

一、项目概述
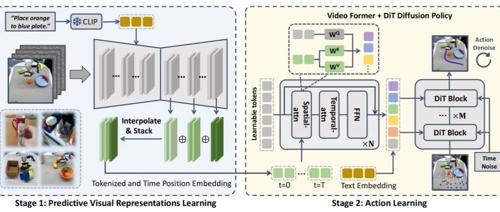
VPP(Video Prediction Policy)是清华大学和星动纪元联合推出的首个AIGC机器人大模型,旨在通过预训练的视频扩散模型学习互联网上的大量视频数据,直接预测未来场景并生成机器人动作。VPP的核心优势在于其能够提前预知未来场景,支持高频预测与动作执行,并且可以跨人形机器人本体切换,显著降低了对高质量机器人真机数据的依赖。这一创新模型在Calvin ABC-D基准测试中取得了接近满分的成绩,并在真实世界的复杂灵巧操作任务中表现出色,为具身智能机器人的发展提供了强大的技术支持。

二、核心技术
(一)视频扩散模型(VDM)的预测性视觉表示
VPP利用预训练的视频扩散模型(如Stable Video Diffusion)学习预测未来场景。视频扩散模型通过单步去噪生成预测性视觉表示,这些表示不仅包含当前帧,还能明确表示未来帧。这种预测性视觉表示为机器人提供了对未来场景的直观理解,增强了其泛化能力。
(二)动作学习
VPP使用Video Former聚合预测性视觉表示,提取时空信息,并基于扩散策略(Diffusion Policy)生成机器人动作。这一过程实现了从预测到执行的无缝过渡,确保机器人能够高效地完成任务。
(三)优化与泛化
VPP通过结合互联网视频数据和机器人操作数据进行训练,减少了对高质量真机数据的依赖。此外,VPP还支持跨本体学习,能够直接学习不同形态机器人的视频数据,进一步提升了模型的泛化能力。
三、主要功能
(一)提前预测未来场景
VPP能够让机器人在行动前“看到”未来,增强其在复杂环境中的泛化能力。这一功能使得机器人能够提前规划动作,避免潜在的错误和风险。例如,在家庭环境中,VPP可以预测家庭成员的行动轨迹,提前为老人递送物品或为儿童提供帮助。在工业环境中,VPP可以预测生产线上的零件运动,提前调整机械臂的位置,提高生产效率。这种对未来场景的预测能力,使得机器人能够更加智能地应对各种动态环境。
(二)高频预测与动作执行
VPP实现了6-10Hz的预测频率和超过50Hz的控制频率,显著提升了动作的流畅性和响应速度。这种高频预测和执行能力使得机器人能够在动态环境中快速调整动作。例如,在物流仓库中,VPP可以快速响应货物的移动,及时调整抓取位置,确保货物搬运的高效性。在医疗场景中,VPP可以快速响应手术器械的需求,及时传递器械,提高手术效率。
(三)跨机器人本体学习
VPP可以直接学习不同形态机器人的视频数据,包括人类操作数据,降低了数据获取成本。这一功能使得VPP能够广泛应用于多种机器人平台,而无需为每种机器人单独收集大量数据。例如,VPP可以在人形机器人和机械臂之间无缝切换,根据任务需求灵活调整操作方式。这种跨本体学习能力,使得VPP能够适应各种不同的机器人形态和任务需求。
(四)多任务学习与泛化
VPP在复杂的真实世界任务中表现出色,能够完成抓取、放置、堆叠、倒水和工具使用等多种任务。这种多任务学习能力使得VPP能够适应各种不同的应用场景。例如,在家庭环境中,VPP可以完成家务任务,如倒水、拿东西等;在工业环境中,VPP可以完成零件抓取、货物搬运和堆叠等任务;在医疗场景中,VPP可以协助手术器械传递、康复训练和病房物品递送。这种多任务学习能力,使得VPP能够在一个通用策略下完成多种任务,显著提高了机器人的适应性和实用性。
(五)可解释性与调试优化
基于预测视频,VPP能够提前发现失败场景,便于开发者进行针对性优化。这一功能大大提高了开发效率,降低了调试成本。例如,在开发过程中,开发者可以通过预测视频快速定位机器人可能失败的场景,提前进行优化和调整。这种可解释性,使得开发者能够更好地理解和改进机器人的行为,提高机器人的性能和可靠性。

四、应用场景
(一)家庭服务
VPP能够完成家务(如倒水、拿东西)和照顾老人或儿童(如递送物品)等任务,为家庭生活提供便利。
例如,VPP可以预测家庭成员的需求,提前为老人递送药品或为儿童提供玩具。在家庭环境中,VPP还可以协助烹饪,如倒水、抓取食材等,显著减轻家庭成员的负担。
(二)工业制造
VPP可以用于零件抓取、货物搬运和堆叠等任务,显著提高生产效率。
例如,在汽车制造工厂中,VPP可以预测生产线上的零件运动,提前调整机械臂的位置,快速抓取和搬运零件。在物流仓库中,VPP可以预测货物的移动,及时调整搬运路径,提高货物搬运的效率和准确性。
(三)医疗辅助
VPP能够协助手术器械传递、康复训练和病房物品递送,为医疗领域提供支持。
例如,在手术室中,VPP可以预测手术器械的需求,及时传递器械,提高手术效率。在康复训练中,VPP可以协助患者进行康复动作,提供实时反馈和指导,提高康复效果。在病房中,VPP可以递送药品、食物等物品,减轻医护人员的负担。
(四)教育与研究
VPP可以帮助学生理解复杂操作流程,用于实验室实验操作,提升教育效果。
例如,在实验室中,VPP可以演示复杂的实验操作步骤,帮助学生更好地理解和掌握实验技巧。在教育场景中,VPP可以协助教师进行实验演示,提供实时操作指导,提高教学效果。
(五)服务行业
VPP可以应用于餐厅送餐、酒店行李搬运和公共场合导览等场景,提升服务质量。
例如,在餐厅中,VPP可以预测顾客的需求,及时递送食物和饮料。在酒店中,VPP可以协助搬运行李,提供导览服务,提升客人的体验。在公共场合,VPP可以提供导览和信息查询服务,帮助游客更好地了解景点信息。
五、测评表现
VPP在多个基准测试和真实世界任务中表现出色,以下是其主要测评结果:
(一)Calvin ABC-D基准测试
VPP在Calvin ABC-D基准测试中取得了接近满分的成绩,平均任务完成长度达到4.29,相比之前的最佳方法(3.35)有显著提升。
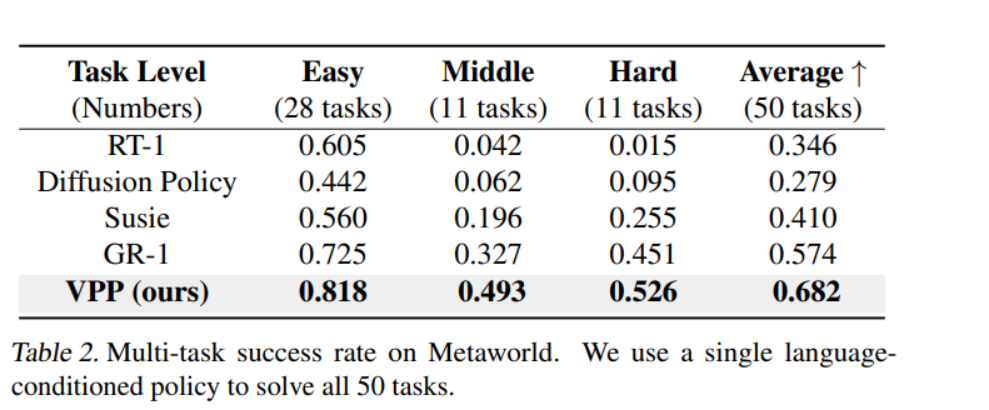
(二)MetaWorld基准测试
VPP在MetaWorld基准测试中平均成功率达到68.2%,相比最强基线方法(57.4%)提升了10.8%。
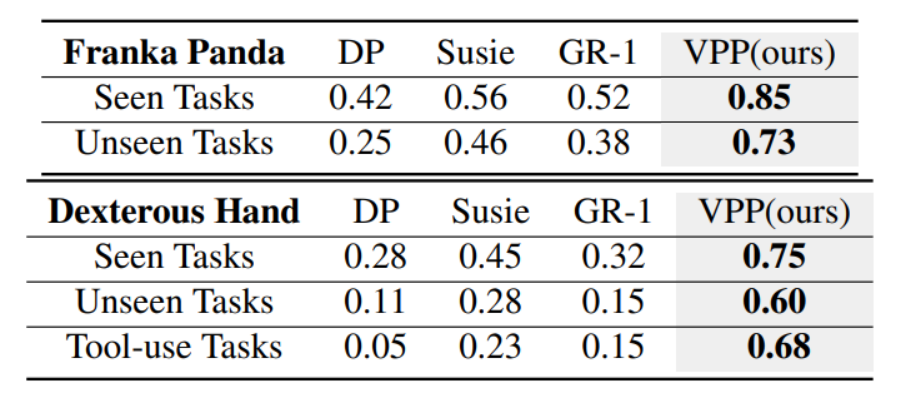
(三)真实世界任务
VPP在真实世界的Panda机械臂和XHand灵巧手任务中表现出色,成功完成了超过100项任务,包括复杂的工具使用任务。在Panda机械臂任务中,VPP的平均成功率达到85.6%(已见任务)和73.7%(未见任务);在XHand灵巧手任务中,VPP的平均成功率达到74.9%(已见任务)和60.5%(未见任务)。
六、快速使用
(一)环境准备
1. 创建并激活Python环境:
conda create -n vpp python==3.10conda activate vpp
2. 安装Calvin环境(可选):
git clone --recurse-submodules https://github.com/mees/calvin.gitexport CALVIN_ROOT=$(pwd)/calvincd $CALVIN_ROOTsh install.sh
3. 安装VPP依赖:
pip install -r requirements.txt(二)模型下载
1. 下载预训练模型:
-
`clip-vit-base-patch32`:用于文本编码。
模型地址:https://huggingface.co/openai/clip-vit-base-patch32
-
`svd-robot-calvin`:用于Calvin任务的视频模型。
模型地址:https://huggingface.co/yjguo/svd-robot-calvin-ft/tree/main
-
`dp-calvin`:用于Calvin任务的动作模型。
模型地址:https://huggingface.co/yjguo/dp-calvin/tree/main
(三)视频预测
1. 使用预训练的视频模型进行视频预测:
python make_prediction.py --eval --config video_conf/val_svd.yaml --video_model_path ${path to svd-robot} --clip_model_path ${path to clip} --val_dataset_dir video_dataset_instance/xhand --val_idx 0+50+100+150(四)策略评估
1. 在Calvin基准测试中评估VPP策略:
python policy_evaluation/calvin_evaluate.py --video_model_path ${path to svd-robot-calvin} --action_model_folder ${path to dp-calvin} --clip_model_path ${path to clip} --calvin_abc_dir ${path to calvin dataset}七、结语
VPP作为清华大学和星动纪元联合推出的首个AIGC机器人大模型,凭借其强大的预测能力和广泛的应用场景,为具身智能领域带来了新的突破。VPP不仅在多个基准测试中取得了优异的成绩,还在真实世界任务中表现出色,展现了其强大的泛化能力和适应性。随着VPP的开源,开发者可以更轻松地将其应用于各种机器人平台,推动具身智能技术的发展。
八、项目地址
项目官网:https://video-prediction-policy.github.io/
GitHub仓库:https://github.com/roboterax/video-prediction-policy
arXiv技术论文:https://arxiv.org/pdf/2412.14803
AI大模型+具身智能2025·系列
1.LightPlanner:中科视语开源的轻量化具身推理大模型,赋能机器人高效决策
2.家庭服务机器人要逆天!Embodied-Reasoner:自动规划路径、搬运物品,复杂任务一网打尽
3.RoboMamba:推理速度提升7倍,北大如何打造高效机器人多模态大模型?
4.斯坦福团队开源!OpenVLA:小白也能搞机器人,100条数据就能微调!
5.CMU×上交大搞出「全能机器人」!开放场景任务成功率超90%
(文:小兵的AI视界)