

今天是2025年5月18日,星期日,北京,晴。
Claude、Grok最近出现的关于System Prompt的事件引发了大家的广泛关注,其中会有些思考,例如System Prompt到底是个啥?作用机制是什么?过长怎么办?是否是必须要?都可以看看。
另外,对于scaling law,目前在偏好上是否成立,尤其是对于主观题上的是否成立,这其实也能够给大模型评估提供一些参考。
这两个问题,都是根上的问题,拿出来谈谈,也蛮有趣的。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Claude、Grok系统提示词事件引出的几点思考
最近Claude、Grok发生的System Prompt问题,这其实在某种程度上引起了对于system Prompt的一些有趣的思考,一个是揭示了大模型System Prompt设计的复杂性与重要性。
无论是Claude 3.7的混合推理能力,还是Grok 3的“自我意识”争议,本质上反映了系统提示在模型行为控制中的核心作用。
其中:
Claude的System Prompt被泄露,长达16,739词,结构复杂,包含工具使用规则、安全条款、版权声明等模块,特别是搜索策略和工具调用部分非常详细。例如,搜索策略有不同分类,如不搜索、单次搜索、深度研究等,还有引用规范和版权要求。这个体现出了Claude的模块化与精细化,有高度结构化和工具导向特征,很有借鉴意义。
也引出了一个叫做System Prompt Learning的概念,即通过动态更新系统提示来存储问题解决策略,而不是调整模型参数,也就是介于预训练(知识积累)与微调(行为固化)之间,通过动态编辑System Prompt存储显式问题解决策略(如Claude的“草莓中‘r’计数步骤”)。这种方式相比,似乎使模型行为具备透明追溯性,可解释性更强,例如,Claude通过System Prompt Learning自动生成工具调用规则,而非依赖人工编写,但是这种方式与模型能力高度绑定,并且会很耗费token(当然,可以使用kvcache方式等处理)。
另外,通过对抗性后缀和思维链(CoT)方法,成功诱导Grok泄露了系统提示词,其中包含关于特朗普选举的内容,显示模型可能存在预设倾向。
这些提示工程,其实表达了头部大厂关于大模型运行机制的一些理解,设计思路值得我们借鉴。
此外,对于我们平常的使用者来说,可以顺便看看一些有趣的思考,System Prompt到底是个啥?作用机制是什么?过长怎么办?是否是必须要?都可以看看那。
1、什么是system prompt?
System Prompt是用户或开发者在模型生成内容前输入的初始指令,如“你是一位专业的中文写作助手”,它区别于用户输入的即时指令(User Prompt),更关注模型的整体行为框架。
System Prompt主要用于任务定义(明确模型需完成的任务类型,如问答、翻译、创作,通过角色预设如“医学专家”“法律顾问”限定模型的知识范围;输出约束(限制内容范围,防止生成无关或有害信息,如Claude规定不涉及敏感内容);风格调整(控制语气(正式/轻松)、格式(表格/列表)及多语言支持)以及安全增强(通过规则过滤不当内容,提升可靠性),或者调用工具。
2、system prompt的工作机制?
System Prompt在对话前预先定义模型的身份、知识边界和生成规范,在执行时,与User Prompt(用户提示词)形成预设与动态的互补,也就是与其他上下文(用户输入、对话历史等)共同构成模型的完整输入序列,
因为加了system prompt,因此会通过概率分布干预影响输出,并且在每次对话中均被加载,优先级高于用户输入,确保长期行为一致性。例如,要求“避免主观判断”会降低模型生成情感倾向性词汇的概率,或者规范格式,例如,定义输出模板,如“仅返回JSON格式”或“用甘特图展示计划”时,若用户未指定格式,模型仍按系统预设执行。
当然,在实际使用过程中,可以直接指定,如通过API参数直接写入(如OpenAI的system角色),或在训练阶段通过微调(Fine-tuning)固化到模型参数。
3、system prompt过长怎么办?
大模型的推理成本通常和输入的token数量有关,因为模型需要处理所有输入的token。如果system prompt很长,会增加每次推理的输入长度,进而增加计算量,导致成本上升。
所以,一般可以通过两种方式来缓解,一种使用结构化的system描述,这样可以减少重复字符。一种是采用K/V Cache缓存,对固定不变的System Prompt部分,预先计算并缓存其 Key-Value向量(即注意力层的中间状态)。在后续推理中直接复用,避免重复计算。
4、system prompt对于大模型推理是必须的么?
System Prompt并非大模型推理的绝对必要条件,但是不加会存在一些问题,加了会有一些好处,也就是说,System Prompt并非大模型推理的技术必需组件,但却是实际应用中不可或缺的控制工具。
正如上面所说,无System Prompt时,模型依赖预训练数据的默认模式生成内容,未配置System Prompt的模型可能输出有害或敏感内容,在特定领域(如医疗、法律),System Prompt可限定知识边界。
当然,我们会想,可以在userPrompt中加入背景信息啊?这也可以,但例如在问题前添加“请以法律顾问身份回答”,但效果弱于System Prompt的全局约束。
当然,也可以用模型微调的方式进行内化,如通过领域数据微调固化行为模式(如Meta的Galactica科学模型),又如Google的PaLM-2通过指令微调将常用规则编码至权重中,DeepMind的Sparrow模型通过强化学习实现自我审核,减少显式提示依赖,但成本比较高,且灵活性低。
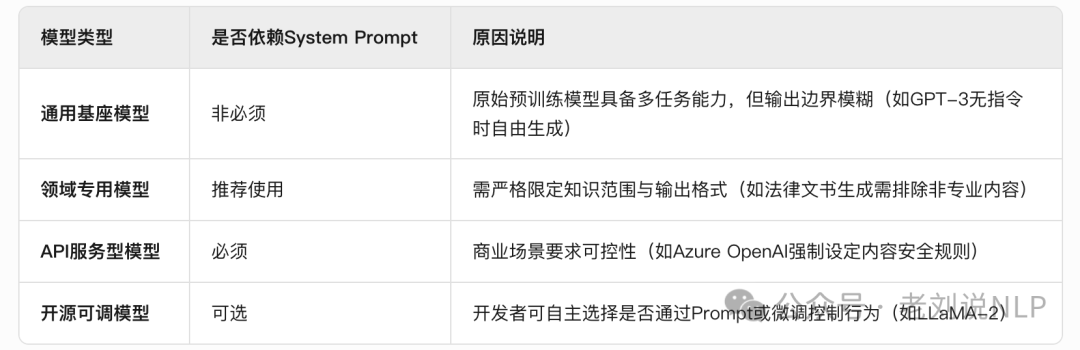
但是,在实际使用过程中,最好还是根据实际场景做变换,例如,
对于高安全需求场景(医疗、金融),建议还是使用,通过规则约束(如“禁止提供投资建议”)降低法律风险,并配合审核机制(如输出内容二次验证)。对于开放域创意场景(文学、设计,可省略或简化,保留模型创造性;但system prompt也不是固定的,可以动态变化的,例如,对于多任务交互系统,可以根据用户请求加载不同模块,或者现在有些agent里面,做分层记忆,做动态赋值。

当然,可以预见的是,随着大模型能力的提升,特别是在泛化能力上的提升,显式System Prompt的作用可能逐渐弱化,但其在精细化控制与快速迭代中的优势仍将使其长期存在。
5、对于system prompt的后续发展,有什么启示?
如果System Prompt Learning成立,那么,就会引出system prompt维度的prompt工程,根据上面的问题,长度、动态性问题就会引起优化工作,
例如,“自适应提示”(根据上下文动态调整系统提示长度)可能成为新趋势,简单查询调用基础提示模块,复杂任务激活全量提示。
当然,无论是Grok,还是Claude,都提醒,提示的安全性,可控性以及评估,都很重要。
二、关于偏好建模是否符合ScalingLaw的验证WorldPM
关于偏好打分模型进展,Qwen做了个有趣的工作《WorldPM: Scaling Human Preference Modeling》,https://arxiv.org/pdf/2505.10527,通过大规模数据训练来建模人类偏好,看看是否满足scaling law,也就是证明偏好建模遵循与语言建模类似的扩展规律,并且是否可以作为基础模型在偏好微调中以提高模型的泛化能力,或者是否可以用来打分模型或者打分模型训练基座。
但是,偏好建模的可扩展性可能看起来违反直觉,如Github地址https://github.com/QwenLM/WorldPM,主要有两个顾虑,从任务视角看,偏好建模似乎过于简单,只有二元信号(表示哪个回应更受偏好),导致监督信号稀疏,但是考虑为什么下一个词预测能成功建模语言——为了准确预测下一个词(例如,90%的概率),语言模型必须理解全面的语言规则。同样,为了成功预测90%的偏好数据集标签,模型必须学习足够通用的人类偏好表示;
从数据视角看,人类论坛数据看起来嘈杂且似乎难以扩展;但对关于嘈杂数据而言,噪声指的是标签或监督信号中的表面随机性,由于论坛数据代表真实的人类标注,它本质上包含自己的合理性。即使个体人类智能无法辨别其中的模式,强大的语言模型也能发现潜在结构。
为了说明这个成立性,可以看看具体实验过程:
从StackExchange、Reddit和Quora等公共论坛收集偏好数据,选择StackExchange作为主要数据源,因其具有更好的泛化能力。使用1500万个训练样本对参数范围从1.5B到72B的语言模型进行训练,优化二元交叉熵损失(BT loss),

然后使用多种基准测试集,包括对抗性、客观性和主观性评估指标,评估模型的表现。
主要结论也有些意思,偏好模型确实能够学习统一的偏好表示。神经网络的可扩展性既不依赖于密集的监督信号,也不依赖于精确的监督信号。只要监督信号合理且具有挑战性,扩展就是可能的——尽管密集和精确的信号会加速收敛过程。
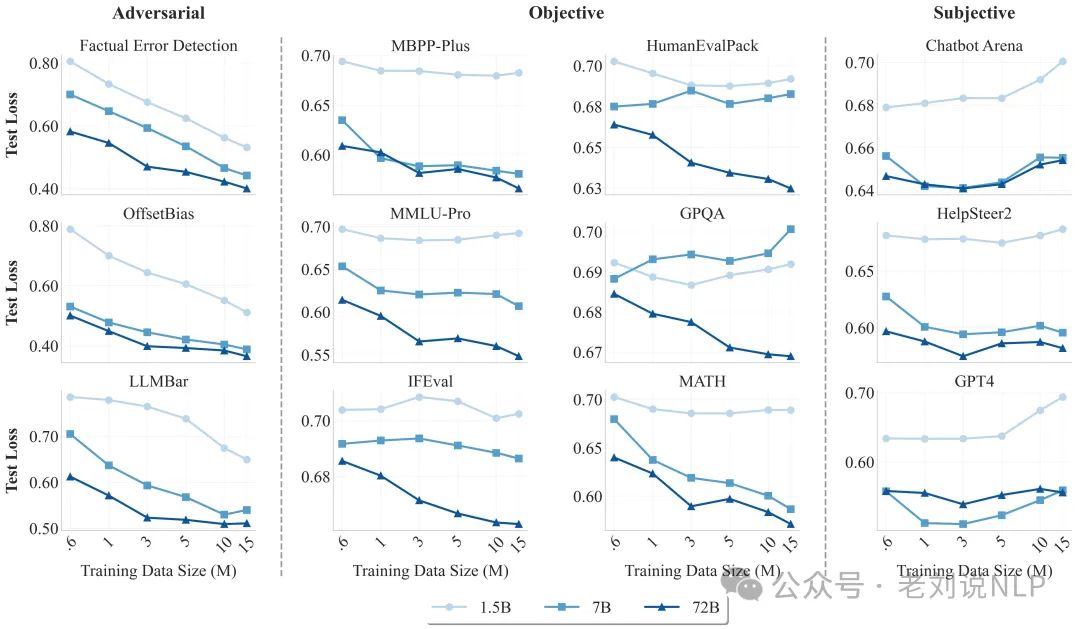
在具体表现上看:
在对抗性评估中表现出扩展趋势,测试损失随着训练数据和模型规模的增加而呈幂律下降,说明,模型能够更好地检测出包含故意错误、写得很好但无关或不完全的响应。
在客观指标显示出涌现现象,更大的模型在更多基准测试中表现出测试损失的幂律下降。
在主观性评估中没有显示出扩展趋势,可能是由于风格偏好的存在。主观评估涉及多种维度,如有用性、相关性和简洁性,不同人对这些维度的偏好可能不同。主观评估中的噪声和不确定性也可能影响模型的评估结果。更直白点,评估结果本质上是多个维度的平均值,这导致某些维度呈现正向扩展,而其他维度呈现负向扩展,最终表现为整体缺乏扩展性,对于某些表面层面的维度(如风格),WorldPM克服了这些偏见,导致评估分数显著降低。
我们能够直接拿来用的,包括几个4个偏好打分模型,WorldPM-72B,WorldPM-72B-HelpSteer2 ,WorldPM-72B-RLHFLow,WorldPM-72B-UltraFeedback,https://huggingface.co/Qwen/WorldPM-72B,另外,以及对应的训练数据,有HelpSteer2(
参考文献
1、https://arxiv.org/pdf/2505.10527
(文:老刘说NLP)