
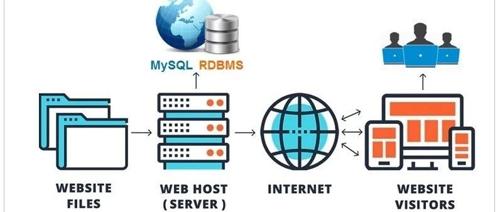
数据库是现代应用程序的数据核心,负责存储、管理和查询数据。随着数据规模和应用场景的多样化,数据库技术不断演进,形成了多种类型,每种类型针对特定需求进行了优化。本文将系统介绍主流数据库类型,包括关系型数据库、非关系型数据库(NoSQL,如键值存储、文档存储、列存储、图数据库、时间序列数据库),以及新兴的向量数据库,探讨它们的特点和适用场景。

关系型数据库:经典与可靠
关系型数据库(Relational Databases)是最传统的数据库类型,数据以表格形式存储,包含行和列,使用结构化查询语言(SQL)操作。它们依赖预定义的模式(Schema),确保数据结构严谨。
核心特点:
•结构化存储:数据遵循固定模式,适合结构化数据。•强一致性:支持ACID事务(原子性、一致性、隔离性、持久性),保证数据完整性。•复杂查询:支持联表查询(JOIN)和高级过滤。•成熟生态:拥有丰富的工具和社区支持。
适用场景:
•金融系统,如银行交易处理。•企业资源计划(ERP)和客户关系管理(CRM)。•需要强一致性和复杂查询的传统应用。
典型代表:MySQL、PostgreSQL、Oracle Database、Microsoft SQL Server。
局限性:
•可扩展性较弱,难以应对超大规模数据。•固定模式对动态或非结构化数据缺乏灵活性。
非关系型数据库(NoSQL):灵活与高效
非关系型数据库(NoSQL)是为解决关系型数据库局限性而设计的,特别适合大规模、非结构化或半结构化数据。NoSQL采用分布式架构,强调高可扩展性和性能,通常以最终一致性替代强一致性。
核心特点:
•灵活模式:支持多种数据模型,无需预定义结构。•分布式设计:易于水平扩展,适合大规模部署。•高性能:针对特定工作负载优化,延迟低。
适用场景:
•大数据处理,如社交媒体和电子商务。•实时分析和个性化推荐。•高并发、低延迟场景。
NoSQL数据库涵盖以下子类型:

1. 键值存储:简单高效
键值存储(Key-Value Stores)是NoSQL中最简单的类型,数据以键-值对形式存储,键为唯一标识,值可以是字符串、JSON等任意数据。
核心特点:
•极致性能:读写速度快,延迟低。•简单模型:易于开发和扩展。•分布式支持:适合大规模分布式系统。
适用场景:
•缓存,如网页内容或API响应。•会话管理,如用户登录状态。•配置存储。
典型代表:Redis、Amazon DynamoDB、Riak。
2. 文档存储:灵活的文档模型
文档存储(Document Stores)以文档形式存储数据,文档通常采用JSON、BSON或XML格式,包含键值对和嵌套结构。
核心特点:
•动态模式:无需固定结构,适应变化的数据需求。•嵌套支持:适合复杂、层次化的数据。•内容查询:支持基于文档内容的灵活查询。
适用场景:
•内容管理系统(CMS)。•电子商务平台,如产品目录。•实时数据分析。
典型代表:MongoDB、CouchDB、Google Firestore。
3. 列存储:分析利器
列存储(Column-Family Stores,或宽列存储)按列族组织数据,优化了大规模数据集的存储和查询。
核心特点:
•高效压缩:按列存储,压缩率高。•快速分析:适合读取大范围数据,分析查询性能优异。•高吞吐量:支持分布式环境下的高并发。
适用场景:
•数据仓库和商业智能。•日志和事件数据分析。•实时大数据处理。
典型代表:Apache Cassandra、HBase、Google Bigtable。
4. 图数据库:复杂关系专家
图数据库(Graph Databases)以节点和边表示数据,节点存储实体,边表示实体间的关系,适合处理复杂网络结构。
核心特点:
•高效关系查询:快速遍历复杂关系网络。•动态扩展:支持随时添加节点和边。•直观建模:自然表示关系数据。
适用场景:
•社交网络,如好友关系分析。•推荐系统,如产品推荐。•欺诈检测和知识图谱。
典型代表:Neo4j、ArangoDB、Amazon Neptune。
5. 时间序列数据库:时序数据优化
时间序列数据库(Time-Series Databases)专为时间戳数据设计,优化了存储和查询性能,适合高频时间序列数据。
核心特点:
•高效存储:高压缩率,减少存储空间。•快速查询:支持时间范围查询和数据聚合。•高写入性能:适应高频数据写入。
适用场景:
•物联网(IoT)设备数据。•系统监控,如服务器性能指标。•金融市场数据分析。
典型代表:InfluxDB、TimescaleDB、Prometheus。

6. 向量数据库:AI驱动的相似性搜索
向量数据库(Vector Databases)是近年来兴起的NoSQL类型,专为存储和查询高维向量数据设计,通常用于机器学习和人工智能场景。向量数据是将对象(如文本、图像)转化为高维数值向量(嵌入),以捕捉语义或特征。
核心特点:
•高效相似性搜索:支持快速的最近邻搜索(如KNN、ANN),基于向量距离(如欧氏距离、余弦相似度)查找相似项。•高维数据优化:针对高维向量数据的高效索引和查询。•灵活集成:与机器学习模型和嵌入生成工具无缝配合。
适用场景:
•语义搜索,如基于自然语言处理的文本搜索。•推荐系统,如基于用户行为或内容的个性化推荐。•图像和视频检索,如相似图像匹配。•异常检测,如基于向量特征的欺诈识别。
典型代表:Pinecone、Weaviate、Milvus、Qdrant。
局限性:
•专业性强,主要针对向量数据,通用性不如其他NoSQL类型。•对硬件资源(如GPU)需求较高,成本可能较高。
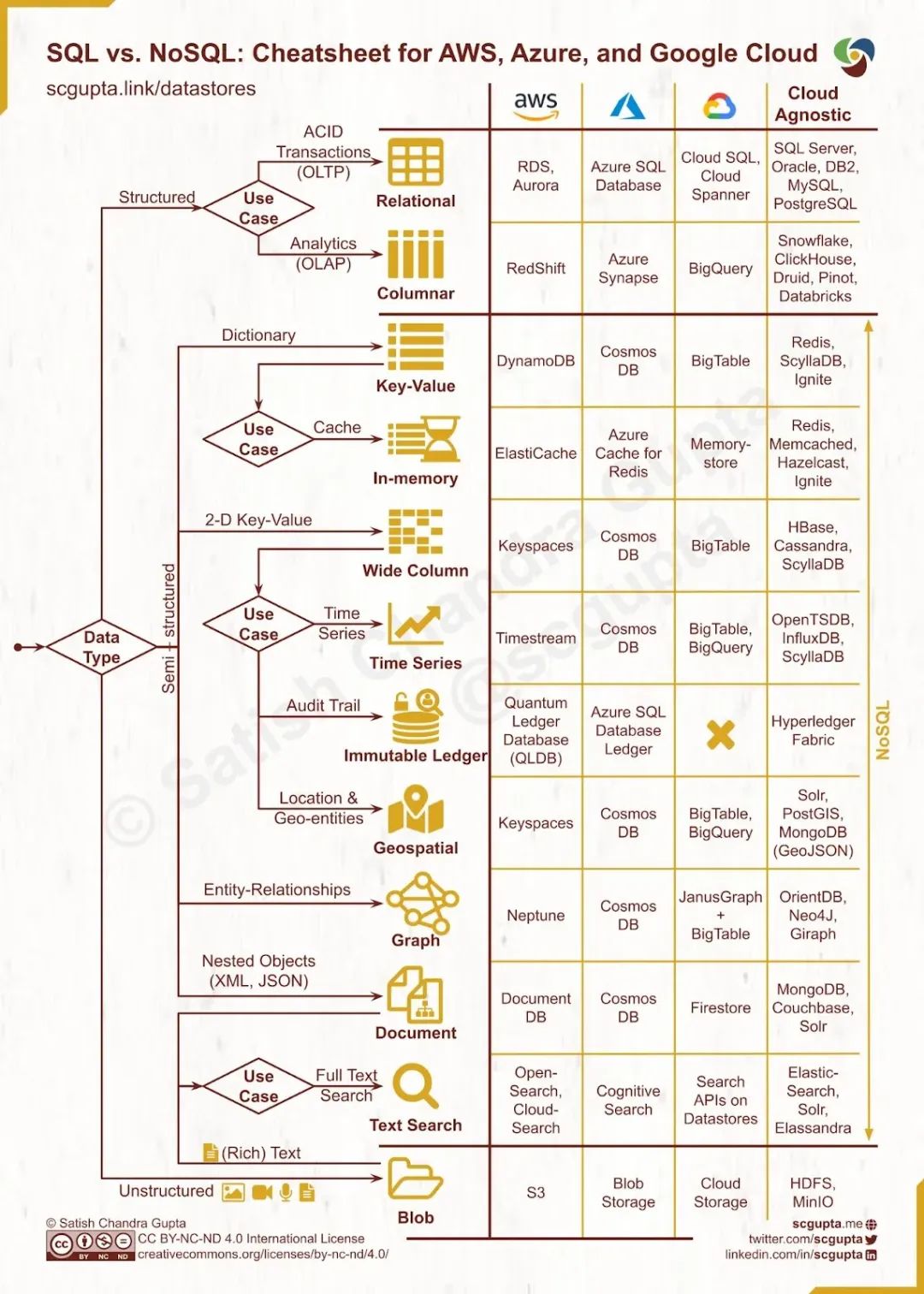
选择数据库的实用指南
选择合适的数据库需综合考虑以下因素:
•数据结构:结构化数据选关系型数据库,非结构化或半结构化选NoSQL,向量数据选向量数据库。•查询需求:复杂联表查询选关系型,关系网络选图数据库,分析查询选列存储,时间序列选时间序列数据库,相似性搜索选向量数据库。•可扩展性:高并发和大规模数据场景优先NoSQL或向量数据库。•一致性要求:强一致性选关系型,最终一致性选NoSQL。•性能需求:低延迟选键值存储,动态模式选文档存储,高维向量搜索选向量数据库。

总结
数据库类型多样,各有专长,满足不同场景的需求:
•关系型数据库:为结构化数据和强一致性提供可靠支持。•键值存储:以简单模型实现极致性能。•文档存储:灵活处理动态和半结构化数据。•列存储:优化大规模分析任务。•图数据库:高效处理复杂关系网络。•时间序列数据库:为时序数据提供专业优化。•向量数据库:为AI驱动的相似性搜索和嵌入处理提供高效支持。
通过深入理解各种数据库的特点和适用场景,开发者可以为应用程序选择最优的数据存储方案。随着技术发展,多模型数据库和AI驱动的向量数据库逐渐崭露头角,为更复杂的用例提供灵活支持。选择合适的数据库,将为你的应用奠定坚实的数据基础!
(文:PyTorch研习社)