



https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf0 Abstruct
Qwen3 包括一系列旨在提升性能、效率和多语言能力的 LLMs。
涵盖 Dense 和 MoE 架构的不行,参数规模从 0.6B 到 235B 不等。
Qwen3 的一个关键创新是将 thinking mode(用于复杂的多步推理)和 non-thinking mode(用于快速、上下文驱动的响应)整合到一个统一的框架中,并能够基于用户 query 或 chat templates 动态切换模式。消除了在聊天优化模型(如 GPT-4o)和推理专用模型(如 QwQ-32B)之间切换的需求。
同时,Qwen3 引入了一种思维预算机制,允许在推理过程中自适应地分配计算资源,平衡延迟和性能。
此外,通过利用旗舰模型的知识,在保证性能的条件下显著降低了构建小模型所需的计算资源。
测试结果显示 Qwen3 在代码生成、数学推理、Agent 等多个 benchmarks 上取得了 SOTA 的结果,相比于更大的 MoE 模型和闭源模型具有竞争力。
与之前的 Qwen2.5 相比,Qwen3 将多语言支持从 29 种扩展到 119 种语言和方言。
1 Introduction
Qwen3 的预训练过程利用了一个含有约 36T tokens 的大规模数据集。
为了有效扩展训练数据,采用了一个多模态方法:微调 Qwen2.5-VL 来从大量 PDF 文档中提取文本。
还使用特定领域的模型生产合成数据:Qwen2.5-Math 用于数学内容,Qwen2.5-Coder 用于代码相关数据。
预训练过程采用三个阶段策略:
-
• 第一阶段,在约 30T tokens 上进行训练,构建扎实的基础通用知识。 -
• 第二阶段,在知识密集型数据上进一步训练,以增强科学、技术、工程、数学、代码等领域的推理能力。 -
• 第三阶段,在长上下文数据上进行训练,将最大上下文长度从 4096 增加到 32768。
后训练也采用多阶段策略,同时增强 thinking 和 non-thinking 两种模式:
-
• 前两个阶段,通过在数学和代码任务上的 long CoT 冷启动微调和 RL 来培养推理能力。 -
• 最后两个阶段,将带有推理路径和不带有推理路径的数据集合,形成一个统一的数据集进一步微调,使模型能够有效处理这两种类型的输入。然后应用通用领域的 RL,提升大量下游任务上的表现。
对于小模型,采用 strong-to-weak 的蒸馏方法,利用更大模型的 off-policy 和 on-policy 知识转移来增强小模型的能力。从更好的教师模型上蒸馏在性能和效率上显著优于 RL。
在涵盖多种任务和领域的综合 benchmarks 上对预训练和后训练模型进行了评估。结果显示,Qwen3 Base 预训练模型取得了 SOTA 的表现。后训练模型(不管是 thinking 还是 non-thinking 模式)在与目前领先的闭源模型(如 o1、o3-mini)和大型 MoE 模型(如 DeepSeek-V3)的竞争中表现出色。
Qwen3 在编程、数学、Agent 任务上表现尤为突出。例如,Qwen3-235B-A22B 在 AIME’24 上取得了 85.7分,在 AIME’25 上取得了 81.5 分,在 LiveCodeBench v5 上取得了 70.7 分,在 CodeForces 上获得了 2056 分,在 BFCL v3 上获得了 70.8 分。Qwen3 系列中的其他模型也表现出在类似规模下的强劲表现。
此外,观察到增加 thinking tokens 的预算会使模型在各种任务上的表现持续提升。
2 Architecture
Qwen3 系列包括 6 个 Dense 模型(0.6B、1.7B、4B、8B、14B、32B)和 2 个 MoE 模型(Qwen3-30B-A3B 和 Qwen3-235B-A22B)。

Dense 模型架构与 Qwen2.5 相似,包括使用 GQA、SwiGLU、RoPE、RMSNorm with pre-normalization。移除了 Qwen2 中的 QKV-bias,在注意力机制中引入 QK-Norm 来确保稳定训练。
MoE 模型与 Dense 模型共享相同的基础架构。与 Qwen2.5-MoE 一致,实现了细粒度专家分割。Qwen3 MoE 模型一共有 128 个专家,每个 token 激活 8 个专家。与 Qwen2.5-MoE 不同的是,移除了共享专家。采用 global-batch 负载均衡 loss。这些架构和训练创新显著提升了在下游任务上的性能。
Qwen3 模型使用 Qwen 的 tokenizer,byte-level BPE,词表大小 151669。
3 Pre-triaining
3.1 Pre-training Data
与 Qwen2.5 相比,显著扩大了训练数据的规模和多样性。收集了两倍大、涵盖三倍多以上语言的预训练 token。
所有的 Qwen3 模型在一个含有 119 中语言和方言,总共 36T tokens 的数据上进行训练。
数据包括高质量的内容,涵盖多个领域,如代码、STEM(科学、技术、工程、数学)、推理任务、书籍、多语言文本、合成数据。
为了进一步扩展预训练预料库,首先用 Qwen2.5-VL 对大量 PDF 类型的文档进行文本识别。之后利用 Qwen2.5 对识别出的文本进行精炼,提升质量。获得了 T 级别的高质量 token。
此外,采用 Qwen2.5、Qwen2.5-Math、Qwen2.5-Coder 合成了 T 级别的不同格式的 tokens,包括教科书、问答、指令、代码片段等数十个领域。
最后,加入额外的多语言数据来进一步扩展语料。
开发了一个多语言数据标注系统,该系统已应用于大规模与训练数据集,对超过 30T token 进行了标注,涵盖 educational value、fields、domains、safety 等多个维度。这些详细的标注支持了更有效的数据过滤和组合。
不同于之前在数据源或 domain 层面的优化数据组合的工作,通过带有细粒度标签的小模型上广泛的消融实验,在 instance-level 上对数据组合进行优化。
3.2 Pre-training Stage
Qwen3 经过了 3 个阶段的预训练:
-
• General Stage(S1):4096 长度,在超过 30T token 上训练。在这个阶段,模型在涵盖 119 种语言和方言的数据上全面预训练了语言熟练度和一般世界知识。 -
• Reasoning Stage(S2):增加 STEM、代码、推理、合成数据的比例来优化预训练语料。在约 5T 高质量 token 上预训练,4096 长度。在这一阶段加速了学习率衰减。 -
• Long Context Stage(S3):收集了高质量长上下文预料,所有模型都在 32768 长度上训练了数百 B 的 token。75% 为 16384-32768 长度,25% 为 4096-16384 长度。使用 ABF 技术将 RoPE 的基频从 10000 提升至 1000000。引入 YARN 和 DCK 来实现推理过程中序列长度容量的 4 倍增长。
基于上述三个预训练阶段探索用于预测最佳超参数(如 lr scheduler 和 batchsize)的 scaling law。通过大量实验系统地研究了模型架构、训练数据、训练阶段与最佳超参数之间的关系。最后为每个 Dense 和 MoE 模型设定预测的最佳的学习率策略和 batchsize策略。
3.3 Pre-training Evaluation
15 个 benchmarks:
-
• General Tasks:MMLU (5-shot)、MMLU-Pro (5-shot, CoT)、MMLU-redux (5-shot)、BBH (3-shot, CoT)、SuperGPQA (5-shot, CoT) -
• Math & STEM Tasks:GPQA (5-shot, CoT)、GSM8K (4-shot, CoT)、MATH (4-shot, CoT) -
• Coding Tasks:EvalPlus (0-shot) (HumanEval、MBPP、Humaneval+、MVPP+ 的平均)、MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)、MBPP-3shot、CRUX-O of CRUXEval (1-shot) -
• Multilingual Tasks:MGSM (8-shot, CoT)、MMMLU (5-shot)、INCLUDE (5-shot)
将 Qwen3 系列 Base 模型与 Qwen2.5、DeepSeek-V3、Gemma-3、Llama-3、Llama-4 进行比较。所有模型都使用相同的评估流程和广泛使用的评估设置来确保公平比较。
评估结果摘要
(1) 与之前的开源 MoE 模型(如 DeepSeek-V3 Base、Llama-4-Maverick Base、Qwen2.5-72B-Base)相比,Qwen3-235B-A22B-Base 在大多数任务中表现更好,总参数或激活参数显著减少。
(2) 对于 Qwen3 MoE Base 模型,实验结果表明
-
• 相同的预训练数据,MoE 模型仅用 1/5 的激活参数就能达到与 Qwen3 Dense 模型相似的性能。 -
• Qwen3 MoE Base 模型可以用不到 1/2 的激活参数和更少的总参数优于 Qwen2.5 MoE Base 模型。 -
• 即使只有 Qwen2.5 Dense 模型 1/10 的激活参数,Qwen3 MoE Base 模型也能达到可比的性能。
(3) Qwen3 Dense Base 模型整体性能与更多参数规模的 Qwen2.5 Base 模型相当。

4 Post-training

后训练 pipeline 旨在实现两个核心目标:
-
• Thinking Control:整合 thinking 和 non-thinking 两种不同的模式,使用户能够灵活选择模型是否进行推理,并通过指定思考的 token 预算来控制思考深度。 -
• Strong-to-Weak Distillation:旨在简化和优化小模型的后训练流程。
直接将教师模型的输出 logits 蒸馏到小模型中,可以保持对其推理过程细粒度控制的同时有效提升性能,消除了对每个小模型单独进行 4 阶段训练的必要性。带来了更好的 Pass@1 分数,同时也提高了模型的探索能力(体现在更好的 Pass@64 表现上)。与 4 阶段训练方法相比,只需要 1/10 的 GPU hours。
4.1 Long-CoT Cold Start
首先构建一个全面数据集,涵盖包括数据、代码、逻辑推理、一般 STEM 问题等的广泛类别。数据集中的每个问题都与经过验证的参考答案或 code-based test cases 配对。这个数据集用于 long-CoT 的冷启动。
数据集构建涉及两个过滤过程:query 过滤 和 response 过滤。
-
• query 过滤:使用 Qwen2.5-72B-Instruct 来识别并移除不易验证的 query,包括含有多个子问题的 query 或者普通文本生成的 query。此外,排除 Qwen2.5-72B-Instruct 可以在不使用 CoT 推理的情况下正确回答的 query。此外,使用 Qwen2.5-72B-Instruct 标注每个 query 的领域,对数据集进行平衡。 -
• response 过滤:保留一个验证 query 集,之后使用 QwQ-32B 为每个剩余的 query 生成 N 个候选 response。当 QwQ-32B 一致无法生成正确答案时,人工评估 response 的准确性。对于 positive Pass@N 的 query,采用更严格的过滤标准。(1) 产生错误最终答案的。(2) 包含大量重复的。 (3) 没有充分推理的猜测。 (4) 思考内容与总结内容表现不一致的。 (5) 涉及不适当语言混合或风格变化。 (6) 疑似与潜在的验证集过于相似的。
之后,从精炼数据集中精心挑选出一个子集用于推理模式的初始冷启动训练,植入基础推理模式,确保不限制模型的潜力,允许后续的 RL 阶段有更大的灵活和改进空间。这一阶段数据数量和训练步数尽量减少。
4.2 Reasoning RL
在 Reasoning RL 阶段使用的 query-verifier 对必须满足以下四个标准:
-
• 未在冷启动阶段使用过 -
• 对冷启动模型是可学习的 -
• 尽可能具有挑战性 -
• 涵盖广泛的子领域
最终收集了 3995 个 query-verifier 对,采用 GRPO 更新模型参数。
观察到,使用大 batchsize、大 rollout 以及 off-policy 训练来改善样本效率对训练过程是有益的。
还解决了如何通过控制模型的熵稳定增加或保持稳定来平衡 exploration 和 exploitation,这对于保持稳定训练至关重要。
因此,在单次的 RL 中,无需对超参数进行任何手动干预,就实现了训练 reward 和验证集表现的一致提升。例如,Qwen3-235B-A22B 在 AIME’24 得分从 70.1 提升至 85.1,总共经过了 170 步的 RL 训练。
4.3 Thinking Mode Fusion
Thinking 模式融合的目标是将 non-thinking 能力整合到先前开发的 thinking 模型中,使开发者能够管理和控制推理行为。
对 Reasoning RL 模型进行继续 SFT,并设计了一个 chat template 来融合这两种模式。并且发现能够熟练处理这两种模式的模型在不同的 thinking 预算下都表现良好。
Construction of SFT Data
SFT 数据集结合了 thinking 和 non-thinking 数据。
为了确保第二阶段的模型不受额外 SFT 的影响,thinking 数据是由第一阶段的 query 用第二阶段的模型本身拒绝采样得到的。
non-thinking 数据则经过精心设计,涵盖多样化任务,包括代码、数学、指令遵循、多语言任务、创意写作、问答、角色扮演等。采用自动化生成的 checklists 来评估 non-thinking 的数据质量。特别增加了翻译任务的比例来提升低资源语言任务的性能。
Chat Template Design
为了更好地整合两种模型和能够动态切换,为 Qwen3 设计了 chat template。

在用户 query 或 system message 中引入 /think 和 /no_think 标志使模型能根据用户输入选择合适的思维模式。
对于 non-thinking 样本,在 response 中保留一个空的思考块,确保内部格式一致性。
默认是思考模型,因此增加了一下用户 query 不包含 /think 标志的 thinking 训练样本。
对于更复杂的多轮对话,在用户 query 中随机插入多个 /think 和 /no_think 标志,模型 response 遵循最后遇到的标志。
Thinking Budget
Thinking Mode Fusion 的一个额外优势是,一旦模型学会了以 non-thinking 和 thinking 两种模式进行回应,就自然发展出处理中间情况的能力——基于不完整的思考生成 response。为实现对模型思考过程的预算控制提供基础。
当模型思考长度达到用户定义的阈值时,手动停止思考过程,并插入停止思考指令:“Considering the limited time by the user, I have to give the solution based on the thinking directly now.\n</think>.\n\n“。模型会基于此时积累的推理生成最终 response。这一能力没有经过明确训练,而是应用 thinking mode fusion 后自然出现的。
4.4 General RL
General RL 阶段旨在广泛提升模型在不同场景下的能力和稳定性。
构建了一个复杂的 reward system,涵盖超过 20 个不同的任务,每个任务都有定制化的评分标准。这些任务针对以下核心能力的提升:
-
• 指令遵循:确保模型准确解读并遵循用户指令,包括与内容、格式、长度以及结构化输出使用相关的需求,以提供符合用户预期的回应。 -
• 格式遵循:期望模型遵守特定的格式规范。例如,根据 /think 和 /no-think 标志在思考与非思考模式之间切换,并一致使用指定的标记来分离最终输出中的思考和响应部分。 -
• 偏好对齐:关注于提高模型的有用性、参与度和风格,最终提供更加自然和令人满意的用户体验。 -
• Agent 能力:涉及训练模型通过指定的接口正确调用工具。在 RL rollout 期间,模型被允许执行完整的多轮互动周期,并获得真实环境执行的反馈,从而提高其在长期决策任务中的表现和稳定性。 -
• 特定场景能力:在更专业的场景中设计针对具体情境的任务。例如,RAG 任务中,结合奖励信号来指导模型生成准确且符合上下文的 response,从而最小化产生幻觉的风险。
为了给上述任务提供反馈,使用三种不同类型的奖励:
-
• Rule-based Reward:Well-designed rule-based reward 可以高准确性地评估模型输出的正确性,防止 reward hacking 等问题。 -
• Model-based Reward with Reference Answer:给每个 query 提供一个参考答案,用 Qwen2.5-72B-Instruct 来基于参考答案给模型的 response 打分。该方法允许更灵活地处理多样化任务,无需严格的格式命令,避免了 rule-based reward 的假阴性。 -
• Model-based Reward without Reference Answer:利用人类偏好数据,训练一个 Reward Model 来为每个 response 提供标量分数。
4.5 Strong-to-Weak Distillation
用于优化小模型,包括 5 个 Dense 模型(0.6B、1.7B、4B、8B、14B)和 1 个 MoE 模型(Qwen3-30B-A3B)。分为两个主要阶段:
-
• Off-policy Distillation:在这个初始阶段,将 /think 和 /no_think 模式下教师模型的输出结合起来,进行 response 蒸馏。 -
• On-policy Distillation:学生模型生成 on-policy 数据来微调。具体来说,以 /think 或 /no_think 模式对学生模型进行采样,通过将其 logits 与教师模型(Qwen3-32B 或 Qwen3-235B-A22B)的 logits 对齐来微调,最小化 KL 散度。
4.6 Post-training Evaluation
大量表格详见原始论文。
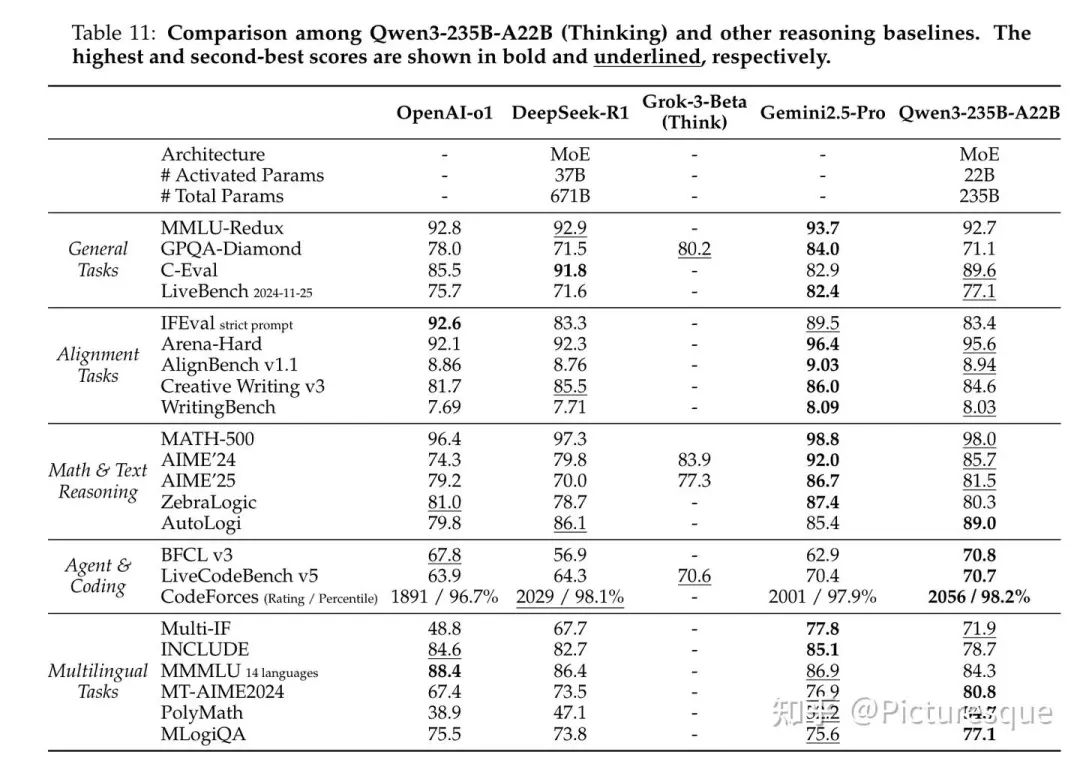
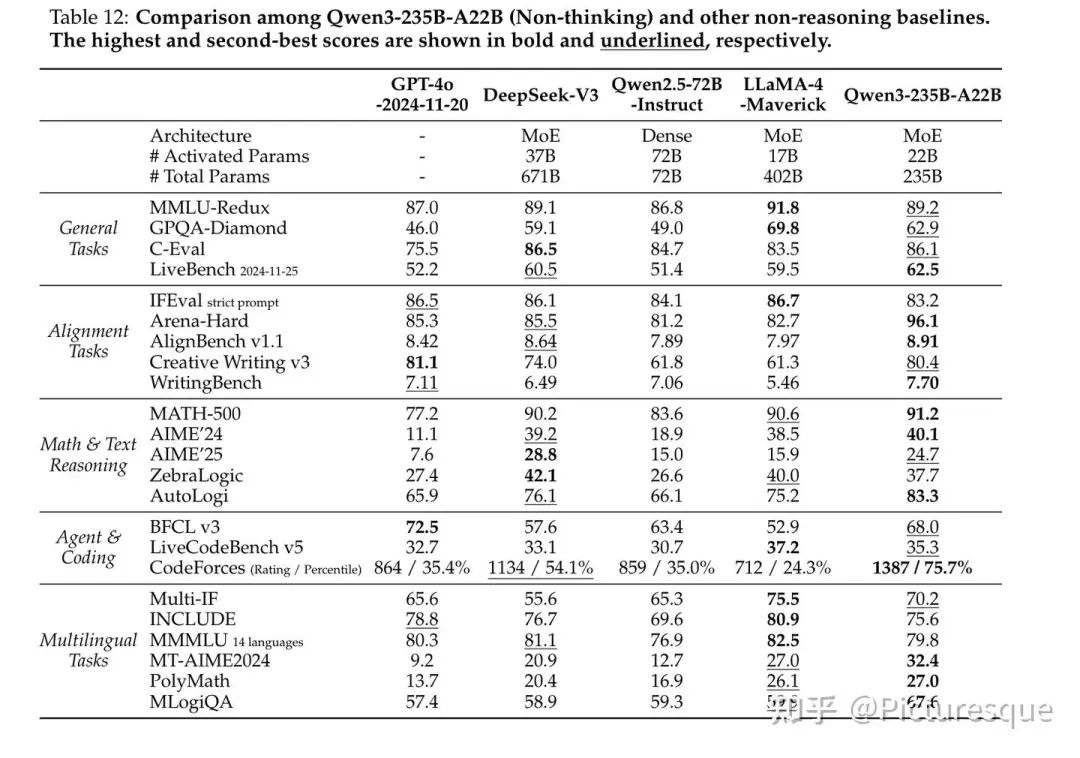
4.7 Discussion
The Effectiveness of Thinking Budget
为了验证 Qwen3 是否可以通过利用增加的思考预算来提升其智能水平,在数学、代码、STEM 领域的四个基准上调整了分配的思考预算。随着预算不断增加,思考模型表现出可扩展和平滑的性能提升。

The Effectiveness and Effciency of On-Policy Distillation

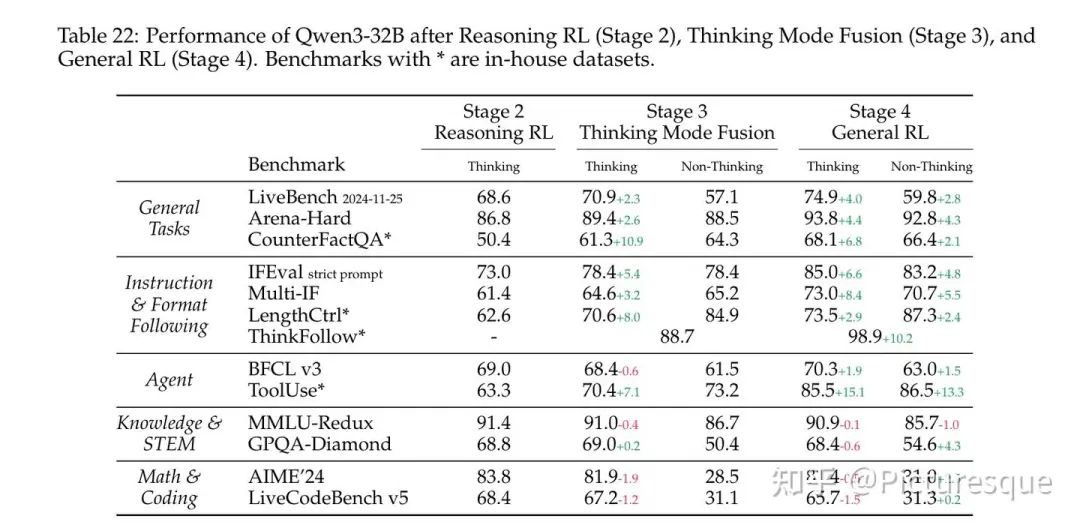
The Effects of Thinking Mode Fusion and General RL
评估 Thinking Mode Fusion (Stage3) 和 General RL (Stage4) 的有效性。额外加入几个内部 benchmark,包括:
-
• CounterFactQA:包含反事实问题,模型需要识别出问题反事实,避免生成幻觉答案。 -
• LengthCtrl:包括由长度要求的创意写作任务,最终得分基于生成内容长度与目标长度的差异。 -
• ThinkFollow:涉及多轮对话,随机插入 /think 和 /no_think 标志,测试模型能否正确切换模式。 -
• ToolUse:评估单轮、多轮、多步工具调用过程中的稳定性。得分包括工具调用意图识别的准确性、格式准确性、参数准确性。
(文:机器学习算法与自然语言处理)