

闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
不再像CoT(“思维链”)一样“一个字一个字往外蹦”,加上“软思维”就能让大模型像人类一样进行抽象思考。
来自SimularAI和微软DeepSpeed的研究员联合提出了Soft Thinking,让模型在连续的概念空间中进行 “软推理”,而非局限于离散的语言符号,打破了基于离散token的推理瓶颈。
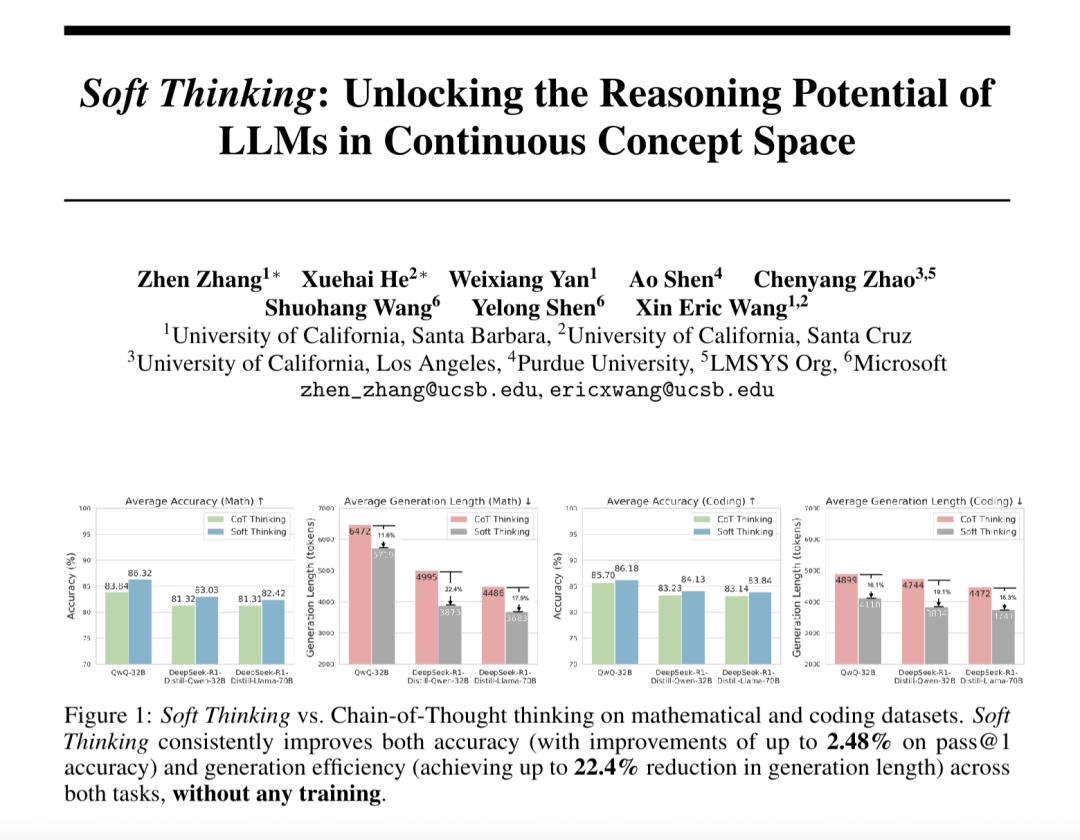
相比标准CoT,Soft Thinking最高提升Pass@1平均准确率2.48%、减少token使用量22.4%。
并且,Soft Thinking是一种即插即用的推理策略,无需额外训练即可应用于现有模型(如Llama、Qwen)。
目前主流的语言模型推理方法存在一个关键问题:只能逐字生成离散的语言符号(如单词或子词)。
这就好比思考时只能一个字一个字的蹦出来,不仅限制了模型表达抽象概念的能力,还容易在复杂问题中因“单一路径选择”而犯错。
人类大脑思考时并非依赖明确的语言符号,而是通过抽象概念的灵活整合进行推理。

Soft Thinking正是受此启发,将语言模型的推理从“离散符号空间”拓展到“连续概念空间”。
这样,模型就可以捕捉到介于仅有细微差别的语义之间的概念,能够更灵活地探索多种解题路径,同时保持高效和可解释性。
有网友表示:这种方法解决了自回归“贪婪”的next token搜索问题。

如何让模型像人类一样进行抽象思考
推理流程:在连续概念空间中 “软推理”
Soft Thinking仅修改传统CoT的中间推理阶段,保留最终答案的离散生成(如数学题的数字答案或代码的具体语句)。
Soft Thinking的理论本质是线性近似替代路径枚举。
解复杂问题时,传统CoT的推理路径数量随步骤呈指数级增长(如每步选1000个token,3步就有1000^3种路径),无法显式枚举。
Soft Thinking通过线性化近似,将指数级路径求和简化为概念token的加权计算。
用 概率加权 替代离散采样,通过连续概念空间中的线性变换,隐式聚合多条路径的信息,避免显式枚举的计算爆炸。
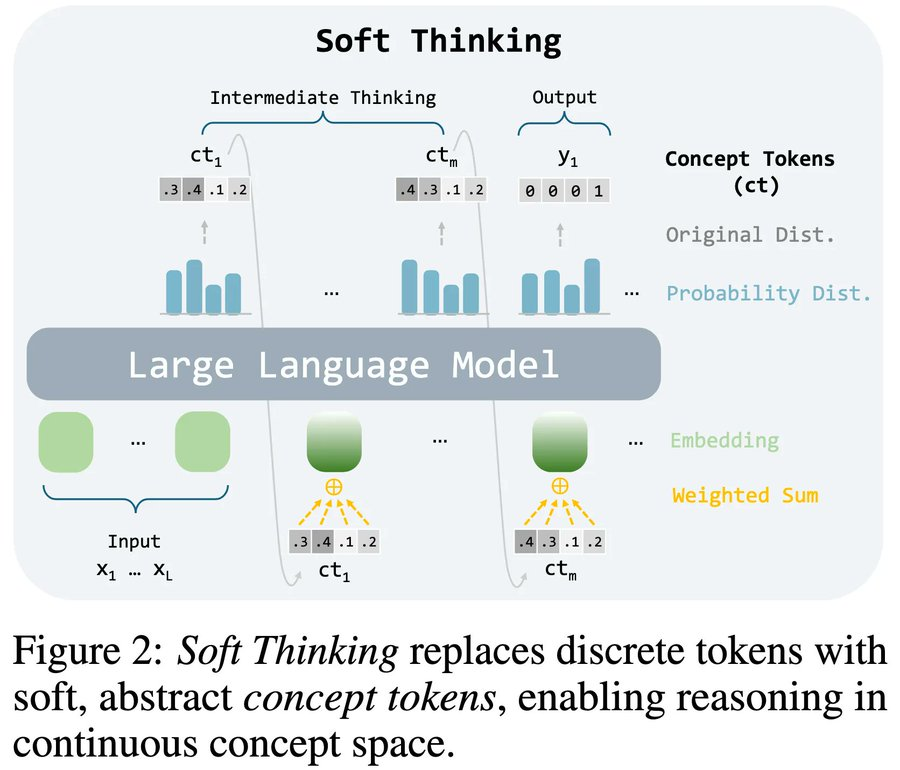
概念token:用概率分布代替单一符号
传统方法每次生成一个确定的token(如 “30”“加”),而Soft Thinking生成一个概率分布(如 “30” 的概率40%,“乘以” 的概率30%,“分解” 的概率20%等),这个分布被称为 “概念token”。
每个概念token相当于多个可能符号的 “混合体”,允许模型同时保留多种推理可能性。
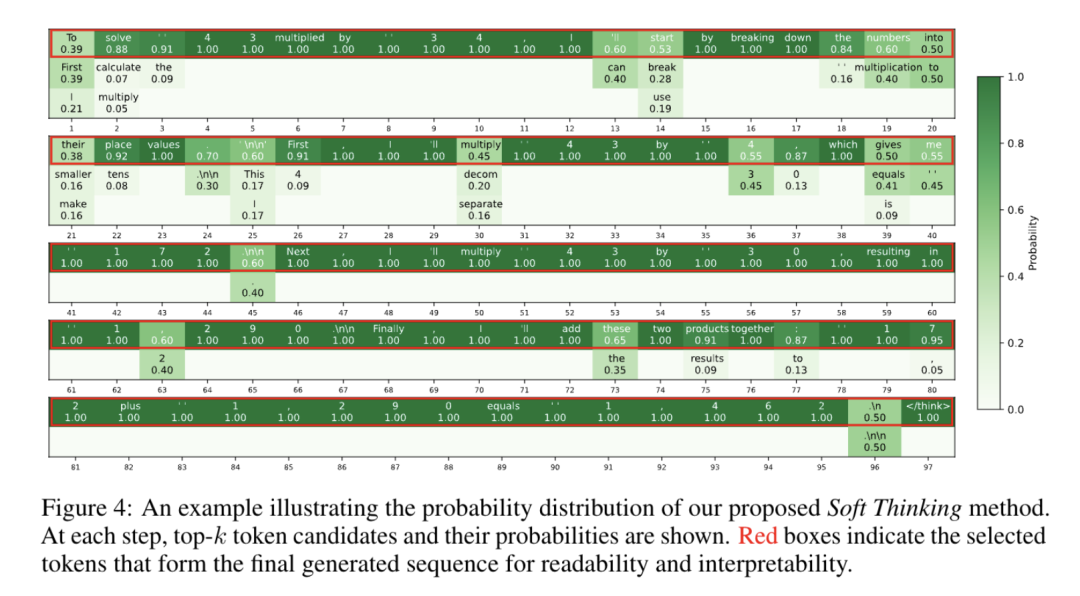
如下图中的例子,在计算“43×34”时,模型可能同时考虑“分解34为30+4”和“直接相乘”两种路径的概率,而非只选其一。

连续概念空间:在 “模糊” 的语义空间中推理
通过将概念token的概率分布与模型的词向量(Token Embedding)加权结合,形成连续的概念空间。
这里的 “连续” 意味着模型可以在不同概念之间平滑过渡,例如从“分解数字”自然过渡到“乘法运算”,而无需用明确的语言符号分隔步骤。
Cold Stop机制:避免无效循环
由于模型在训练中没见过概念token(属于 “分布外” 输入),长时间推理可能导致陷入重复或混乱(类似人类思维的 “卡壳”)。
Soft Thinking引入了一个 “Cold Stop”机制:通过监测概率分布的熵值判断模型的 “自信程度”。
当熵值持续较低时(表明模型对当前推理路径很确定),提前终止中间步骤,直接生成答案,避免浪费计算资源。
测试结果及对比
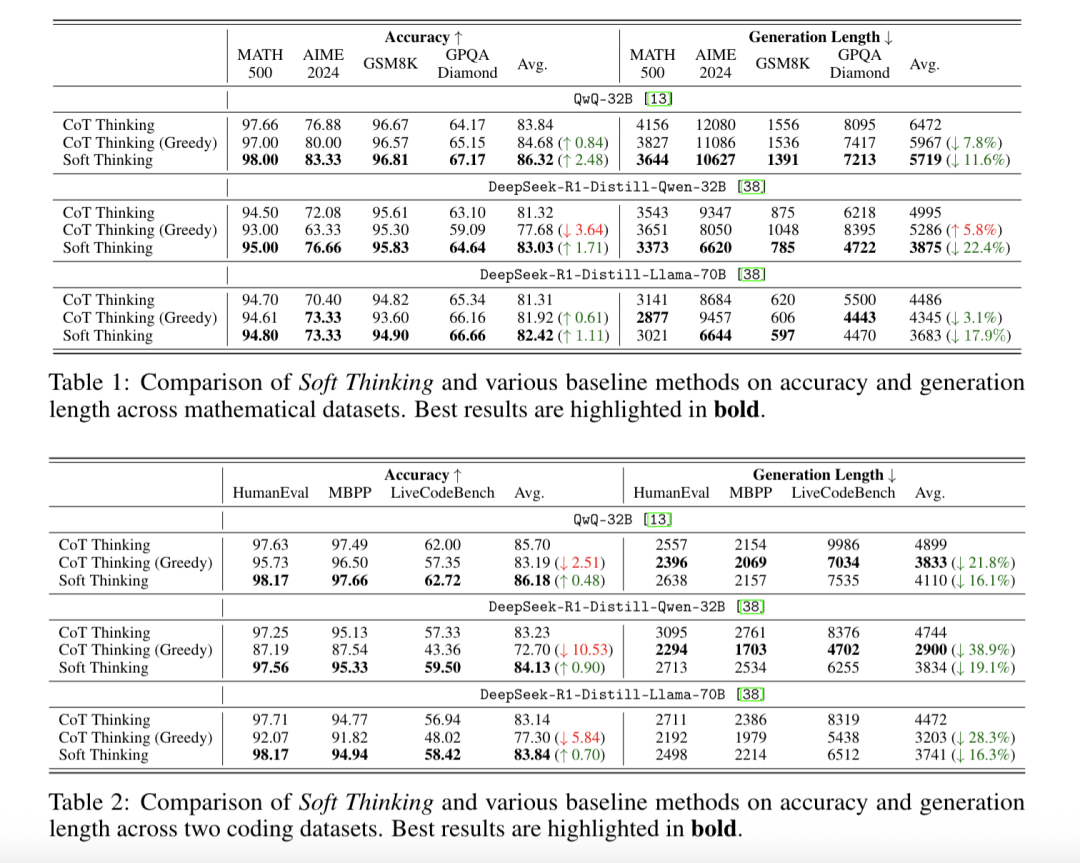
在基准测试里,QwQ – 32B模型的平均Pass@1准确率从标准CoT的83.84%提升至86.32%,最高提升2.48%,其中在AIME 2024数据集上提升6.45%。
推理效率方面,DeepSeek-R1-Distill-Qwen-32B在数学任务中token使用量减少22.4%。
与其他方法的对比
-
COCONUT-TF(无训练):直接使用隐藏状态作为输入,完全失败,生成长度达最大值且无正确解。
-
平均嵌入策略:仅计算top-5 token均值,准确率低且生成长度长(如AIME 2024仅6.66%正确)。
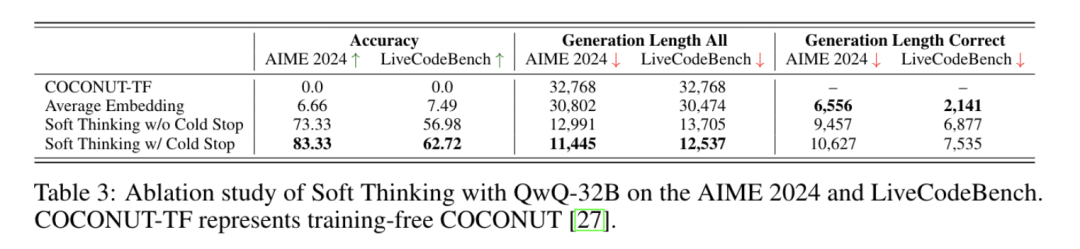
Soft Thinking通过连续概念空间推理和Cold Stop机制智能平衡了效率与准确性,为大模型优化提供了新思路。
感兴趣的朋友可以到官方了解更多细节。
官方网站:https://soft-thinking.github.io/
论文地址:https://arxiv.org/abs/2505.15778
代码地址:https://github.com/eric-ai-lab/Soft-Thinking
(文:量子位)