
随着大语言模型(LLM)的发展,AI 的「推理能力」正以前所未有的速度突破。然而,很多企业级检索系统却依旧停留在简单的关键词匹配阶段,难以支持真正意义上的“深度知识发现”。
LightOn 最新发布的开源模型 Reason-ModernColBERT,正是为了解决这一瓶颈——让检索系统具备推理能力,支撑 Agentic RAG 与深度研究场景。
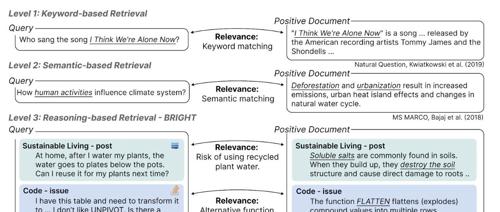
🔎 检索系统的“三个进化阶段”你了解吗?
信息检索系统的发展,其实可以划分为三个阶段:
1️⃣ Level 1:关键词匹配(Keyword-based Retrieval)
系统只看你用了哪些词,然后在文档中找“原词”出现的位置。
2️⃣ Level 2:语义匹配(Semantic-based Retrieval)
系统开始理解你在说什么,用 embedding 或向量表示找到“意思差不多”的内容。
3️⃣ Level 3:推理检索(Reasoning-based Retrieval)
系统不再局限于词汇或语义,而是能“推理”出隐藏的关系,找出看似无关但逻辑相关的资料。
🧠 什么是“推理型信息检索”?
通俗地说,就是系统能够在查询和文档之间,补出那些未被显性写出但逻辑上存在的桥梁。
比如你问:
「如何重复利用花盆底部的积水?这样对植物安全吗?」
关键词检索只会找“积水”“重复利用”;
语义检索可能能找出“浇水”“排水系统”;
但真正的推理型检索会知道:
-
花盆底部积水中可能含有肥料残留的溶解盐
-
盐分长期积累可能会造成植物根系损伤
-
所以关于“盐害”“根腐”的文档,其实才是你问题的核心答案所在
-
即使这些文档一句也没提到“重复利用积水”
这正是 Reason-ModernColBERT 想解决的——让 AI 真正“懂你要问的”,而不只是“找你说的词”。
💡 Reason-ModernColBERT 是什么?
由 LightOn 团队推出的开源模型 Reason-ModernColBERT,基于多向量(multi-vector)+ Late Interaction 架构构建,专为推理密集型检索场景设计。
它不仅具有出色的表现力,还保持了出人意料的小体积和极高的效率。
🧠 小模型,大突破
🔹 模型体积仅 150M —— 是同类 SOTA 模型的 1/45!
🔹 性能全面碾压大模型:在权威评测集 BRIGHT 上,超过所有 7B 级模型,在 Stack Exchange 实测中,比 ReasonIR-8B 高出 2.5+ 的 NDCG@10 分数。
也就是说,它不仅轻量,还非常“聪明”——能真正理解、综合、推理文档之间的隐含关系。
⚙️ 极致效率,几行代码搞定训练
得益于 LightOn 自研的 PyLate 框架:
-
训练时间:< 2 小时
-
训练代码:< 100 行
-
推理速度:远快于大型 LLM
对研发团队和独立开发者来说,无疑是极具性价比的一次架构革新。
🔄 为什么它比 Dense 检索模型强?
Reason-ModernColBERT 采用 Late-Interaction 架构,在检索阶段保留更多细节表达能力。与传统单向量 dense 检索模型相比:
✅ 更能捕捉复杂语义间的微妙差异
✅ 更适合处理多步、多层次的推理性问题
✅ 在不显著增加算力负担的情况下,取得大幅精度提升
🎯 应用场景:为深度研究与 Agentic RAG 而生
Reason-ModernColBERT 特别适合以下场景:
-
🤖 Agentic RAG 系统构建
-
📚 高复杂度技术/科研文献检索
-
💼 企业知识库精准查询
-
🧬 医疗、法律等高门槛领域的逻辑回溯分析
如果你遇到的问题是“知识没写在字面上”,它能帮你挖出背后的含义与关系。
🪄 重点回顾:为什么它值得一试?
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
📦 立即试用 & 下载
Reason-ModernColBERT 现已在 Hugging Face 上线,支持 PyLate 框架一键使用。附有完整文档与训练代码,适合研发者、知识管理团队、科研人员直接部署使用。
https://huggingface.co/lightonai/Reason-ModernColBERT代码 demo:
https://github.com/weaviate/recipes/blob/main/weaviate-features/multi-vector/reason_moderncolbert.ipynb论文地址:
https://arxiv.org/abs/2407.12883
(文:PyTorch研习社)