


发起Open-Sora-Plan开源项目,在github狂揽12k星的北大袁粒课题组最新动向,他们刚刚提出了一个名为UniWorld-V1的统一大模型架构
论文地址:
https://arxiv.org/abs/2506.03147
GitHub 地址:
https://github.com/PKU-YuanGroup/UniWorld-V1
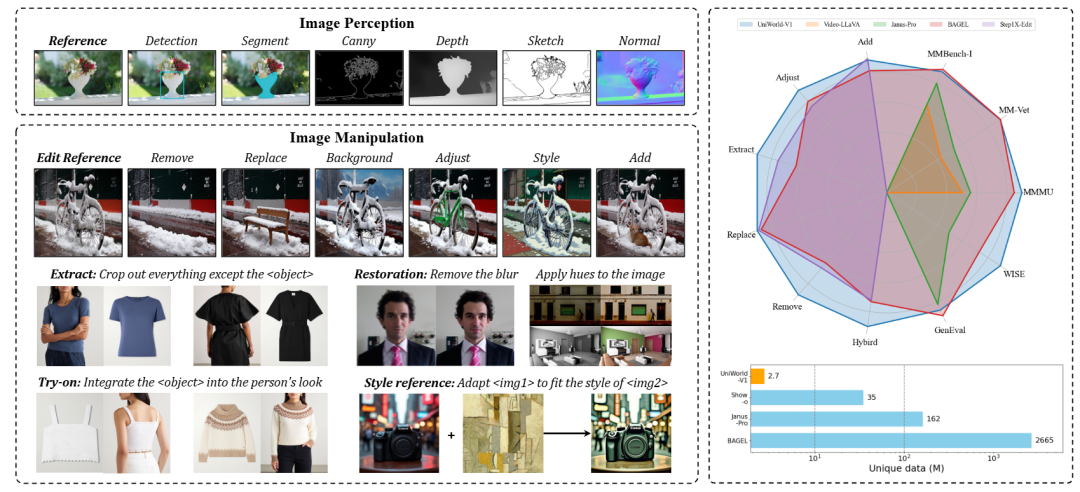 图1 UniWorld在多个基准上达到先进的性能
图1 UniWorld在多个基准上达到先进的性能
通过对 GPT-4o-Image 的实验观察,研究团队发现其在视觉特征提取上更依赖语义编码器而非传统的 VAE,这一洞察为统一模型的架构设计提供了新思路
基于上述发现,提出了 UniWorld-V1 —— 一个整合高分辨率对比语义编码器与多模态大模型的统一生成框架,仅用 2.7M 样本即可同时支持图像理解、生成、编辑与感知等多种任务
在多个基准上,UniWorld-V1 性能与 BAGEL(2665M 样本)和专业的图像编辑模型 Step1X-Edit相当,并且开源了全部代码、模型权重与数据集,促进后续研究与复现
观察

在“编辑实验”中,让 GPT-4o-Image 将公交车背面的广告涂成蓝色,观察到编辑前后黄色和绿色标签文字的位置发生明显不一致,说明低频结构没有被严格保留,VAE 特征(强调低频信息)无法解释这一现象
在“去噪实验”中,将一张狗的图像分别加噪至 0.4× 和 0.6×,GPT-4o-Image 对低噪图像能够正确去噪,但在高噪(0.6×)下将狗误判为鹿。进一步调用 GPT-4o 和 Qwen2.5-VL 理解模块发现,它们对高噪图像也一致地识别为鹿,表明 GPT-4o-Image 依赖强大的多模态理解先验而非 VAE 的低频信息。
综上,这些观察支持了 GPT-4o-Image 使用基于语义编码器的视觉特征提取方案。
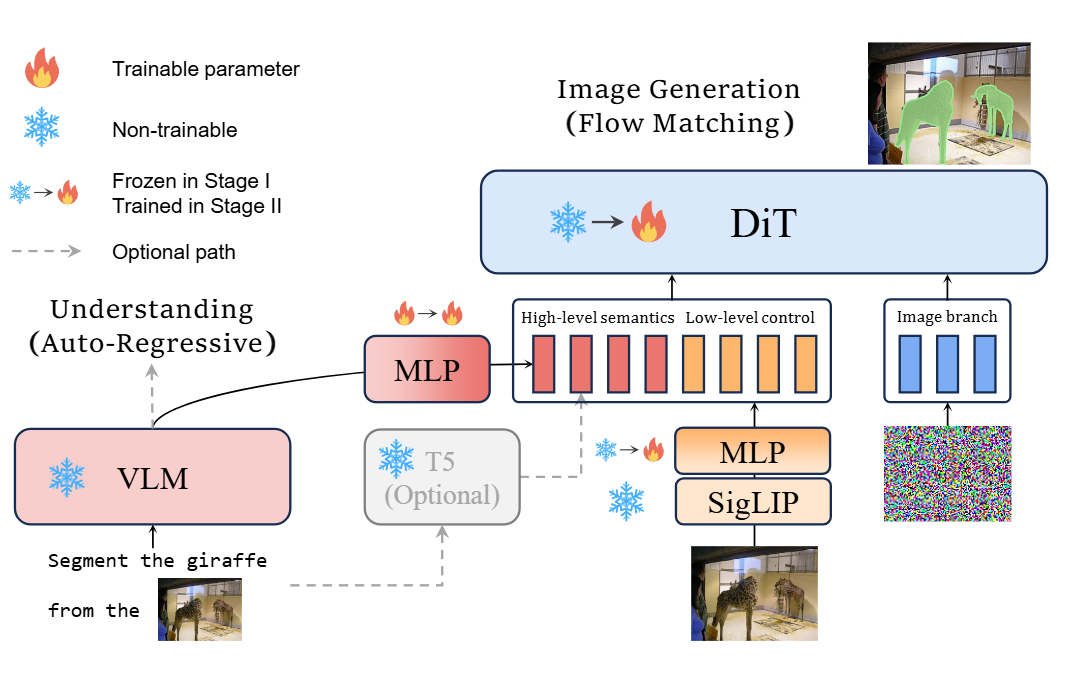
架构
基于实验发现,将原先基于 VAE 的低级控制信号替换为对比式视觉-语言模型 SigLIP 编码器(选用最高分辨率版本 SigLIP2-so400m/14,固定输出 512×512)。在视觉理解部分,沿用了团队先前工作中使用的 Qwen2.5-VL-7B 预训练模型。对于参考图像,同时使用 Qwen2.5-VL-7B 和 SigLIP 进行处理,并将两者的输出拼接后,作为 FLUX 文本分支的输入,从而实现更优的特征融合与建模。基于实验发现,将原先基于 VAE 的低级控制信号替换为对比式视觉-语言模型 SigLIP 编码器(选用最高分辨率版本 SigLIP2-so400m/14,固定输出 512×512)
实验
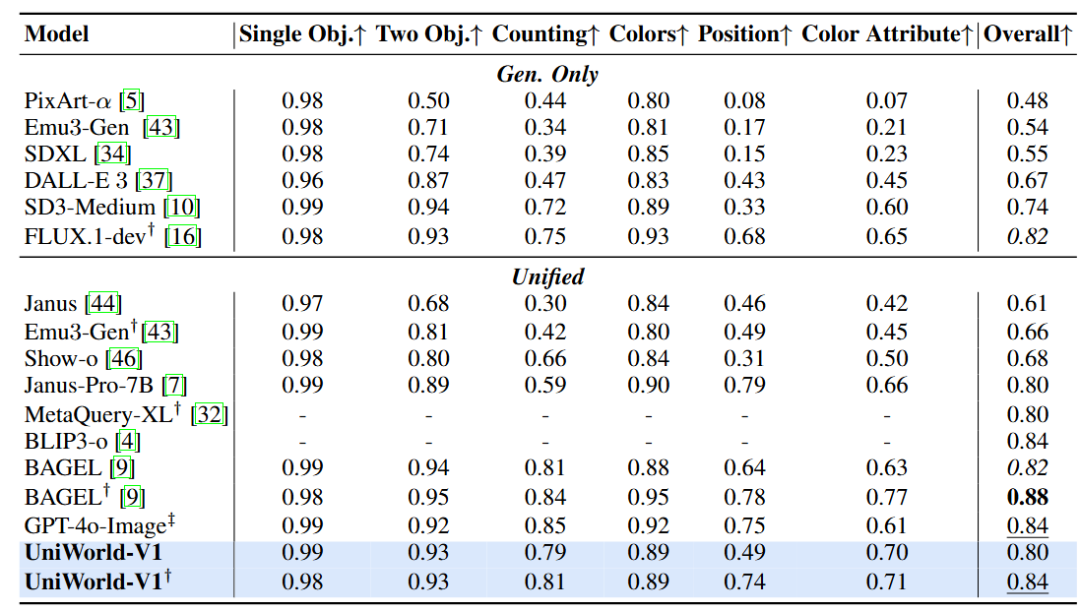
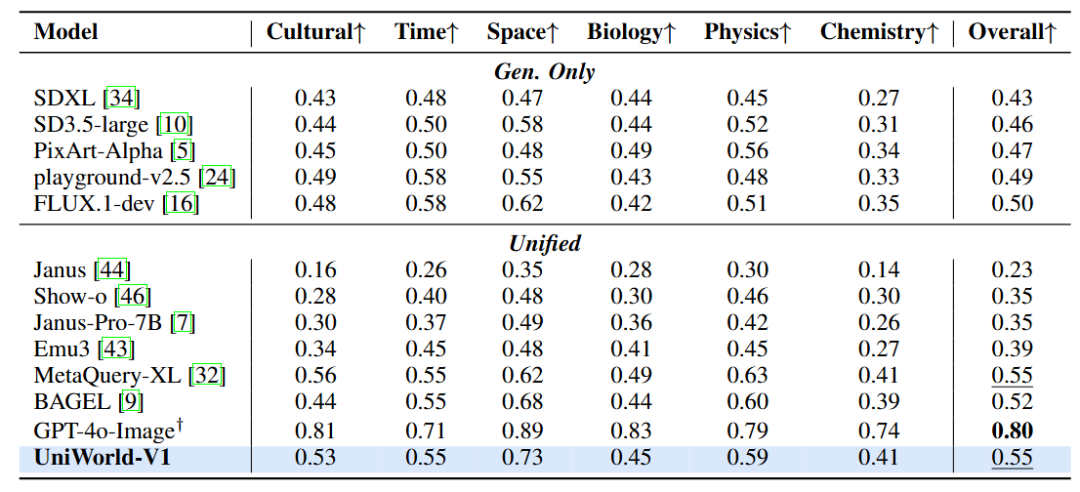
在 GenEval 测试中,UniWorld-V1 取得总体 0.79 分;使用与 BLIP3-o 相同的提示重写后得分提升至 0.84,已非常接近 BAGEL 的 0.88。在 WISE 基准上,UniWorld-V1 综合得分 0.55,尤其在“空间”类题材中获得 0.73 分,仅次于 GPT-4o-Image 的 0.89,位列其他统一模型之首,展现了其在整合世界知识生成图像方面的竞争力
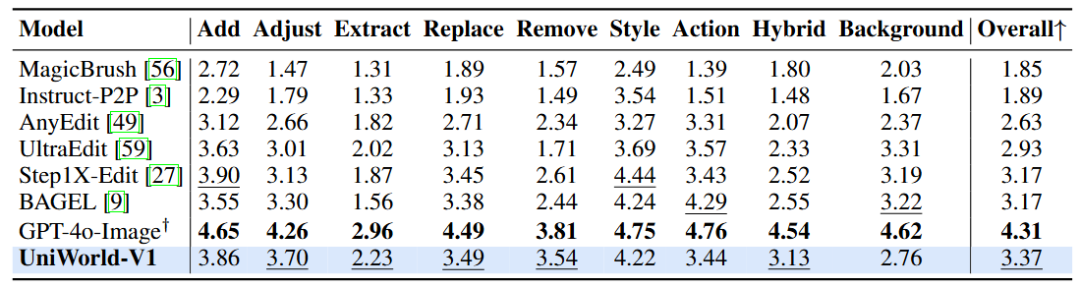
在 ImgEdit-Bench 对比中,UniWorld-V1 以总分 3.37 位居所有开源模型之首,显著领先于 Step1X-Edit 和 BAGEL(均为 3.17)。它在 Adjust(3.70)、Remove(3.54)、Extract(2.23)、Replace(3.49)和 Hybrid(3.13)五大关键指标上均获开源模型最高分,展现了在属性调整、元素移除、对象提取、混合编辑与内容替换等任务中的卓越能力。虽然 GPT-4o-Image 以 4.31 继续领跑,但 UniWorld-V1 的表现最接近该行业标杆,标志着其在开源阵营中已实现媲美顶级模型的图像编辑水平
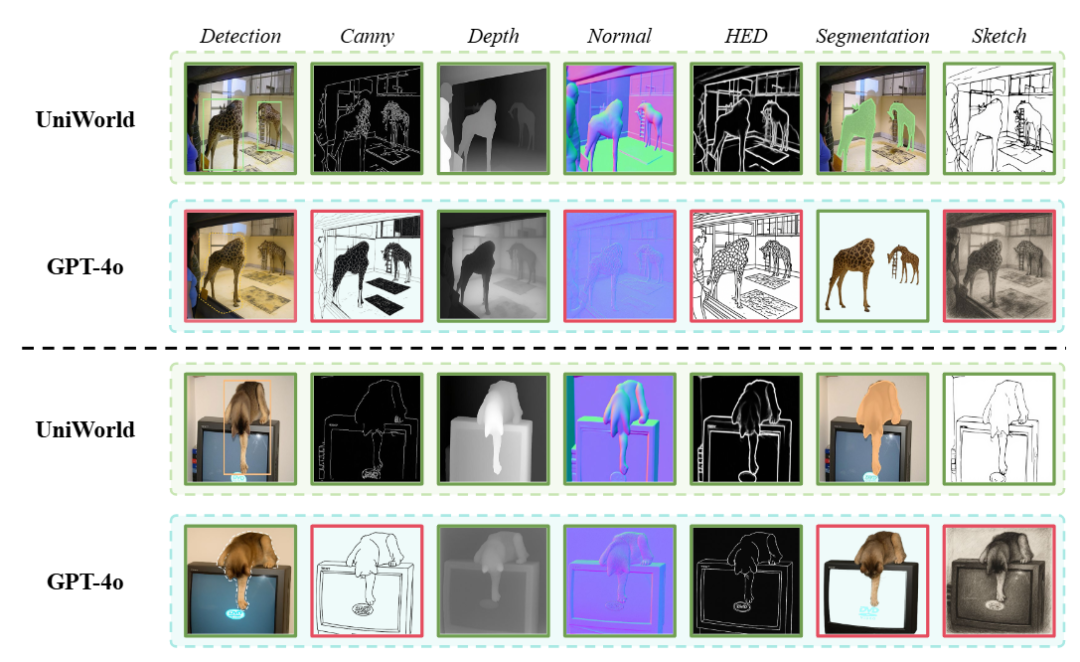
通过示例与 GPT-4o-Image 进行了定性对比。结果显示,UniWorld-V1 在各类感知任务上表现不俗,甚至在许多方面超越了 GPT-4o-Image。尤其在 Canny 边缘检测、法线图生成、HED、分割和草图生成等任务中,UniWorld-V1 的指令理解与执行能力更强。这表明其一体化架构能够提供广泛且准确的图像感知功能,是首个具备如此多样且高保真视觉分析能力的开源统一模型
⭐
(文:AI寒武纪)