


你是否曾幻想过,只需要给 AI 一张草图、一段动作序列,甚至一个相机运动轨迹,它就能生成符合所有条件的视频?这个梦想,已经成为现实!
快手与新加坡国立大学联合推出的 Any2Caption,打破了多模态条件与视频生成之间的壁垒,让用户的创意指令不再受到技术限制,轻松实现精准、可控的视频创作。

论文标题:
Any2Caption : Interpreting Any Condition to Caption for Controllable Video Generation
论文链接:
https://arxiv.org/pdf/2503.24379
项目地址:
https://sqwu.top/Any2Cap/
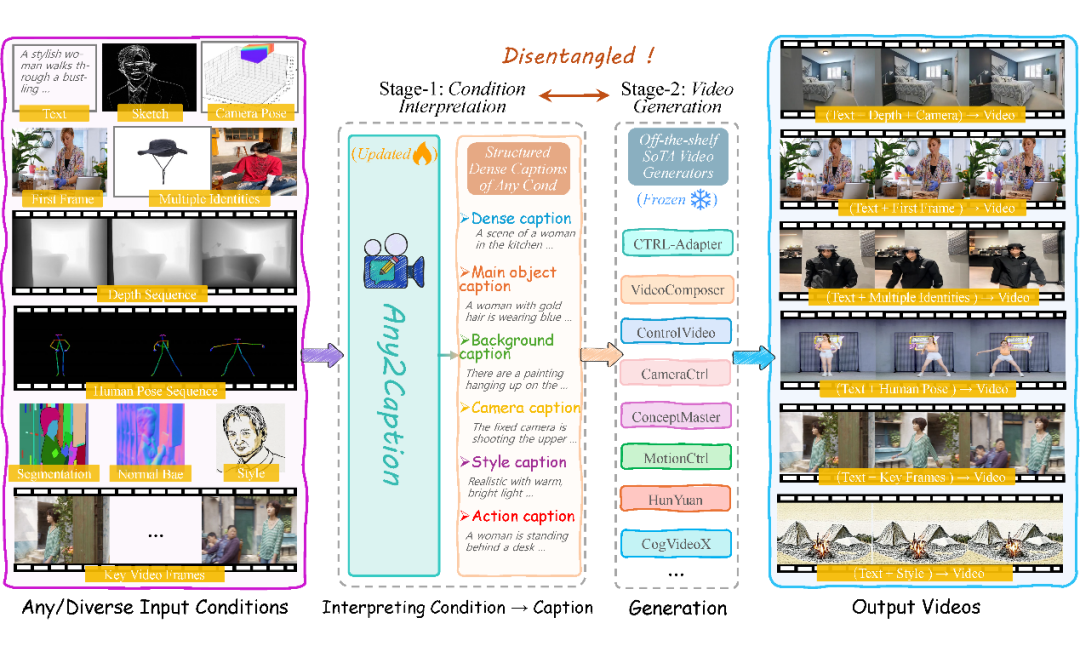
研究动机与主要贡献:
1. 在视频创作领域,如何精准理解用户需求一直是个难题:
-
简洁指令中的生成意图难以把握:现有的视频生成方法依赖精细的结构化提示词来提升生成质量,但用户实际操作时往往提供简洁的指令,造成生成效果的不尽如人意。如何在保持交互自然性的同时,准确捕捉用户的创作意图,是实现高质量视频生成的核心挑战。
-
多模态指令的语义解析困难:为了实现更细粒度的可控视频生成,用户通过提供多模态条件(如文字、图像、姿态等)来表达创作意图,但现有方法依赖生成模型的内部编码器解析复杂输入,常常无法有效理解其语义组合,限制了生成效果的质量,难以满足真实应用需求。
2. 核心贡献:
-
智能解耦“用户意图理解”与“视频生成”:先解析用户需求,再生成视频,避免“理解偏差”
-
全能输入,全面理解:文字、图片、视频,姿态轨迹,甚至专业参数(如镜头运动、拍摄角度)都能“听懂”
-
AI 大脑赋能,指令转化为视频脚本: 通过构建强大的多模态大语言模型,将复杂指令转化为精准,结构化的“视频脚本”,指引生成过程更可控、更高效。

框架解析
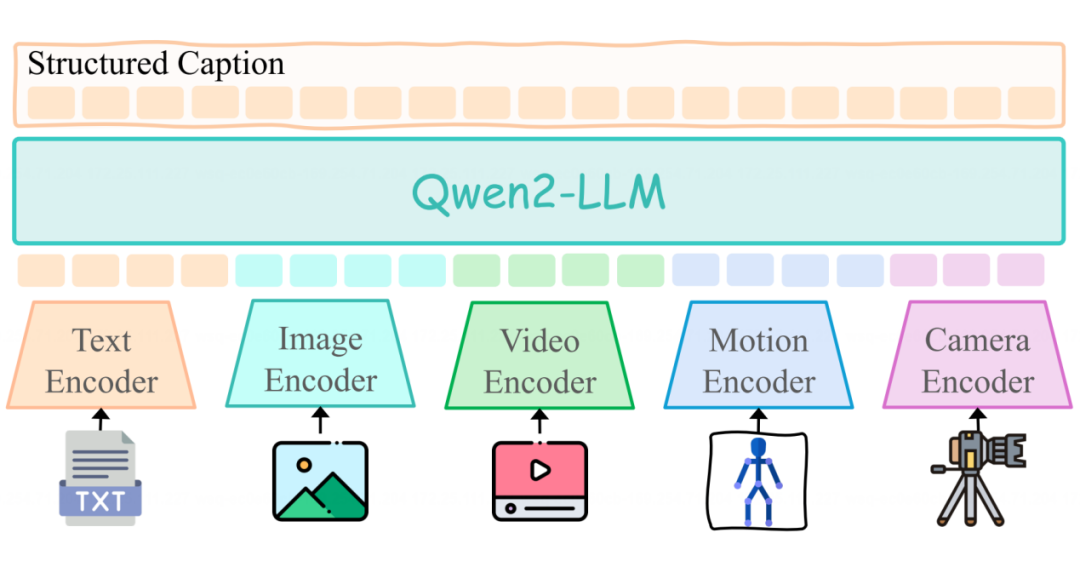
就像现有的多模态大语言模型一样,Any2Caption 的前端也通过一系列专门的编码器,巧妙地解码来自不同模态的控制条件。我们有图像编码器、视频编码器、姿态轨迹编码器和相机运镜编码器等,每一种都能高效捕捉并处理独特的信息。
当这些多样化的视觉信息经过编码后,它们将进入一个强大的大语言模型,进行深度解析,最终输出一个细致入微、结构化的“视频脚本”。这个脚本涵盖了视频创作的六大关键元素:
1. 密集描述:细腻描绘目标视频的场景,每个小细节都不容忽视。
2. 主体对象描述:精确定义视频中的核心对象,并详细列出其各项属性。
3. 背景描述:展现视频中环境的独特氛围与背景。
4. 相机运镜描述:描述镜头如何在空间中运动 。
5. 风格描述:从色调到氛围,描述目标视频的独特的视觉风格 。
6. 动作描述:深入描绘对象的动态过程。


数据后盾
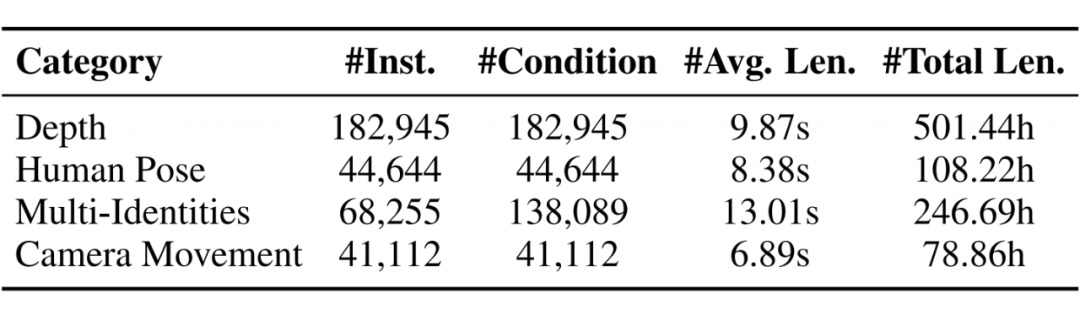
为了实现精准的视频生成,Any2Caption 依托超大规模训练数据库 Any2CapIns,它包含了 33.7 万个视频实例和 40.7 万个多模态条件。
步骤1 — 数据收集:我们收集了 337K 个视频实例,并利用当前最先进的技术工具,构建了多模态条件,包括深度图、姿态轨迹、相机运镜、多参考图等。每一个细节都为后续生成提供了强大的数据支撑。
步骤2 — 结构化视频脚本生成:通过现有的工具,我们独立生成了视频脚本的每个部分,并进行整合,最终构建出结构化的视频脚本。为了确保每个部分的精准度和高质量,我们还引入了人工检查,进一步提升了脚本的生成效果。
步骤3 — 以用户为中心的简短提示生成:在构建简短提示时,我们从用户自然表达的角度出发,注重简洁而精准的沟通,确保生成的提示既符合用户意图,又能够与系统高效交互。
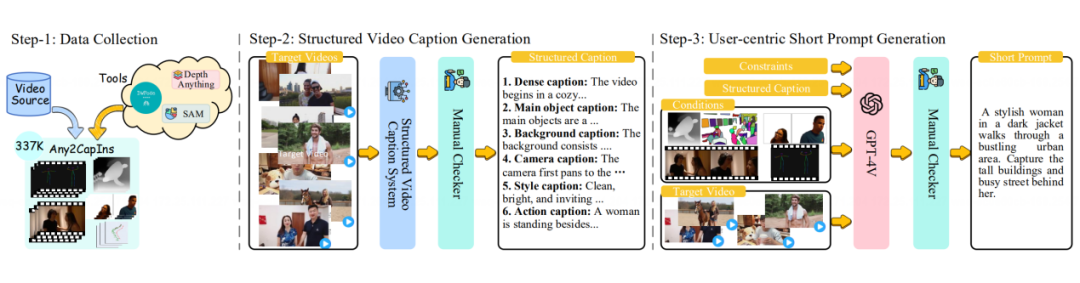
最终,经过这一系列严谨的步骤,我们得到了如下的规模的数据集:

训练秘籍
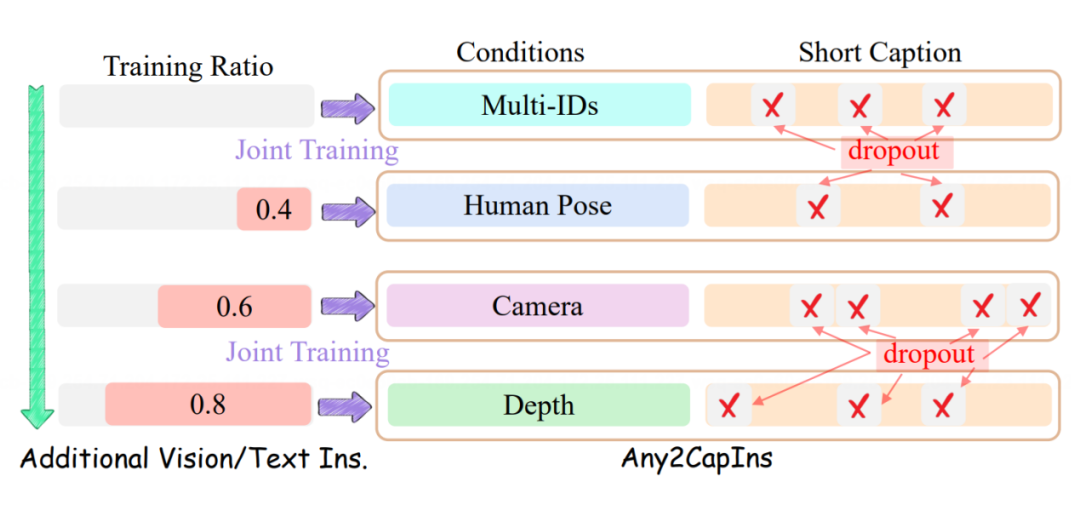
Any2Caption 训练分为两大阶段,确保精准生成多模态视频脚本。
首先,对齐学习。
我们冻结大语言模型和视觉编码器,专注优化运动编码器(人体姿态与相机运动特征),确保它们与大语言模型高效对齐,为多模态条件的表征打下基础。
其次,多模态条件理解学习。
采用渐进式混合训练策略,首先在单一条件下训练模型,再逐步引入视觉-语言指令(如 LLaVA、Alpaca-52K),防止灾难性遗忘,确保稳健的多模态解读。

实验结果
4.1 视频脚本生成质量分析
生成结构化视频脚本准确度
我们通过将模型生成的结构化描述直接输入到视频生成系统(如 CogvideoX – 2B 和 Hunyuan Video)进行测试,发现即使没有明确的视觉条件(如人物身份、景深或相机移动),生成的视频仍然与输入提示高度契合。
举例来说,example-1 中帽子的颜色和款式,或女性服装的质地,都准确地反映了输入描述,表明我们的结构化描述成功捕捉了复杂的视觉细节。
特别地,模型能够精确理解像景深序列或相机运镜要求这样的复杂条件,确保生成视频具备高可控性。虽然某些细节可能无法完美呈现,偶尔会出现与实际视觉内容的细微差异,但整体上,生成效果依然非常符合预期。

复杂指令理解性能
Any2Caption 展现了卓越的复杂指令处理能力,尤其是在理解用户意图方面。从图 1 可以看出,模型能够精准抓取用户指定的核心元素,比如“女战士”或“充满混乱与毁灭”的背景,生成清晰的结构化标题。
与此相比,直接的参考图描述往往会包括一些不必要的背景细节,容易偏离用户的创作意图,影响最终生成的视频效果。
我们还测试了模型在处理隐性指令时的表现,如图 2 和图 3 所示。模型能够准确解读诸如“最右侧的人”这样的短语,将其转化为“一个年轻的黑人女性,拥有长卷的棕色头发,穿着黑白相间的衣服”,并结合给定条件生成符合用户目标的结构化视频脚本。

▲ 图1

▲ 图2

▲ 图3
4.2 消解实验
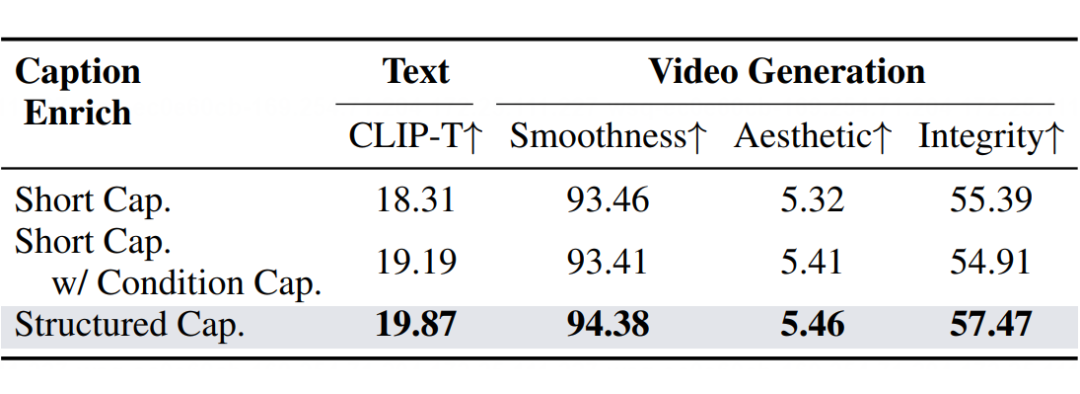
结构化脚本描述的必要性
通过与简化方法的比较——即将多个参考图像的描述与简短用户 prompt 提示拼接——我们发现,单纯附加条件描述会降低视频的流畅度和图像质量。原因可能在于参考图像中包含了不相关的细节,容易与原始提示冲突,影响最终输出的可控性。
相反,结构化描述通过精确识别目标主体,并通过相关信息强化提示,确保了更高的可控性和精准的视频生成。
训练策略的优势
我们发现,如果省略对齐学习,模型在指令微调后,字幕生成和视频生成的表现都会显著下降。一个可能的原因是跳过对齐学习会干扰编码器与大语言模型(LLM)的有效对齐,导致后续效果不佳。
此外,我们还测试了去除丢弃机制后的模型表现,虽然字幕生成质量有所提升,但对视频生成并无太大帮助,这表明没有丢弃机制时,模型可能会过于依赖输入的提示,而不是深入理解用户意图,增加了过拟合的风险。

4.3 视频生成质量分析
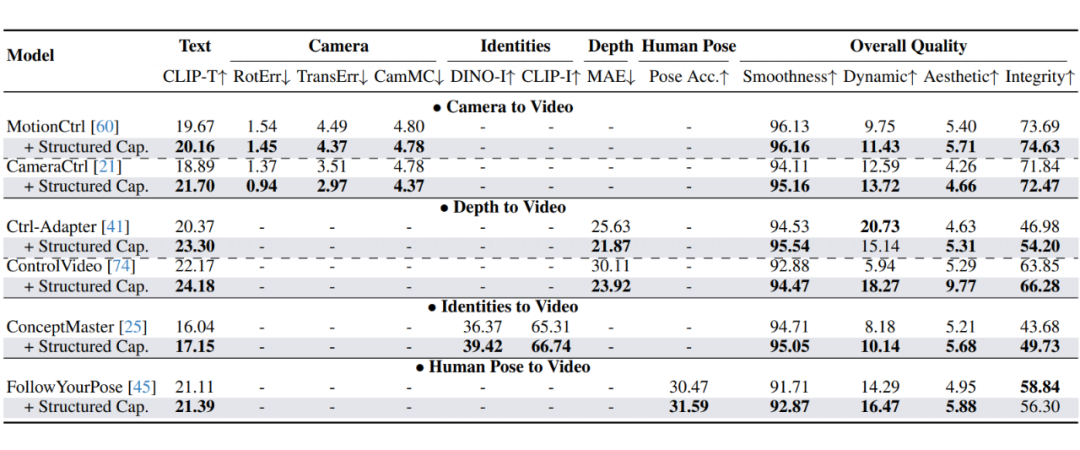
单条件生成质量分析
我们研究了添加相机、深度图像、多参考图和人体姿态条件对可控视频生成的影响。如下表所示,所有测试模型在整合结构化描述后,无需架构更改或额外训练,整体视频质量(如流畅度和帧保真度)都显著提升。
组合条件生成质量分析
我们还探讨了结构化字幕在组合条件下的作用。如下表所示,结构化字幕始终提升了模型在相机、身份和深度组合条件下的表现。同时,我们的研究表明,结构化字幕能让现有文本到视频(T2V)模型处理组合条件,而无需额外训练。
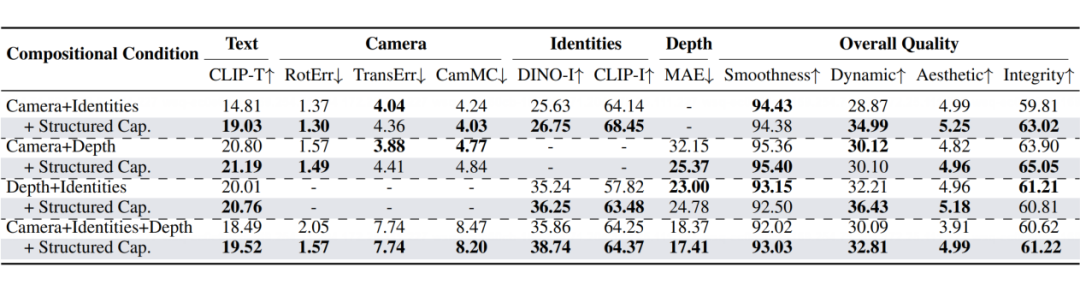
这里我们使用了《FullDiT: Multi-Task Video Generative Foundation Model with Full Attention 》文章中的多模态控制视频生成基础模型作为基准,FullDiT 使用统一化表征进行各类控制信号的编码,在序列维度上将控制信号连接并输入 DiT 模型,利用 self-attention 的强上下文学习能力最大化信号控制效果和生成质量。
值得注意的是,虽然 FullDiT 基础模型本身已可以达到优于过往方案的控制和生成效果,使用 Any2Caption 模型得到的结构化文本指令仍能在无需额外训练的前提下带来较大提升。
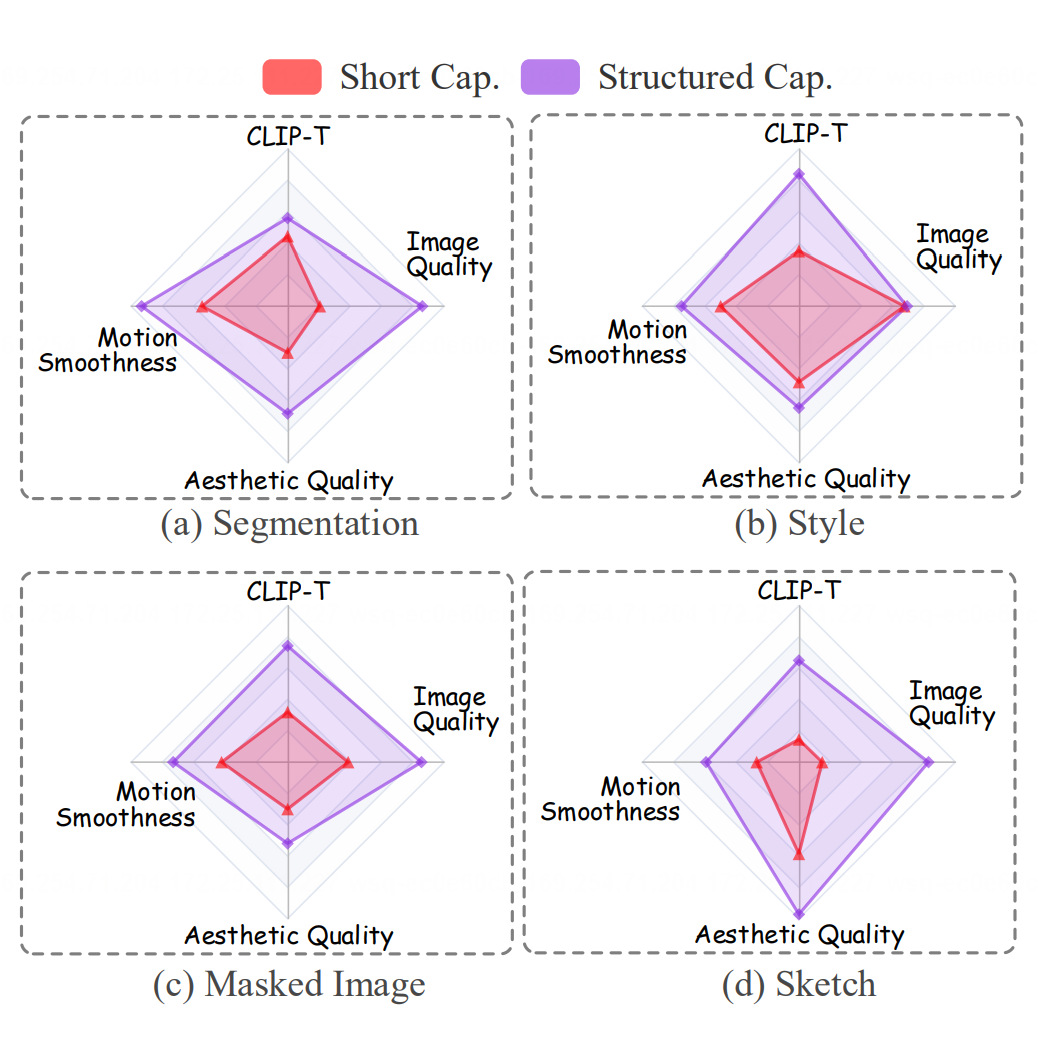
泛化能力分析
我们进一步评估了模型在“未见”条件下的表现,如风格、分割、草图和掩码图像。结果如图 6 所示,模型生成的结构化字幕显著提升了现有 T2V 框架,改善了运动平滑度、美学质量和生成控制的精准度。
我们将这些优势归功于我们多模态大语言模型(MLLM)的强大推理能力,以及渐进式混合训练策略,该策略通过微调现有的视觉和文本指令,有效减轻了知识遗忘,确保了出色的泛化能力。

结论
我们创新性地提出了 Any2Caption 框架,智能解耦用户意图理解以及视频生成,实现将任意复杂多模态指令理解翻译为精准的,结构化视频脚本,提升视频生成的可控性与生成质量。
我们构建了大规模的指令数据集 Any2CapIns,包含 33 万+案例和 40 万+条件组合。
大量实验表明,我们的方法可提高各种现有可控视频生成模型的可控性和视频质量。
(文:PaperWeekly)