

金磊 发自 凹非寺
量子位 | 公众号 QbitAI
昨天的文章已经提到,昇腾超大规模MoE模型推理部署技术在本周会有持续的技术披露,果然第二天的技术报告又如期而至了。前情提要:《华为+DeepSeek,推理性能创新高!技术报告也公布出来了》
要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。
它的巧妙之处,就在于把不同的任务分配给擅长处理的专家网络,让整个系统性能得以提升。
但你知道吗?
正是这个关键的专家网络,也是严重影响系统推理性能的因素之一。
因为在大量任务来临之际(尤其是超大规模时),MoE并不是以“雨露均沾”的方式去分配——专家网络们的负载均衡问题,就会显得尤为突出。

这个问题的根源,是因为某些专家网络总是被频繁调用(热专家),而另一些专家网络则鲜有机会派上用场(冷专家)。
没错,MoE里的“专家们”也是有冷热之分的,而且被调用频率的差距甚至可以达到一个数量级以上!
如此负载不均衡的现象,就会导致整个系统推理的时间被延长,以及还有资源利用率、系统性能受限等问题。
那么此局又该如何破解?
别急,华为团队已经给出了一种有效解法,直接让DeepSeek-V3在理论上的推理延迟可降低约10%、吞吐量可提升约10%。
值得一提的是,团队还将在近期准备把这个解法全面开源了;那么接下来,我们就来深入了解一下。
华为的刀法:OmniPlacement
针对专家们冷热不均的问题,华为优化的刀法,叫做OmniPlacement。
简单来说,它的工作原理是这样的:
通过专家重排、层间冗余部署和近实时动态调度,显著提升MoE模型的推理性能。
具体可以分为三步走:
第一刀:基于计算均衡的联合优化
在这一步中,华为团队通过分析专家的活跃度(激活数据),先是识别出了忙碌的热专家和清闲的冷专家。
然后将提出的一种基于计算均衡的联合优化算法OmniPlacement用了上去。
这个算法会根据专家调用频率和计算需求来优化部署的顺序,这样就会显著降低负载不均的现象。
具体来说,OmniPlacement算法的特点如下:
-
动态优先级调整:通过实时统计专家调用频率,动态调整专家的优先级和节点分配,确保高频专家优先部署在计算能力较强的节点上。 -
通信域优化:算法分析批次内激活卡数,优化跨节点通信域的范围,减少通信延迟。相比传统的静态分配方法,本算法显著降低了通信开销。 -
层间差异化部署:允许不同层根据负载特性设置不同的专家部署策略,支持非均匀冗余次数配置,从而更好地适应层间负载差异。
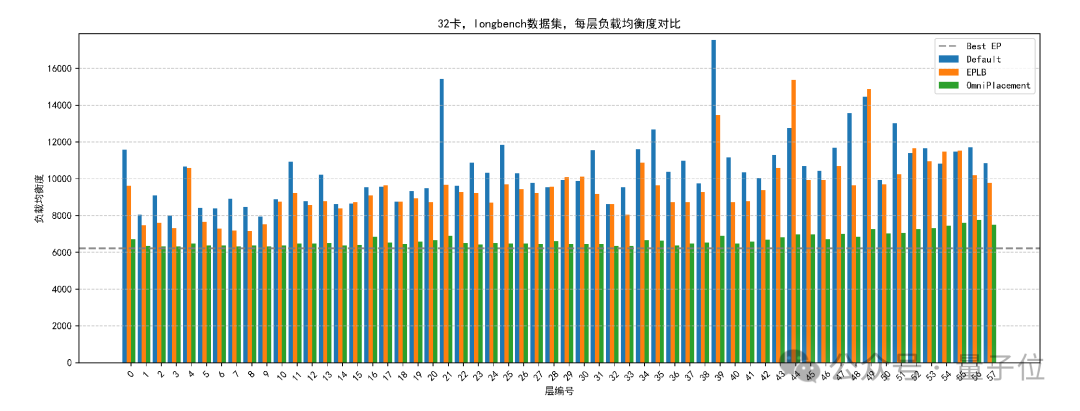
△相同数据条件下,EPLB与OmniPlacement算法,每层设备最大激活数理论对比
第二刀:层间高频专家冗余部署
刚才的步骤是面向冷热专家整体,那么这一步则是剑指热专家。
为了缓解热专家的压力,华为团队还提出了一种层间冗余部署的策略——
通过为高频调用专家分配额外的冗余实例,降低跨节点通信开销,从而提升系统吞吐量。
这个策略的创新点在于:
-
动态资源分配:根据实时计算资源占用情况和专家调用频率,动态调整冗余实例的分配比例。系统通过预测模型提前分配资源,减少冷热专家间的性能差距。 -
层间差异化配置:不同层根据负载需求设置不同的冗余次数,增强对层间负载差异的适应能力。例如,高负载层可分配更多的冗余实例,而低负载层则减少冗余以节省显存。 -
预测性分配:结合历史激活数据和负载预测模型,系统能够提前优化资源分配,降低突发负载对系统性能的影响。
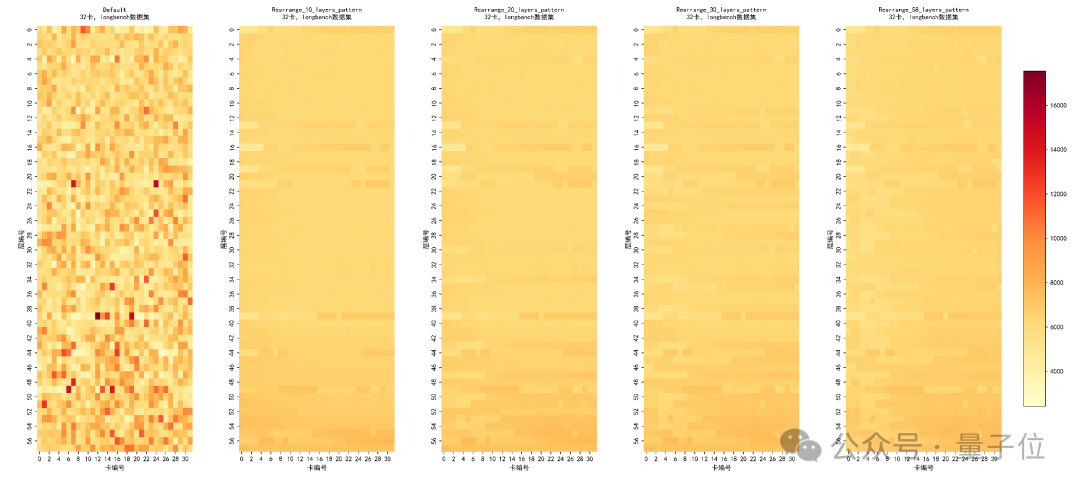
△冗余不同层数排布的理论热力图
第三刀:近实时调度与动态监控机制
为了让系统能更灵活地应对各种变化,在实际运行中快速做出反应,研究团队设计了一套类似 “智能管家” 的方案——
近实时调度与动态监控机制。
其具体包含的子模块如下:
-
近实时调度:通过实时统计数据流特性,动态调整专家分配以适应输入数据的变化。调度算法能够在毫秒级时间内收敛到优化的静态专家部署模式,确保推理过程的高效性和一致性。该机制通过迭代优化专家分配,显著降低了动态调整的计算开销。 -
动态监控:实时跟踪专家激活数据和系统资源占用情况,为调度决策提供准确依据。监控任务在独立的计算流中运行,避免对推理主流程的干扰,保障系统整体效率。 -
动态专家权重访问与摆放:通过层间流水线设计,实现专家权重和分配的动态调整。系统在推理过程中并行处理权重更新和数据流分配,支持高效的专家动态摆放。流水线设计允许在不中断推理流程的情况下完成权重调整,显著降低高负载场景下的推理延迟。
这套机制通过两个关键设计大幅提升了系统性能:
首先采用多任务并行处理技术,让系统反应更快、调整更灵活;其次独创性地将监控和调度功能分开运行。
这样既保证了实时监控的准确性,又避免了监控程序拖慢系统速度,使整个系统运行更加稳定可靠。
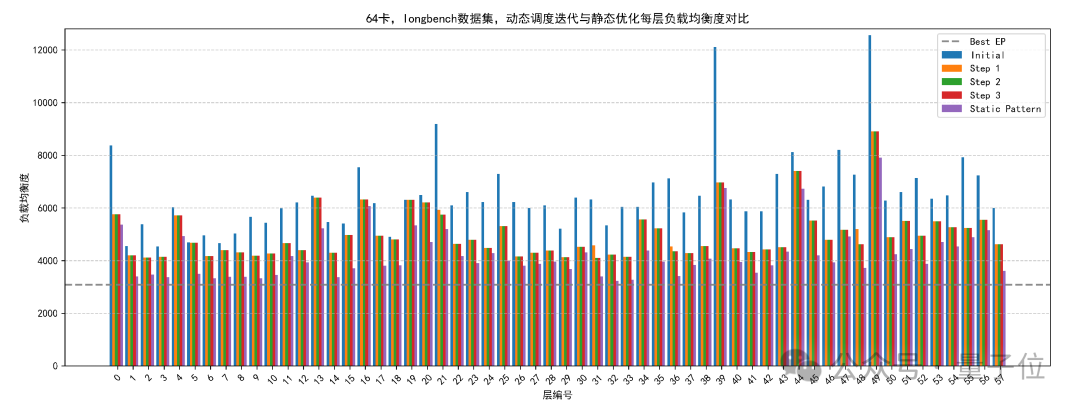
△近实时调度理论效果与收敛性
为了支持上述技术的稳定运行,团队还开发了适用于vLLM的推理优化框架OmniPlacement,其核心特点如下:
-
高兼容性:框架支持多种MoE模型架构,能够无缝集成到现有的推理系统中。 -
低时延开销:通过优化数据处理和调度流程,框架显著减少了额外计算开销,确保推理性能不受影响。 -
模块化设计:框架包含数据统计、算法运行和专家调度三大模块,各模块功能解耦,支持功能扩展和维护。模块化设计便于快速迭代和定制化开发。 -
可扩展性:框架支持动态添加新的负载均衡算法和调度策略,适应未来MoE模型的复杂需求。
OmniPlacement采用模块化设计,把核心算法和推理流程分开处理,就像把汽车的发动机和控制系统分开优化一样。
这样设计有两个突出优势:
一是专门负责任务调度的模块可以独立工作,不会干扰主系统的运行效率;二是整个框架可以根据不同需求灵活调整,为大型AI模型的稳定运行提供了坚实的底层支持。
DeepSeek V3系统延迟理论可直降10%
在了解完华为的“刀法”之后,我们再来看下“疗效”。
华为团队把这套优化方法在DeepSeek-V3上进行了全面验证,实验环境包括多节点GPU集群和高并发推理场景。
得到了如下的测试结果:
-
推理延迟:相比基线方法(未优化负载均衡的MoE模型),推理延迟平均降低约10%。延迟的减少主要得益于动态专家分配和通信域优化,显著改善了用户体验。 -
吞吐量:系统吞吐量提升约10%,反映了资源利用率的显著提高。特别是在高并发场景下,冗余部署和动态调度有效缓解了负载瓶颈。 -
系统稳定性:在动态输入和高负载场景下,系统保持高效运行,未出现性能波动或服务中断。动态监控机制确保了系统对突发负载的快速响应。

△OmniPlacement与基线和BestEP的性能对比
进一步的分析表明,OmniPlacement在不同规模的MoE模型和输入数据分布下均表现出良好的适应性。
并且从实际测试证明来看,它不仅能大幅提升运算效率,还能更合理地利用计算资源,同时保持系统稳定运行。
这为今后在实际应用中部署大型MoE模型提供了坚实的技术保障。
最后值得一提的是,华为团队不仅是发布优化方案这么一个动作,更是要将这个方法在近期全面开源。
完整技术报告:
https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/OmniPlacement/OmniPlacement-%E6%98%87%E8%85%BE%E8%B6%85%E5%A4%A7%E8%A7%84%E6%A8%A1MoE%E6%A8%A1%E5%9E%8B%E6%8E%A8%E7%90%86%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1%E6%8A%80%E6%9C%AF%E6%8A%A5%E5%91%8A.pdf
技术博客:
https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/OmniPlacement/ascend-inference-cluster-omniplacement.md
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
(文:量子位)