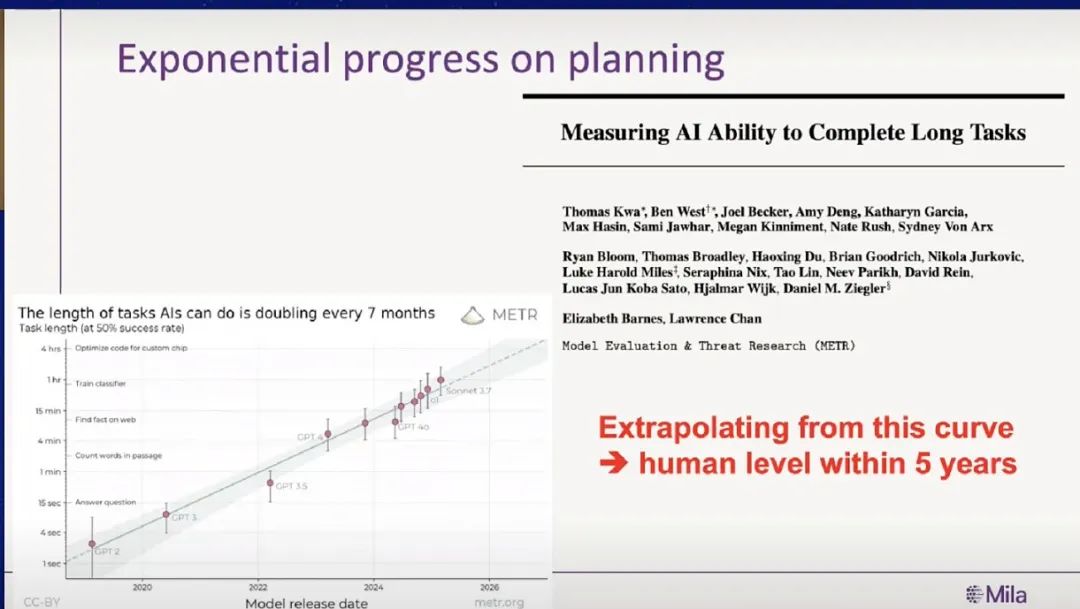
图上的每一个点,代表当时最先进的 AI 系统。而这些点几乎都精准落在了这条指数曲线上,这意味着 AI 完成任务所需的时间,平均每七个月就会减半。照这个趋势推算,五年之后,AI 在许多规划任务上就能达到人类水平。当然,未来可能会出现瓶颈,但我们不能指望奇迹发生。我们在制定政策、布局商业计划时,至少得把这种趋势的持续性作为一个可能性认真对待。
想象一下,如果一个 AI 想干一件极其危险的坏事,它首先得具备这个能力。所以,对 AI 进行“能力评估”就变得非常关键。现在很多关于 AI 风险的管理工作,基本上都是从评估 AI 具备什么能力开始的,比如它能不能用这些能力去伤害个人或社会。
但我们都知道,光有能力还不够。就像一个人即使有杀人的能力,如果他没有动机,这件事大概率也不会发生。更何况,在当下公司与公司、国家与国家之间竞争如此激烈的情况下,想让全世界都暂停 AI 能力的研究,几乎是不可能的。
那我们还能做些什么?或许我们可以从“意图”下手,来降低风险。换句话说,就算 AI 变得很强,只要我们能确保它没有坏心思,保持诚实,那它就不会伤害我们。
我来举个例子。下面这张图展示了 David Krueger 去年提出的一个观点:一个 AI 如果要真正变得危险,通常需要三样东西——一是智力,也就是它知道很多、理解很多;二是“手脚”,即它能对这个世界产生实际作用,比如会说话、能上网、能写代码、能操控机器人等;三是目标,它必须有自己的目的。

所以我在研究的一个方向是:我们能不能只造出拥有“智力”的 AI,但不给它“目标”,也不让它有太多“手脚”?当然,我们还是希望它能和我们交流。我把这种 AI 叫作“Scientist AI”。


(文:AI科技大本营)