
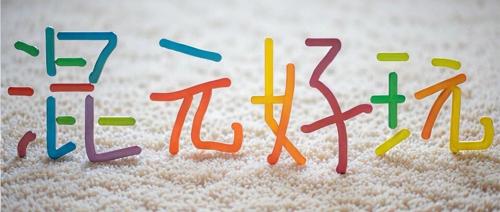

AI生图又来新惊喜了!
一口气解决了我写提示语慢、对图片刁钻角度描述不清、小学生级画画水平等问题。
混元新模型新出了实时生图和实时画板,生成速度是:
毫秒级
Amazing 啊!现在我都已经习惯了发消息前先琢磨琢磨要发什么,然后等模型先思考或生成个10~60秒,
换句话说,我们跟AI是有时差的。但当时差来到毫秒级的时候,AI生图的交互方式就彻底改变了。
且质量一点都不差,真实感很强:

我以为AI生图目前只有在生成风格像4o画吉卜力一样能给我惊喜,没想要混元直接在交互上玩了个新的!
目前这个模型已经对外开放了:
🔗hunyuan.tencent.Com
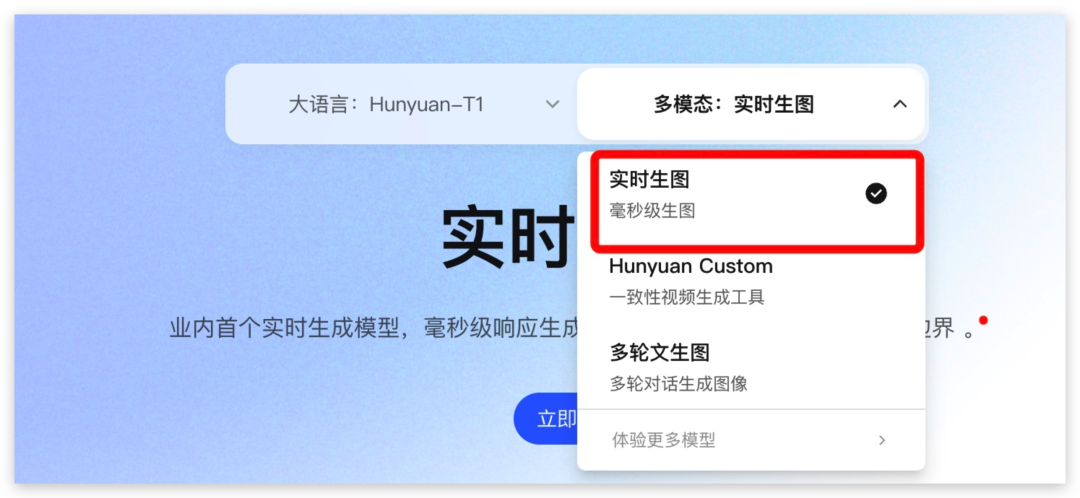
昨天玩了一晚上,先给大家盘一下我的玩法和感受!
Here we go!
一、实时生图
刚开始用的时候真的有种不真实感,
之前哪怕是看科幻片、超英片,
钢铁侠吩咐贾维斯做事情的时候都要几秒,
现在生图直接就按毫秒级来了,这图简直就是随着我的打字开始千变万化了。
太快了,快到不习惯,快到可以一边说话一边变化,自由变换图片里的主体、背景、画面风格等等等等。
在柔和自然光线下拍摄的高真实感人像照片:主体是一位二十多岁的年轻人,穿着简洁休闲装,面带自信而温暖的微笑。周围环境略带虚化,背景色彩柔和,凸显人物的面部表情和衣着细节。照片整体层次分明、质感突出,具有专业摄影师作品的真实感和自然氛围,仿佛刚刚在城市街头或公园中随手捕捉到的精彩瞬间。
这是我用其他生图工具时的常用提示语,通常是给 deepseek 说出我的关键词,然后让他帮我扩充。
哪怕是现在能 GPT-4o 支持多轮对话修图,但可能连续对话了四五轮之后,画面质量就会开始下滑了。
这就意味着这个图片里面的大部分要素需要在一开始就确定好,所以有段时间我觉得AI生图用多了之后,真的想是在逛超市,我看到好用的提示语就行收藏起来,

但如果不是连续迭代,而是直接跟随提示语的变化实时生成图片,感觉又如何?
和上面看到的一样,这是一种全新的AI生图的交互方式,体验真的蛮神奇的。
可以根据画面的变化,及时的修改提示语,不用再等待图片生成出来后,再进行修改,不仅效率提高了,生图的思考方式也发生了变化。
混元还支持语音输出,我直接解放双手了。
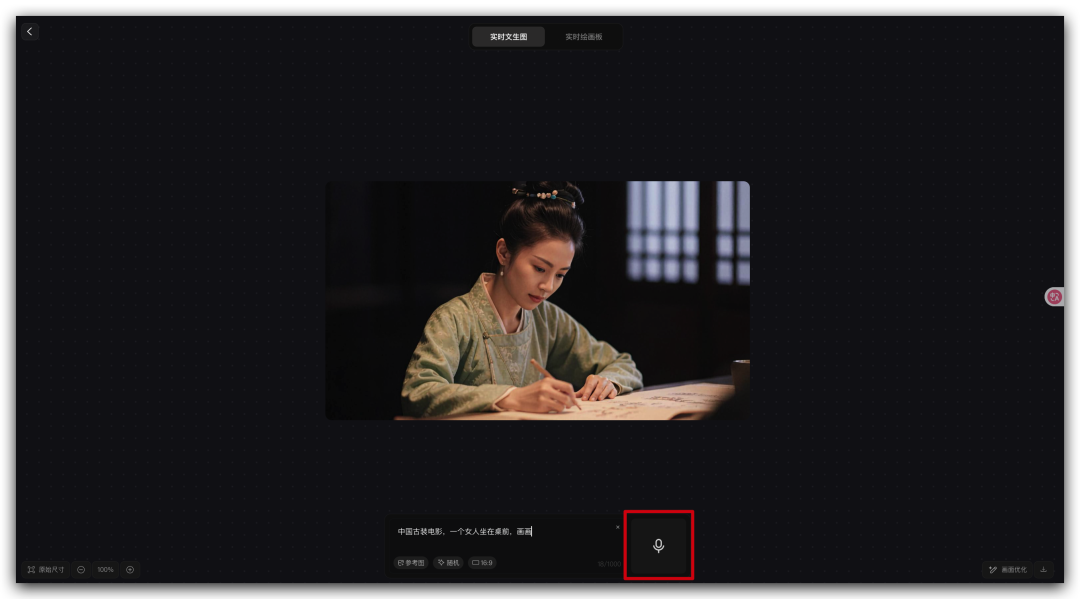
也许,我以后生图之前不用再思考那么多,而是可以直接张嘴就来,一边说一边想,这也蛮有意思的。
而且还要提一句,混元目前做这种真实感图片还蛮有味儿的,氛围感很强。

二、实时画板
坦白说这我有点梦回 Stable Diffusion 爆火的时间点,
当时对一个图片不满意,特别是人物的手画崩了时候,
别的模型都不行,只有它,
可以框个框开始重绘,这个过程画面会一闪一闪的,有点看到AI在画东西的样子。
(素材来自Nenly同学)
那时候像是AI第一次拿起了画笔,但是画的东西和我们想的,总还是差点距离,
我只能控制它修改哪里,但改成什么样子,只能通过“文字”。
可是“文字”能够表达的东西,或者受限于我的表达能力,有的时候,就很难说明白,然后,AI有时就很难画明白。
但混元这次给了一个新方式,我不仅可以写字,还可以画画,搭配着来告诉AI我要什么。
这,总能看得懂了吧!
现在,我们的画笔第一次有了颜色,它能画出相应颜色的物体,


也能把我的画生成出神韵相似的3D图,


还能根据我的画生成出精准的角度,


甚至可以通过文字选择合适的材质,让我写的字直接搭成实物。
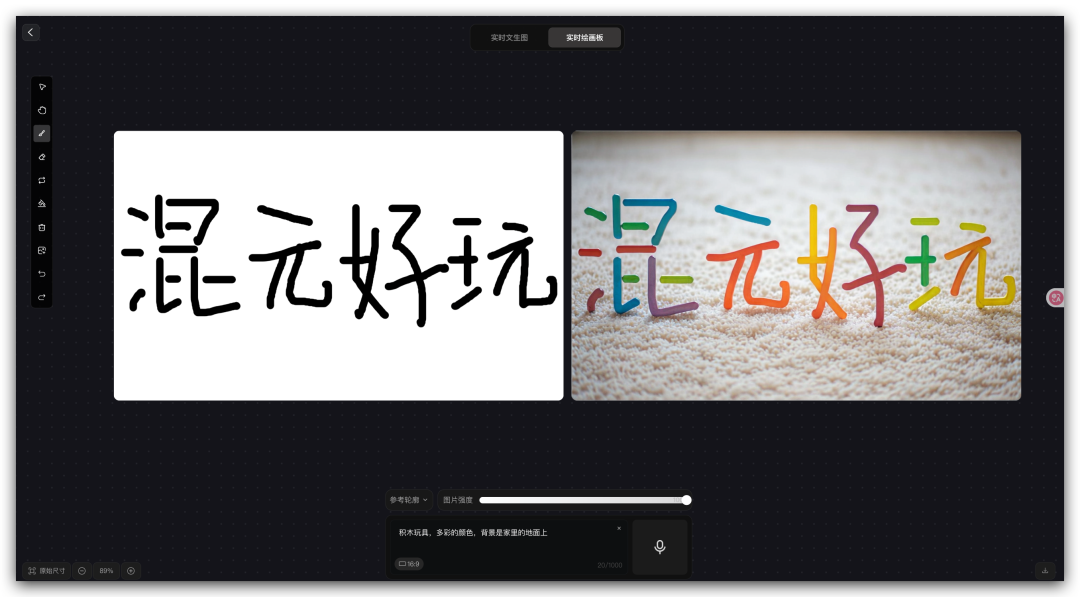

好好玩啊!
有种我和AI一起画画的感觉,而且他还特懂我,是百年遇知音的即视感。
而且这种绘图的交互方式,很适合有一点绘画基础的人,通过画笔精准的表达自己的意图,从而获得更符合自己期待的图片。
AI短片人,用它来画分镜图似乎也不错。
写在最后
所以别再说你不会画画了,
只是还没用过会听你说话的画笔。
别说你描述不清了,
是你还没见过边说边变的AI。
它反应比你朋友快,
画得比你脑补还准。
以前我们等AI,现在AI等我们。
不是生成图,是在生成想法。
你说得越多,图变得越快。
你改得越狠,它跟得越紧。
那种“我就想要这种感觉”,
它真的能懂。
实时的,不是图片,
是灵感。
下一张图, 你说了算。
@ 作者 / 卡尔 & 阿汤 @ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)