
Anthropic刚刚宣布了一个重磅消息:开源电路追踪工具!简单说,就是AI模型的“黑箱”有望被进一步打开
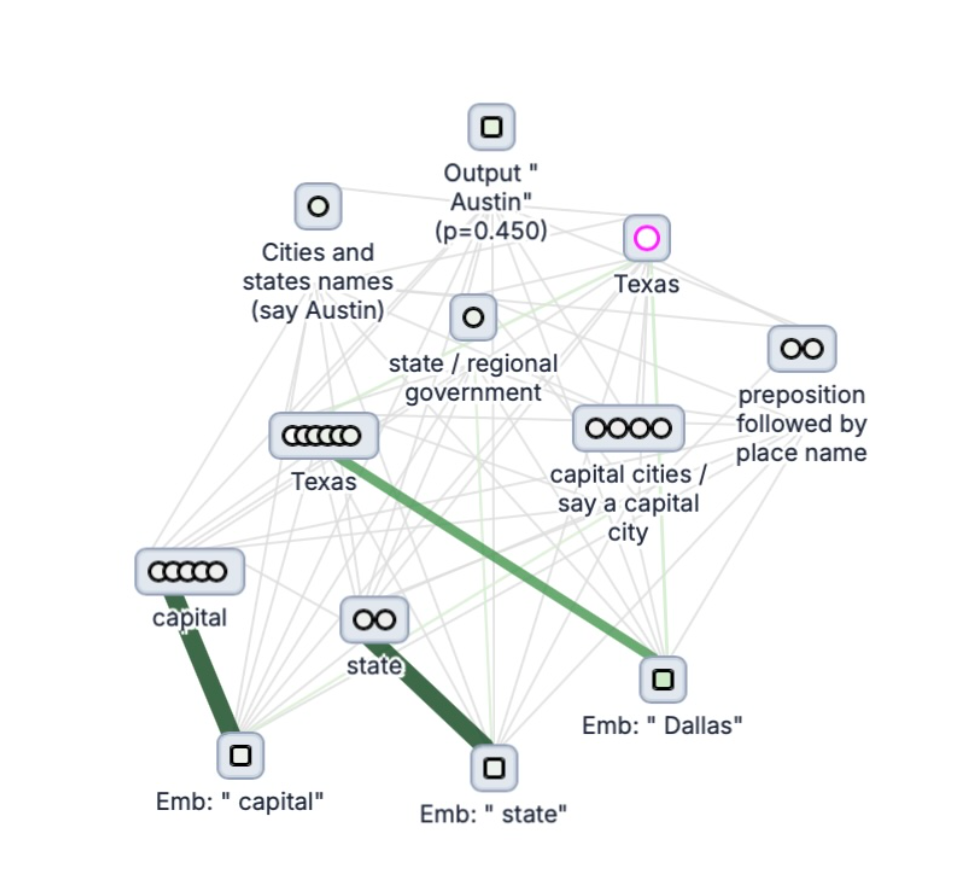
划重点
-
1. “读心术”:Anthropic开源的新方法能追踪大型语言模型(LLM)的神经元 -
2. 归因图谱是关键:通过生成“归因图谱”(attribution graphs),部分揭示模型内部为啥会给出特定输出 -
3. 工具全家桶:不仅开源了生成图谱的库,还联合Neuronpedia提供了酷炫的交互式前端,让你点点鼠标就能探索
长久以来,大模型的“黑箱”问题一直是AI研究者和开发者心头的一块大石。模型越来越强,但我们对其内部运作机制的理解却远远跟不上。正如Anthropic的CEO Dario Amodei最近强调的,提升AI的可解释性迫在眉睫。如果我们不知道AI是怎么“想”的,那安全性和可信度从何谈起?
这次,Anthropic直接放了大招!他们开源的这套电路追踪工具,核心就是生成“归因图谱”。你可以把它想象成一张详细的“思维导图”,展示了模型在处理你的输入时,内部哪些神经元、哪些注意力头在关键时刻发挥了作用,它们之间是如何相互影响,最终“合谋”生成了那个答案
开源地址:
https://github.com/safety-research/circuit-tracer
具体来说,Anthropic这次开源了:
一个开源库:这个库能让你在流行的开源权重模型上生成归因图谱。以后研究者们不用从零开始造轮子了,直接上手就能用。
一个Neuronpedia托管的前端:你可以通过这个交互界面,直观地查看、分析这些复杂的图谱

地址:
https://www.neuronpedia.org/gemma-2-2b/graph
有了这些工具,可以做什么?
-
1. 追踪电路:在支持的模型上,针对你感兴趣的输入,生成专属的归因图谱。 -
2. 可视化、注释和共享:利用交互式前端,不仅能看,还能在图谱上做标记、写注释,甚至方便地分享给同行。 -
3. 检验假设:更进一步,你可以修改图谱中某些特征的数值,然后观察模型的输出会发生什么变化,以此来验证你对模型内部机制的猜想。
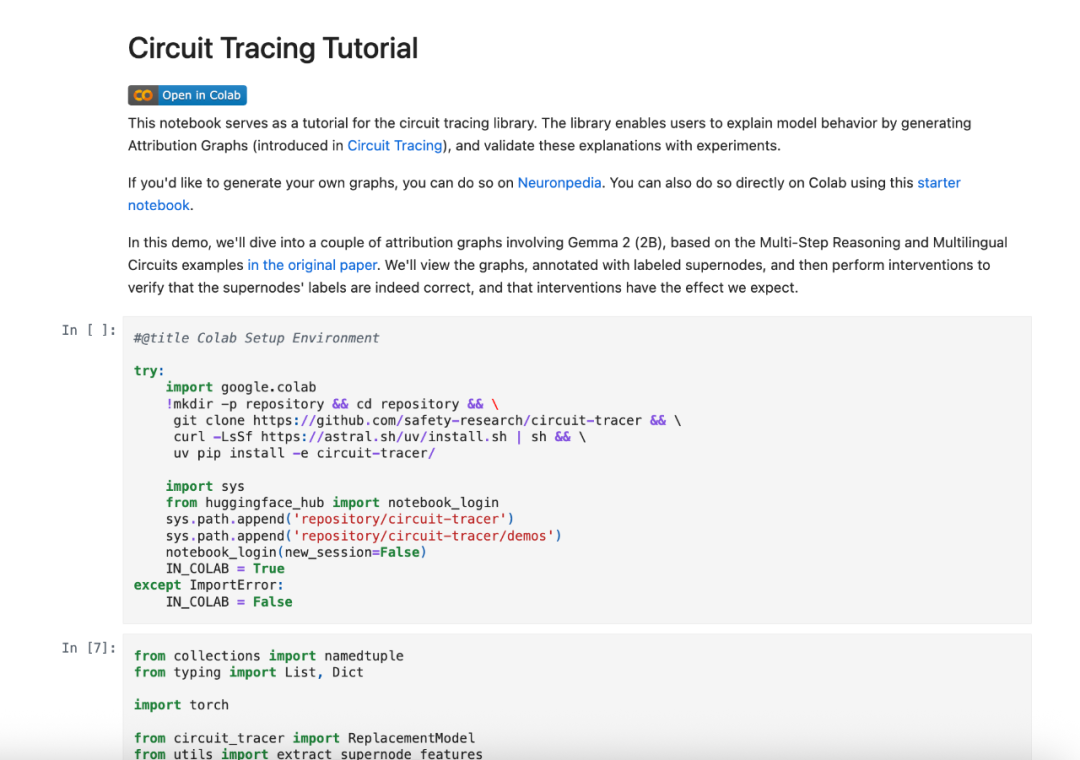
Anthropic自己已经用这套工具在Gemma-2-2b和Llama-3.2-1b等模型上搞了不少有意思的研究,比如多步推理过程、多语言表征等。他们还准备了demo notebook,手把手教你怎么用
notebook地址:
https://github.com/safety-research/circuit-tracer/blob/main/demos/circuit_tracing_tutorial.ipynb
参考:
https://www.anthropic.com/research/open-source-circuit-tracing
⭐
(文:AI寒武纪)