
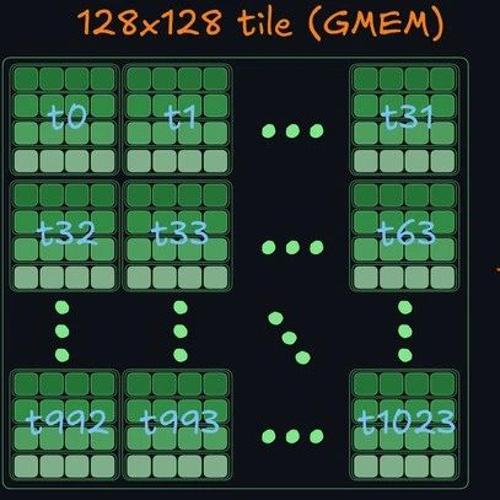
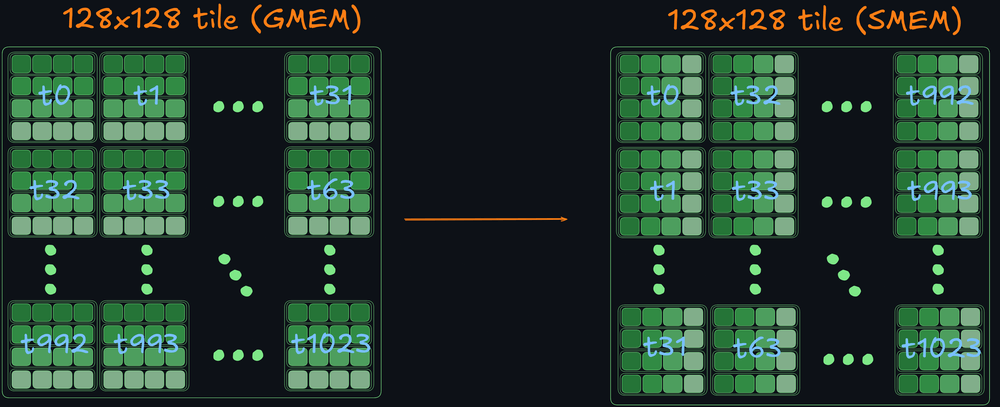
作者将解决方案分为三个主要部分:从全局内存加载数据到LDS(本地数据共享)、从LDS读取到寄存器并执行MFMA(矩阵融合乘加)操作,以及将数据存储回全局内存。关键优化包括LDS瓦片大小、块大小、调度策略等,并详细探讨了如何通过双缓冲、内存交错策略等技术提高性能。
参考文献:
[1] https://akashkarnatak.github.io/amd-challenge/
[2] https://github.com/AkashKarnatak/amd-challenge/blob/master/swz4x4-full-db-16×16.hip
[3] https://github.com/AkashKarnatak/amd-challenge/blob/master/swz4x4-full-db-streamk-16×16.hip
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)