

最近我偶然读到了《RHO-1: Not All Tokens Are What You Need》这篇论文,感觉蛮有意思的。想想看,我们在各自领域是不是也常常面临”数据太多但不知哪些真正有用”的困境?本文就尝试解读这篇论文的核心思想。
论文标题:RHO-1:Not All Tokens Are What You Need
文章链接:https://arxiv.org/abs/2404.07965
github地址:https://github.com/microsoft/rho1. 基本概念:我们需要知道什么?
在理解RHO-1之前,先得搞清楚几个基础概念。对很多非NLP研究者而言,这些可能并不那么直观。
1.1 Token:文本的基本单位
简单来说,token就是将文本切成小块的结果。不过这里有个容易混淆的点:token并不等同于”词”。它可能是一个完整单词,也可能是单词的一部分,甚至是个标点符号。比如”machine learning”可能被切分为[“machine”, “learning”],也可能是[“ma”, “chine”, “learn”, “ing”],这取决于具体模型的分词系统。
1.2 因果语言建模(CLM):单向预测
“因果”这个词在这里有点误导人——它与我们常说的”因果关系”不完全是一个概念。在NLP中,”因果语言建模”主要指的是单向预测:模型只能看到当前位置之前的token,而不能看到之后的token。
这就像我们平时写文章,下一个词只能基于前面已经写的内容,而不能基于还没写的内容。与之对应的是BERT这类双向模型,它们可以同时看到前后文。
2. 核心创新:不是所有数据都平等
论文中最有趣的部分是关于token分类的分析。研究者追踪了每个token在训练过程中的损失变化,发现它们大致分为四类。
2.1 四种token,四种特性
-
• H→H tokens (11%) : 这些token从训练开始到结束都保持高损失,模型就是学不会。它们可能是非常罕见的术语、错误的文本,或者本身包含很高的不确定性。这让我想到了我们领域中那些”异常值”,无论怎么建模都难以拟合的数据点。 -
• L→H tokens (12%) : 这类token起初预测得不错,但随着训练反而变差了。这现象很有意思,似乎模型在”牺牲”这部分能力去提升其他方面。类似于神经网络中的”灾难性遗忘”现象,只是发生在更微观的层面。例如:在从通用语料转向专业语料训练时,一些常用词的预测准确度可能下降。 -
• H→L tokens (26%) : 这是模型真正学习的部分。它们开始时预测困难,但随着训练逐渐变得容易预测。这部分token是模型能力提升的来源。 -
• L→L tokens (51%) : 这些token从始至终都很容易预测,比如常见的介词、冠词等。模型基本上不需要花力气去学习它们。
由此,只有约四分之一的token展现出真正的学习曲线(H→L)。这意味着传统训练方法中,大约75%的计算资源可能花在了”无效学习”上!
(作者这里是基于OpenWebMath数据集中的15B token,预训练了一个Tinyllama-1B,而后在一个320k token的验证集上,追踪了每个token的变化)
2.2 参考模型:判断token学习难度
论文提出了一个方法来判断哪些token值得学习:使用”参考模型”。
参考模型是什么?简单说,它是一个与主模型结构、大小相同,但在高质量、领域相关数据上预先训练好的模型。它代表了”理想分布”下模型应有的预测能力。
通过比较主模型和参考模型在同一token上的预测损失差异,可以判断:
-
• 如果主模型损失远高于参考模型,说明这个token很有学习价值 -
• 如果主模型损失接近或低于参考模型,说明这个token可能不太值得学习
这让我联想到教育心理学中的”最近发展区”理论——学习最有效的内容不是太简单也不是太难,而是那些恰好有一定挑战性的内容。
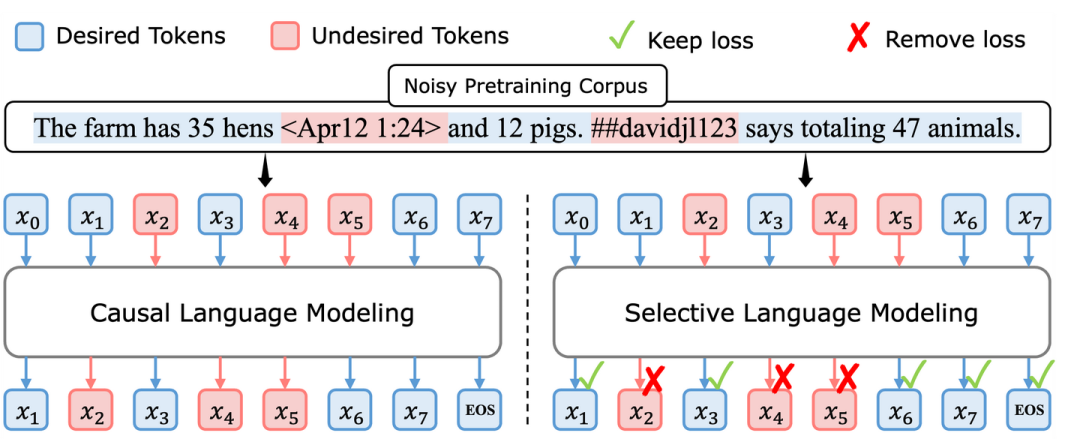
2.3 选择性语言建模(SLM):聚焦有价值的学习
基于以上发现,论文提出了”选择性语言建模”方法。核心思想很直观:只对有价值的token进行训练。
具体来说,SLM通过以下步骤工作:
-
• 计算每个token的”超额损失”:主模型损失减去参考模型损失 -
• 根据超额损失排序,选择top-k%(通常60-70%)的token -
• 只对选中的token计算梯度并更新模型参数
表面上看,这似乎会导致信息丢失。但实际上,模型仍然会处理所有token以维持上下文理解,只是不对那些”不值得学习”的token计算损失和更新参数。
2.4 实现细节
原作者开源但是没有完全开源,因此本文是基于unoffical的代码来讲解SLM Loss的细节
2.4.1 超额损失计算:
每个token的超额损失公式为:
其中, 和 是每个token的logits,即参考模型在该token上的预测logits和主模型的logits。做差后,获取超额损失。
2.4.2 选择top-k%的token:
根据超额损失对所有token排序,选择排名靠前的k%:
-
• 通常k设置为60%~70% -
• 对于1B参数模型,实验中最佳值为60% -
• 对于7B参数模型,实验中最佳值为70%
2.4.3 只对选中的token应用损失:
SLM的损失函数为:
其中:
-
• 是指示函数,当token在选中的top-k%中时为1,否则为0 -
• 只有选中的token会对模型参数更新产生贡献,未选中的token会参与前向传播过程,但是不计算损失,不参与更新参数
3.实验结果:少即是多
RHO-1的实验结果令人印象深刻,尤其是在效率方面:
-
• RHO-1-7B仅使用DeepSeekMath-7B(2.1%的训练数据(10.5B vs 500B token)就达到了相近的性能。 -
• 达到基线性能的速度比传统方法快5-10倍。
在数学推理等具体任务上,1B参数的RHO-1经过微调后在MATH数据集上达到40.6%的准确率,7B参数版本达到51.8%。这个性能提升不仅显著,而且效率极高。
4.思考与问题
读完这篇论文,我还有一些思考和疑问:
-
• 随着模型规模增大,值得学习的token比例会不会变化?大模型是否能更好地学习那些”H→H”型token? -
• 不同领域的理想token选择比例可能不同,如何自动确定最佳的k值? -
• 如果将这种思路应用到计算机视觉,是不是意味着我们应该关注那些”信息量大”的图像区域,而不是整张图片?
这些问题可能需要更多研究来回答。不过,从RHO-1而言,在AI研究中,有时候”减法”比”加法”更重要——知道什么不需要学,可能比知道什么需要学更关键。
参考列表
[1]非官方的slm loss实现:https://github.com/oelin/selective-language-modeling/tree/main
[2]Rho-1: Not All Tokens Are What You Need:https://arxiv.org/abs/2404.07965
[3]官方repo:https://github.com/microsoft/rho
(文:机器学习算法与自然语言处理)