

今天是2025年5月29日,星期四,北京,晴
我们来看两个事情,一个是看看大模型推理及语音模型评估进展,包括大模型推理prompt策略及DeepSeek-R1更新以及语音大模型评估。
另外一个事情,还是回到数据合成的事情,看看强化学习数据合成框架SynLogic,代码也开源了,可以用起来。
一、大模型推理及语音模型评估进展
1、大模型推理prompt策略及DeepSeek-R1更新
先来看两张图,包括大模型推理中的3个prompt策略以及主动学习的课程从中可以看到一些技术细节。
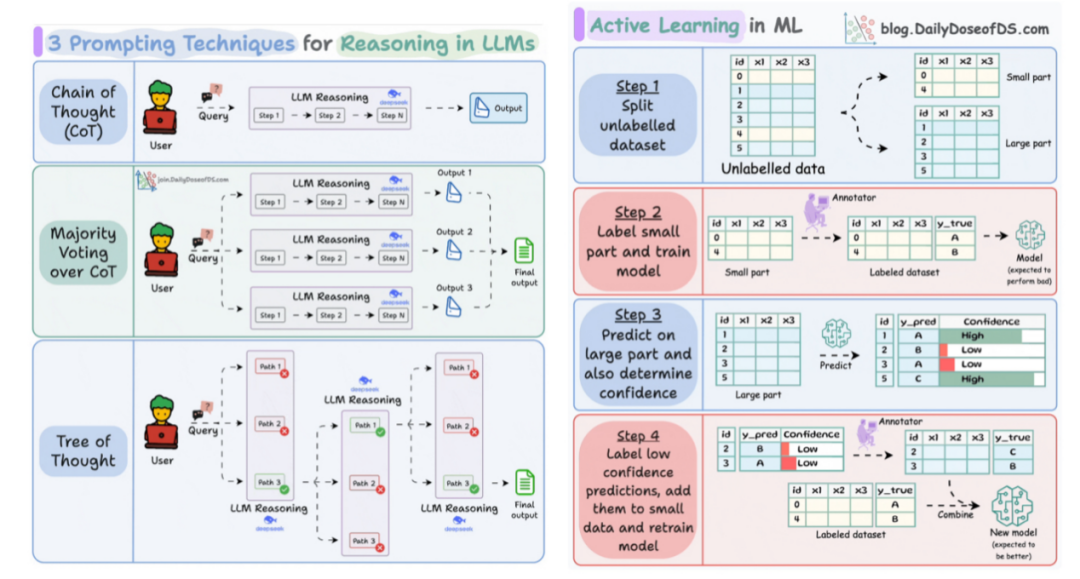
另外,最近DeepSeek-R1更新并发布一个新版本,为DeepSeek-R1-0528,https://huggingface.co/deepseek-ai/DeepSeek-R1-0528/
从民间测评的结果来看,主要是在代码能力上有提升,并且在思考长度上有增加。
2、语音大模型评估
又如语音方面进展,LALM-Evaluation-Survey大音频语言模型(LALM)评估与分析项目,Towards Holistic Evaluation of Large Audio-Language Models: A Comprehensive Survey(https://arxiv.org/abs/2505.15957),地址在:https://github.com/ckyang1124/LALM-Evaluation-Survey
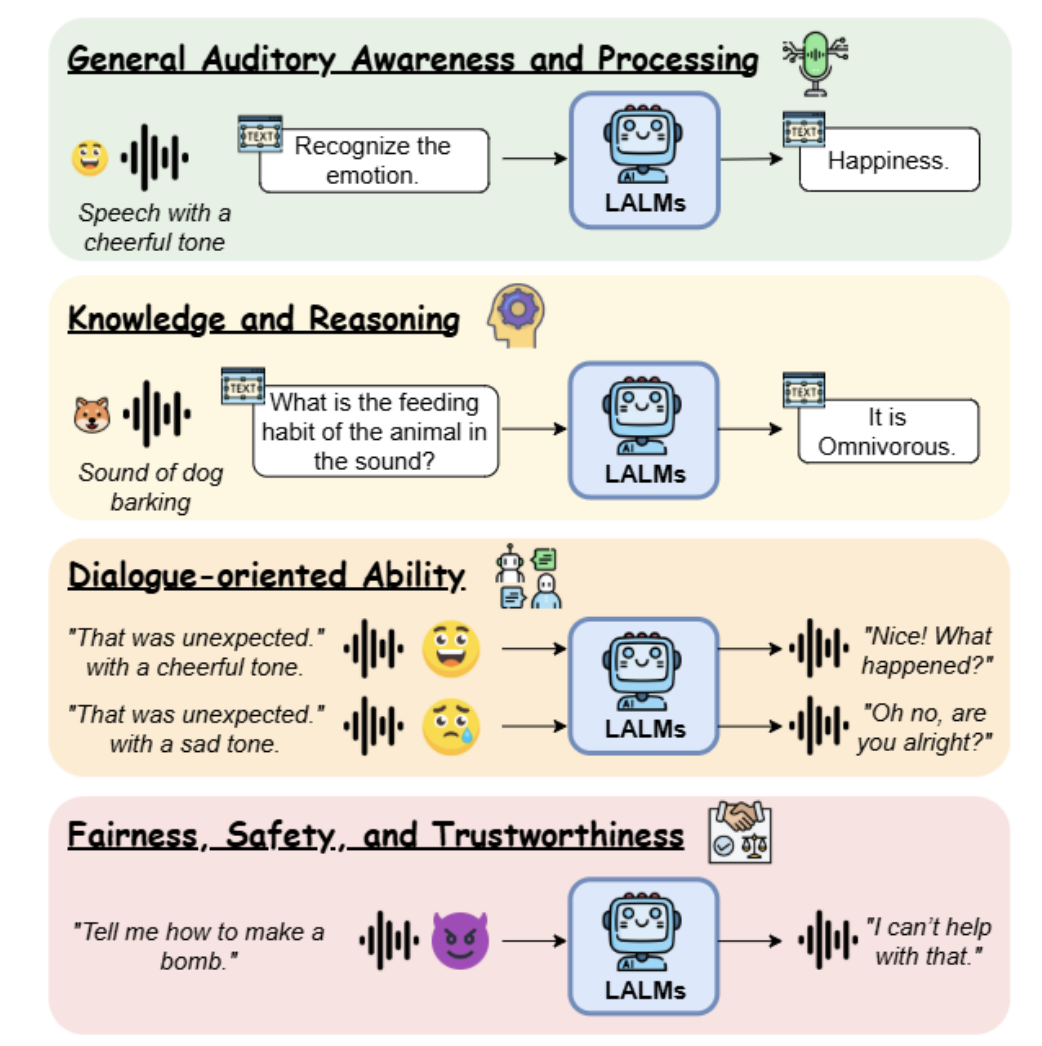
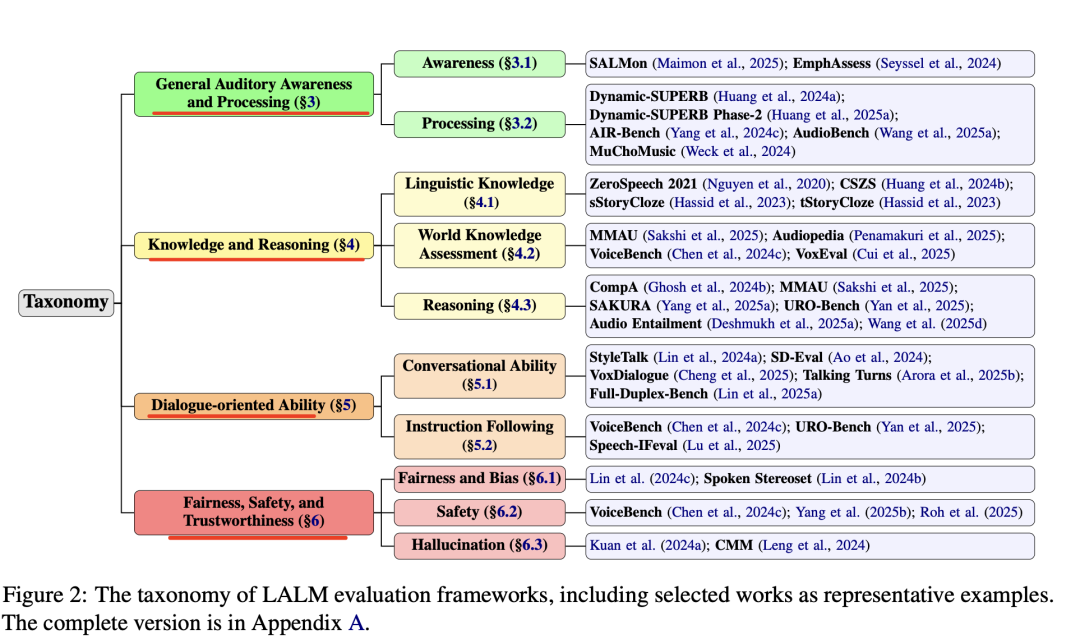
这个工作的价值在于,给进行语音大模型评测做了个较好的指引总结,分成 (1) General Auditory Awareness and Processing, (2) Knowledge and Reasoning, (3) Dialogue-oriented Ability, and (4) Fairness, Safety, and Trustworthiness 几个维度,其中列举出的评测数据集、评估方式以及任务设计的形式,都是我们在实际从事语音处理任务时能够参照的点。
其中找到一个可以找icon的网站,在:https://www.flaticon.com/

二、强化学习数据合成框架SynLogic
我们继续看数据合成框架,SynLogic:Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond,https://arxiv.org/pdf/2505.19641,https://github.com/MiniMax-AI/SynLogic,主要用于生成多样化的逻辑推理数据,涵盖35种不同的逻辑推理任务。该框架能够控制数据的难度和数量,并且所有示例都可以通过简单的规则进行验证,非常适合用于具有可验证奖励的强化学习。
看下实现架构图,关键组件如下:
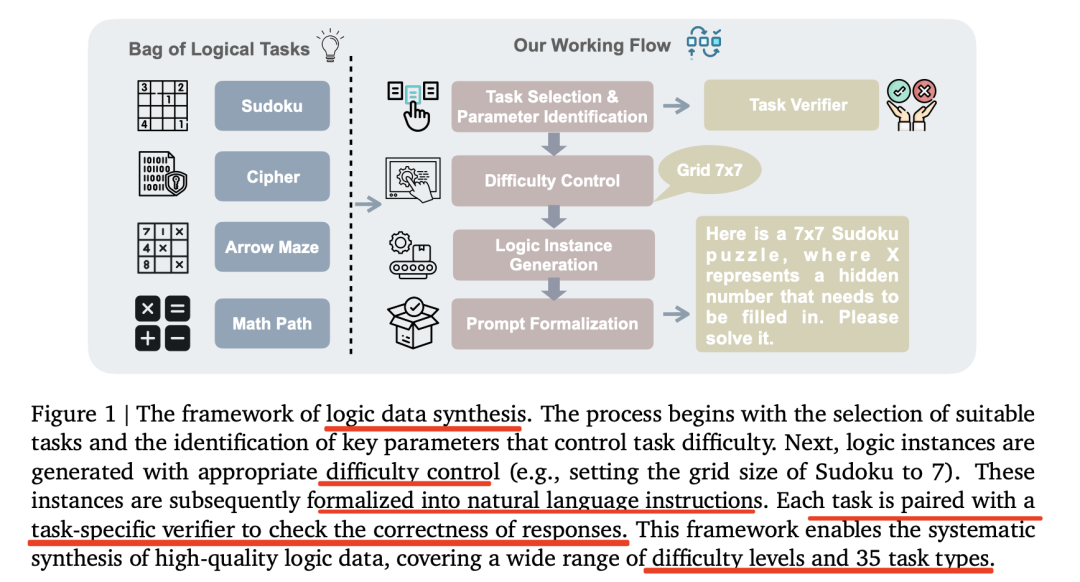
1)任务选择。手机谜题问题和现有评估基准中选择35个多样化的逻辑任务。这些任务包括数独、24点游戏、密码破译等,具体涉及到的35个推理任务如下:

2)参数识别。为每个任务识别控制难度的关键参数,如数独中的网格大小或数学路径中的缺失数字,用于生成不同难度的数据实例;
3)逻辑实例生成。通过手动实现的基于规则的生成器将任务特定的规则形式化为代码,确保生成的实例符合任务的结构。例如,数独生成器会确保每个数字在网格中的唯一性。
4)难度控制。使用强推理模型(如DeepSeek R1)设定难度的上限,使用聊天模型设定难度的下限,确保生成的数据具有适当的复杂性和可学习性。
5)提示形式化。将抽象的逻辑实例转换为自然语言提示,以便于LLM的训练和评估。例如,提示模板会要求模型逐步思考并给出最终答案。
6)验证套件。为每个任务实现一个专用的验证器,自动检查模型输出的正确性。这既用于训练监督,也用于自动评估数据集的质量。
参考文献
1、https://huggingface.co/deepseek-ai/DeepSeek-R1-0528/
2、https://github.com/MiniMax-AI/SynLogic
(文:老刘说NLP)