

在这个大模型爆发的时代,从写代码、生成图像,到撰写报告、构建多模态系统,AI 正逐步成为技术人的第二大脑。然而,有一个关键问题常常被忽视:模型装好了,怎么高效地部署和服务?
是的,单机推理还算简单,但当你需要支撑 Web API、大量并发请求、低延迟响应、多用户隔离、LoRA 热插拔……你就会发现,部署一个大型语言模型(LLM)或者视觉语言模型(VLM),不仅仅是“模型 + 显卡”这么简单。
今天这篇文章,我们就来扒一扒当前大火的三种大模型服务方案:VLLM、LLaMA.cpp HTTP Server 和 SGLang,每一个都号称“快、稳、省资源”,但它们到底有什么不同?分别适合什么场景?有哪些坑要避?本文将为你一一揭晓。
01|VLLM:大厂也在用的吞吐怪兽,GPU 推理首选
如果你关注 HuggingFace、Mistral、OpenChat 等社区项目,就一定见过 VLLM 的身影。这个由 UC Berkeley 和 SkyLab 团队开源的项目,主打一个字:快!

VLLM 最大的杀手锏就是它的独门技术 —— PagedAttention,通过内存分页管理和连续批处理机制,它几乎把 GPU 的带宽榨干,带来了极致的并发性能。加上支持 tensor 并行、管道并行、流式输出,它成为高性能推理的事实标准之一。
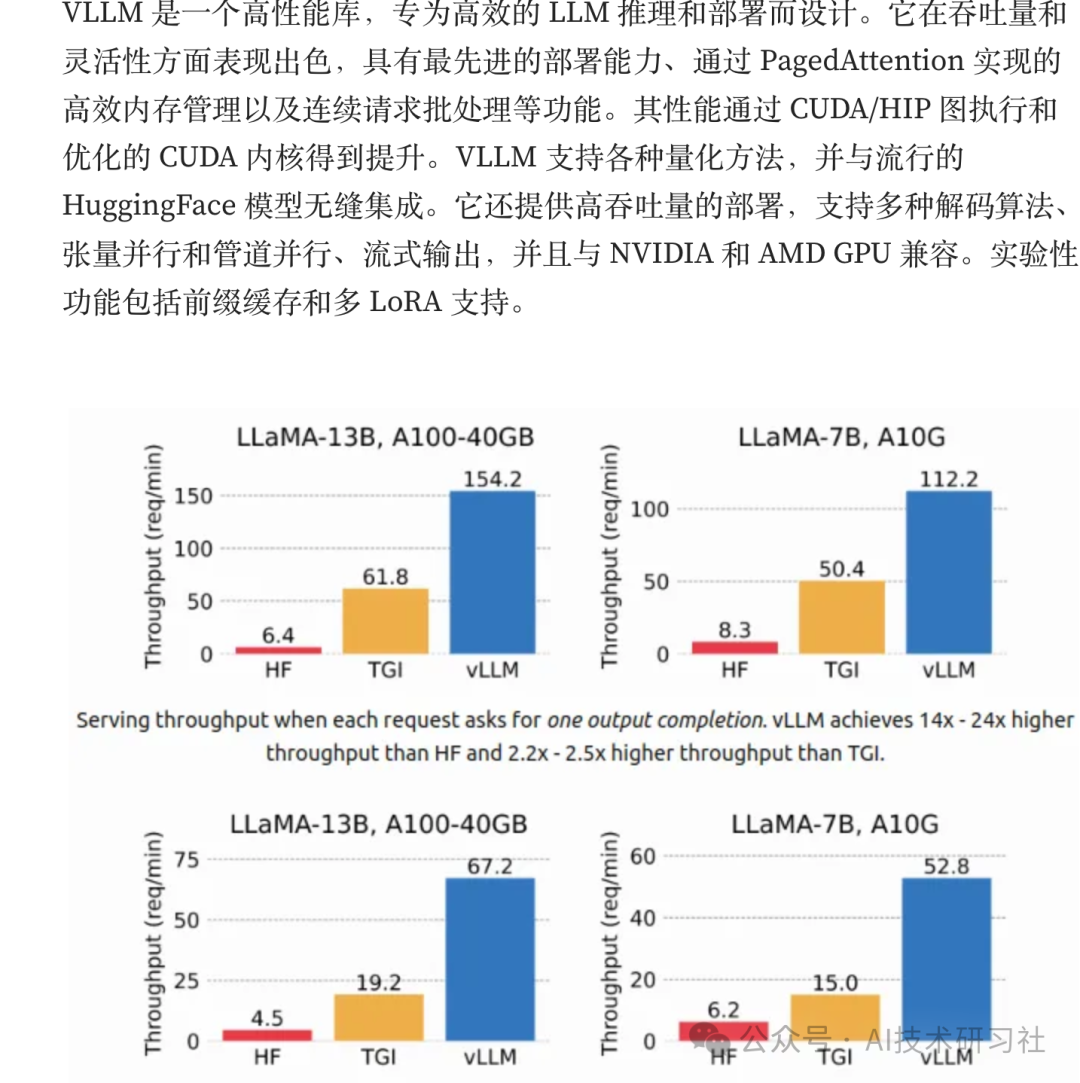
优点速览:
-
HuggingFace 一键启动,支持几乎所有主流模型
-
支持自动量化(如 awq、aqlm、bitsandbytes)
-
兼容 OpenAI 接口,轻松接入前端应用
-
支持多 LoRA 动态加载,适合多租户场景
-
支持 CUDA 和 AMD ROCm,A 卡用户狂喜!
安装体验一把非常简单:
pip install vllmvllm serve Qwen/Qwen2-1.5B-Instruct --dtype auto --api-key token-abc123Essential vllm Arguments vllm 基本参数
--hostHOSTNAME: 服务器主机名(默认:localhost)--portPORT: 服务器端口号(默认:8000)--api-key服务器访问 API 密钥(如有提供,服务器需要在头部要求此密钥)--model模型:要使用的 HuggingFace 模型的名称或路径(例如,Qwen/Qwen2-1.5B-Instruct)--tokenizer分词器:要使用的分词器名称或路径(例如,Qwen/Qwen2-1.5B-Instruct)--quantization方法:模型权重的量化方法(例如,aqlm,awq,fp8,bitsandbytes,None)--dtype模型权重和激活数据类型(例如,auto,half,float16,bfloat16,float32)--device设备:执行设备类型(例如,auto,cuda,cpu,tpu)--lora-modules模块:LoRA 模块配置(名称=路径对的列表)
Docker 用户可直接拉镜像运行:

调用方式?像用 OpenAI 一样简单!

如果你有高性能 GPU,尤其是 A100、H100 或 MI300,想要压榨最大吞吐,VLLM 是不二之选。
02|LLaMA.cpp HTTP Server:轻量本地部署神器,Intel + RTX 也能玩
如果你的设备不是满血 A100,而只是一台普通消费级电脑(比如 RTX 3060 或者 M1/M2),那就不得不提出圈已久的 LLaMA.cpp 项目了。它不仅支持 INT4/INT8 量化模型,还能在 CPU 上运行,部署成本极低。

而它的 HTTP Server 模块,更是直接打通了 RESTful API,内嵌 Web UI,让你一键搭建本地小型 AI 助手或应用服务端。
核心优势:
-
全本地化部署,无需联网
-
支持 OpenAI API 协议,秒变本地 GPT 服务端
-
兼容 GGUF 格式模型(支持 Mistral、Nous、LLaMA 变体)
-
支持并行解码、连续批处理、LoRA 热加载
-
正在开发多模态扩展(未来可期)
使用也非常简单:
git clone https://github.com/ggerganov/llama.cppcd llama.cpp && make下载模型示例:
cd modelswget https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF/resolve/main/mistral-7b-instruct-v0.2.Q2_K.gguf启动服务:
cd.../llama-server -m models/mistral-7b-instruct-v0.2.Q2_K.gguf -c 2048服务端默认监听 127.0.0.1:8080,API 与 OpenAI 完全一致,你甚至可以把它接入 LangChain、Flowise 等 AI 框架,一键部署本地 AI 流程。
对于没有高端 GPU,或者对隐私有极高要求的项目,LLaMA.cpp HTTP Server 是极具性价比的解决方案。
03|SGLang(即将登场):下一代推理编排框架,支持 Agent & 函数调用

你是否曾遇到以下问题:
-
想让模型调用多个工具,流程一团乱?
-
想实现函数调用、插件机制,却不想自己造轮子?
-
想统一部署多个微服务接口,但传统 OpenAI API 不够灵活?
别急,这就是 SGLang 登场的时机!

这是一个支持“多步骤推理、函数调用、流程控制”的全新模型服务框架,背后由 LMSYS 团队打造(就是 Chatbot Arena 的作者们)。在下一篇内容中,我们将深入拆解这个被称为“RAG + Toolformer + Multi-agent 编排终极框架”的强大项目。
安装 SGLang,请运行以下命令:

启动服务器,请运行以下命令:
! python -m sglang.launch_server --model-path Qwen/Qwen2-1.5B-Instruct --port 30000写在最后:谁适合你?
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
AI 的世界不再是单模型的孤岛,而是高度复杂的系统协作。不同的服务工具,决定了你能否真正把大模型从“玩具”升级为“生产力引擎”。
参考:https://blog.gopenai.com/serving-large-models-part-one-vllm-llama-cpp-server-and-sglang-3a079af6966e
👇欢迎在留言区告诉我你正在用哪种大模型部署方案,踩过哪些坑,又有哪些彩蛋?转发 + 在看,解锁下一期深度对比评测!
(文:AI技术研习社)