

MMLongBench团队 投稿
量子位 | 公众号 QbitAI
多模态长文本理解有综合性的评判标准了!
来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。

随着多模态大模型的单次推理的文本窗口快速提升,长上下文视觉-语言模型(Long-Context Vision-Language Models; LCVLMs)应运而生,使模型能够在单次推理中处理数百张图像与较长的交错文本。
但当前,由于评估多模态长文本的基准测试稀缺,现有的测试集仅关注单个任务,比如大海捞针或者长文档问答。目前尚不清楚现有的模型在长上下文环境下的综合表现,具体在哪些任务上存在短板,以及它们对不同输入长度变化的适应能力究竟如何。
MMLongBench覆盖5大类型任务的16个不同的数据集,包含13,331个长文本样本,涵盖Visual RAG、大海捞针 (needle-in-a-haystack)、many-shot in-context learning、长文档摘要和长文档VQA。同时,丰富的任务设计兼顾了多样的图像类型,既包括自然图像(如实景照片),也涵盖了各类合成图像(如diffusion生成的图片和PDF文档截图)。
该数据集还提供了跨模态长度控制:使用image patch和text token来计算上下文长度,严格标准化8K/16K/32K/64K/128K输入长度。
其评测数据集以及评测代码现已全部开源。
作者对46个领先的多模态大语言模型进行基准测试,其中包括Gemini-2.5-Pro、Claude-3.7-Sonnet、GPT-4o和Qwen2.5-VL-72B。
结果显示,无论闭源还是开源模型,在长上下文视觉-语言任务上都面临较大挑战,仍有巨大的提升空间。
此外,进一步的错误分析表明,(1) OCR能力和 (2) 跨模态检索能力仍然是当前LCVLMs在处理长文本时的瓶颈。
多任务多模态长文本测试集
多任务的数据构建
MMLongBench是一个包含了13,331个多模态长文本样例的大规模基准,涵盖五大具有挑战性的任务,分别是Visual RAG, Needle-in-a-Haystack,Many-Shot ICL,Summarization和Long-Document VQA。
这些任务旨在从多角度考察Long-Context VLMs (LCVLMs)对长文本下游任务的理解能力,提供一个完整详细的评估。
MMLongBench充分利用了现有的高质量多模态数据资源,系统性地筛选和整合了16个公开的、多样化的多模态数据集。所有问题和答案均来源于原始数据集。为了支持长上下文能力的评估,作者对原始数据进行了上下文长度控制,将原本较短的样本扩展至8K-128K token的上下文长度,并将较长样本进行截断,以适配不同长度的测试需求。
例如在Visual RAG任务中,研究团队从Wikipedia中检索与问题相关的段落,将其拼接为长上下文,以模拟真实的Visual RAG应用场景。同时,在summarization任务中,作者选用长PDF文档作为输入,并对文档末尾进行截断,以满足不同上下文长度的需求。
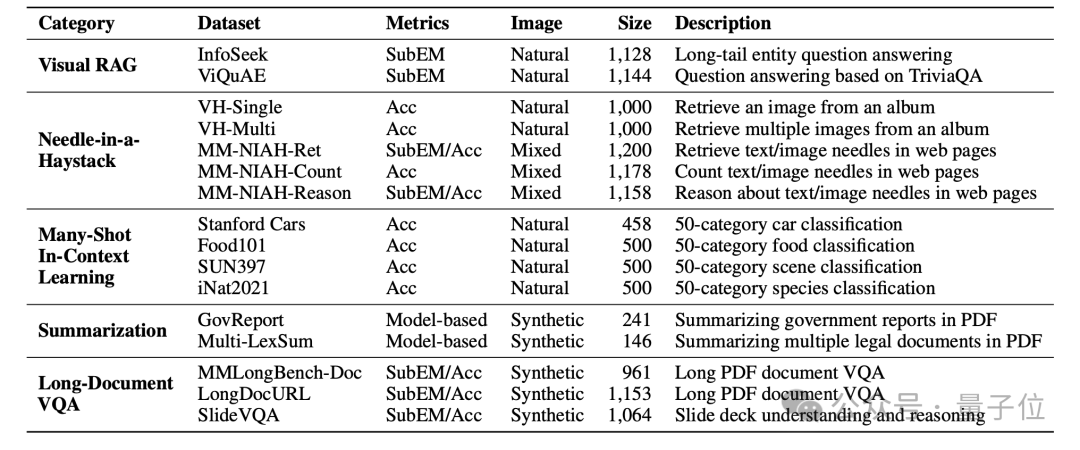
跨模态长度控制
现有多模态长文本数据集通常以图片数量作为样本长度的衡量标准,而忽略了不同图片的尺寸差异以及问题中的文字内容。为了统一不同数据集的样本长度,MMLongBench将文本Token和图片patch共同计入总输入长度,而不是仅以图片数量粗略衡量样本长度。
具体来说,作者采用Llama2的分词器计算文本token数量,并将每张图片划分为14×14的patch,同时应用2×2的pixel unshuffle操作以压缩视觉token数量。这种处理方式兼容当前主流的多模态大模型,例如Qwen2.5-VL和InternVL3,能够更真实地反映不同样本的实际输入长度,也使跨数据集的评估更加公平和标准化。
同时,MMLongBench为每个样本都提供了8K、16K、32K、64K和128K五种长度的上下文,便于分析模型在不同长度下的表现变化。此外,这一设计也支持进一步扩展至更长的输入长度,满足未来模型发展需求。
总体来说,通过多任务的数据构建和跨模态长度控制,MMLongBench为当前多模态大模型的长文本能力提供了更加完整和细致的评估。以下是MMLongBench和现有数据集的对比:
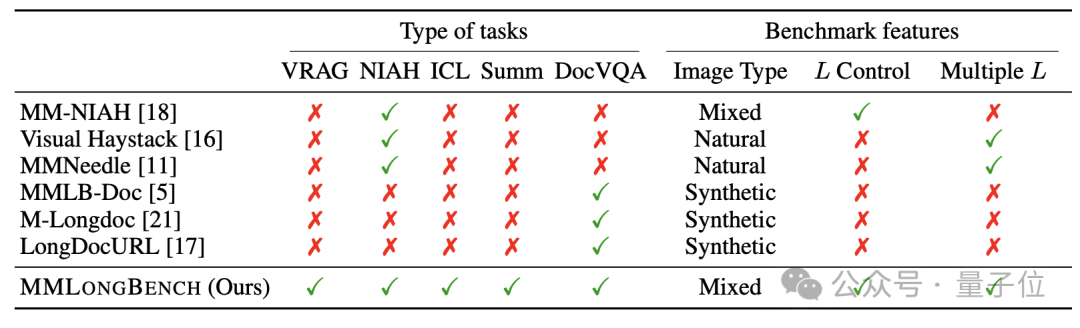
性能评估
研究团队对46个领先的LCVLMs进行了全面评估,其中包括闭源模型Gemini-2.5-Pro、GPT-4o、Claude-3.7-Sonnet,以及多种开源模型,例如Qwen2.5-VL-72B、InternVL3-38B。结果发现,无论是闭源还是开源的多模态大模型,在长上下文视觉-语言任务上都面临较大挑战,仍有巨大的提升空间。
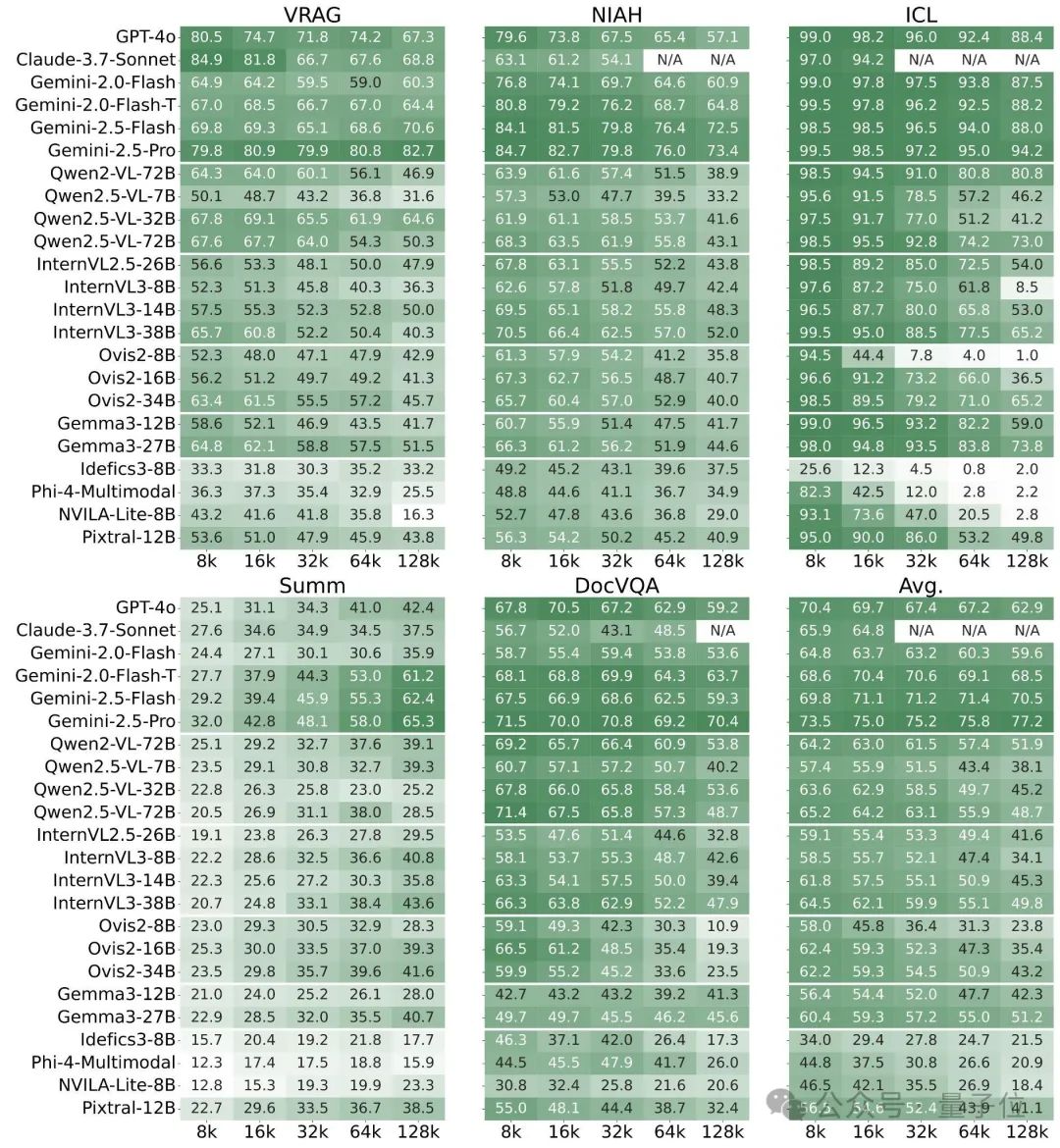
发现1:所有模型在长上下文视觉-语言任务上都面临较大挑战
总体来看,所有模型在长上下文任务上都表现不佳。在128K token长度下,InternVL3-38B、Qwen2.5-VL-72B和Gemma3-27B这些顶尖的开源多模态大模型获得的平均分仅为49.8、48.7和51.2。GPT-4o的平均分也只有62.9,并且得分最高的闭源模型Gemini-2.5-Pro也没有超过80分。
发现2:推理能力更强的模型往往在长上下文任务中表现得更好。
团队在评测中引入了 Gemini-2.0-Flash-T (gemini-2.0-flash-thinking-exp-01-21),它是 Gemini-2.0-Flash 的推理版本。从结果来看,推理能力能够在所有任务上持续提升 Gemini-2.0-Flash的表现。在summarization和DocVQA任务上的提升则分别达到了25.3%和10.1%。此外,Gemini-2.5系列模型作为原生的推理模型,表现则更为强劲。
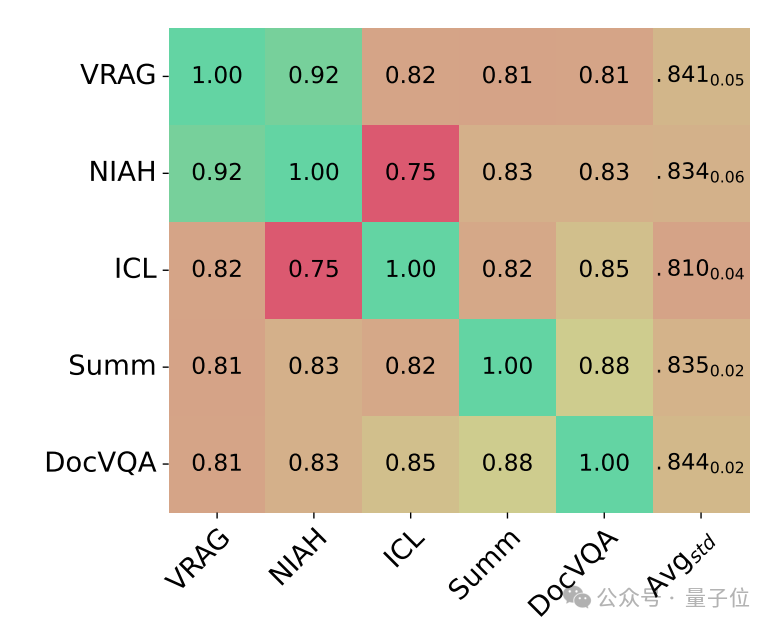
发现3:单一任务的性能难以有效反映模型的整体长上下文能力
基于模型的分数,研究团队计算了不同任务之间的 Spearman 相关系数。结果发现,不同类别之间的相关性普遍不高(低于0.85)。这表明,仅依赖单一任务的性能难以全面反映模型的整体长上下文理解能力,也进一步证明了MMLongBench采用多样化下游任务进行评估的必要性。
错误分析 (Error Analysis)
研究团队进一步针对模型在Long-Document VQA和Visual RAG任务上的表现进行了分析。
1. OCR能力是处理长文档输入时的瓶颈
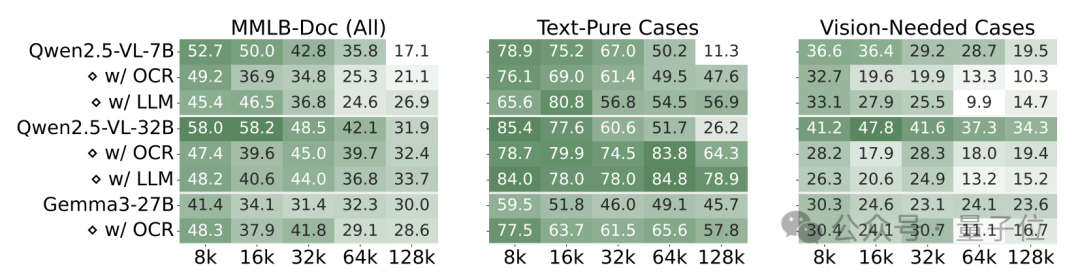
研究人员将PDF格式的文档通过OCR技术转化为纯文本(w/ OCR),再输入到模型当中。总体来看,使用图像格式的PDF文档输入和OCR提取的纯文本输入并没有绝对的优劣。Qwen2.5-VL系列模型在大多数情况下对图像格式的PDF文档处理效果更佳,而Gemma3-27B则在较短输入长度(≤ 32K)时更偏好纯文本。
此外,研究团队还根据答案来源将样本细分为两类:纯文本 (text-pure) 和需要视觉理解 (vision-needed) 的样本。结果显示,在需要视觉理解 (vision-needed) 的样本上,模型使用图像格式的PDF文档输入能够获得更高的分数;而在纯文本 (text-pure) 样本上,尤其是在64K和128K的长输入下,OCR提取的纯文本输入能带来更好的效果。同时,当使用OCR提取的文本时,将LCVLMs替换为相应的纯文本大语言模型 (Qwen2.5-7B和Qwen2.5-32B,图中为w/ LLM),在text-pure样本上能获得更好的效果。
这表明,当前LCVLMs在处理长文档输入时,OCR能力仍然是一个瓶颈。未来的工作可以考虑结合两种输入以进一步提升性能。
2、跨模态检索能力限制长文本表现
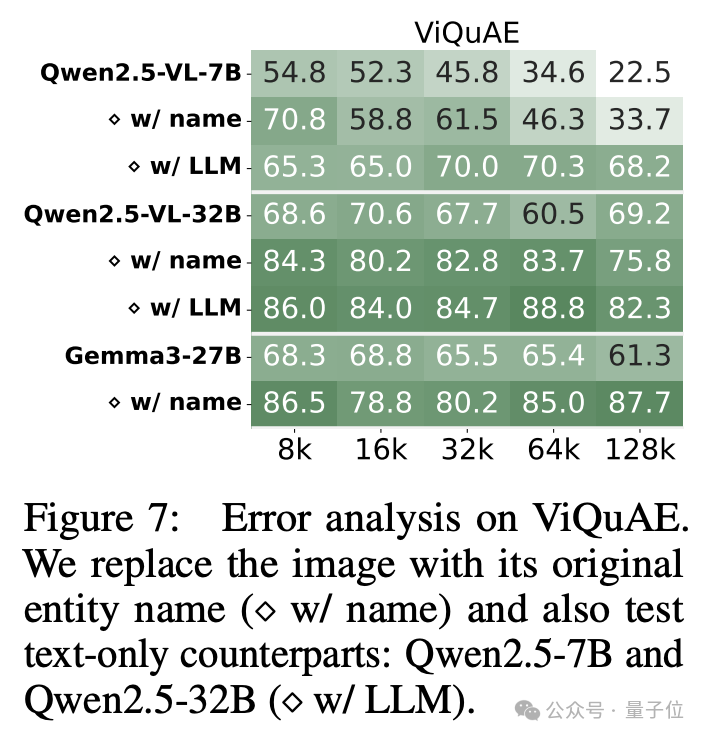
研究团队还对现有模型在Visual RAG任务中的错误来源进行了分析。研究团队将ViQuAE (Visual RAG任务中的数据集) 中的图片替换为对应命名实体的名称,从而所有样本都变为纯文本输入 (w/ name)。将这些纯文本的问题输入到LCVLMs中,结果显示,所有模型的表现都有不同程度的提升,其中Gemma3-27B在128K长度下提升最大,达到了26.4。这表明现有的LCVLMs在跨模态信息检索方面存在瓶颈限制长文本能力。
此外,将这些问题输入到Qwen2.5-VL对应的LLMs当中 (Qwen2.5-7B和Qwen2.5-32B,图中为w/ LLM), 也能提升模型表现。这说明在LCVLMs训练过程中,多模态能力与纯文本的长上下文能力之间存在tradeoff。
论文:
https://arxiv.org/abs/2505.10610
主页:
https://zhaowei-wang-nlp.github.io/MMLongBench-page/
代码:
https://github.com/EdinburghNLP/MMLongBench
数据集:
https://huggingface.co/datasets/ZhaoweiWang/MMLongBench
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)