


当前,多模态大语言模型(MLLMs)在视觉-语言理解任务中取得了令人瞩目的进展,其中视觉分词(vision tokenization)作为视觉与语言语义对齐的关键环节,发挥着至关重要的作用。
然而,现有方法往往采用将图像划分为规则网格(grid patch token)的方式,这种过度碎片化的分词策略破坏了视觉语义的完整性,导致视觉与语言表征之间难以实现有效对齐。
为此,本文提出了 Semantic-Equivalent Vision Tokenizer(SeTok),通过动态聚类算法,将视觉输入自适应划分为符合语义单元的 token,同时根据图像复杂度灵活调整 token 数量。SeTok 有效保留了低频与高频视觉特征,显著提升了视觉语义的完整性与表征质量。
基于 SeTok 构建的多模态大模型 Setokim,在多项任务上展现出优异性能,验证了语义等价视觉分词在多模态推理与生成中的潜力。

论文标题:
Towards Semantic Equivalence of Tokenization in Multimodal LLM
论文地址:
https://arxiv.org/pdf/2406.05127
项目&代码地址:
https://sqwu.top/SeTok-web/

现存方法存在的问题与研究动机
尽管现有多模态大语言模型(MLLMs)在各类任务中取得了优异表现,但视觉分词(visual tokenization)仍然是制约其进一步提升的核心瓶颈。
语言中的 word 天生具备离散型,通过分词能够自然划分出明确且完整的语义单元。相较而言,视觉中的像素是连续的、没有天然边界的连续信号。因此,理想情况下,语言中的 token 应该对应图像中封装语义完整的语义单元。
例如,当文本中提到“猫(cat)”,相应的视觉 token 应该是表征为精准地覆盖图像中“猫(cat)”的区域,如下图所示:
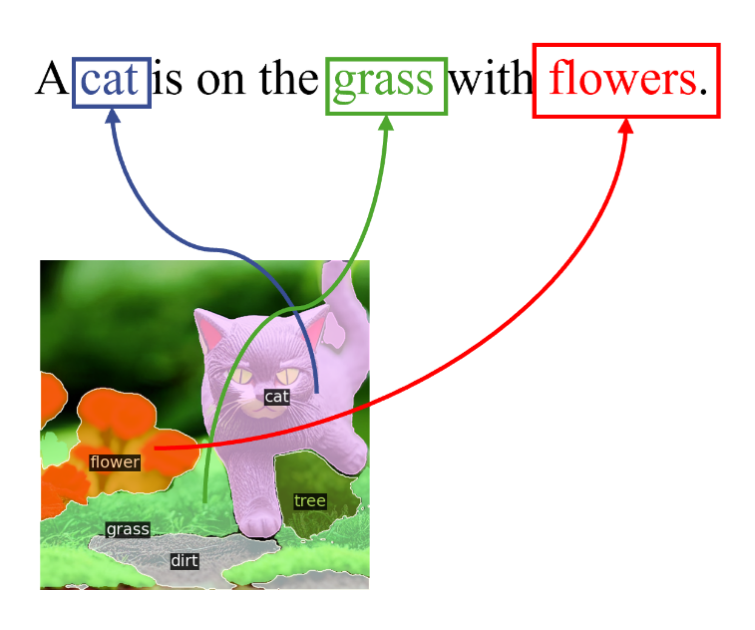
▲ 图1:图像与文本 token 之间的语义对等性
然而,现有主流视觉分词方法通常将图像均匀划分为固定大小的网格 patch,这种过度碎片化的处理导致同一对象被割裂在多个 patch 中,破坏了视觉语义单元的完整性,同时导致高频视觉信息(如物体的边缘与轮廓)的大量丢失。
此外,如果采用固定数量查询 token(query token)的方法,同样难以准确捕捉图像中的真实语义区域,且缺乏良好的可解释性。
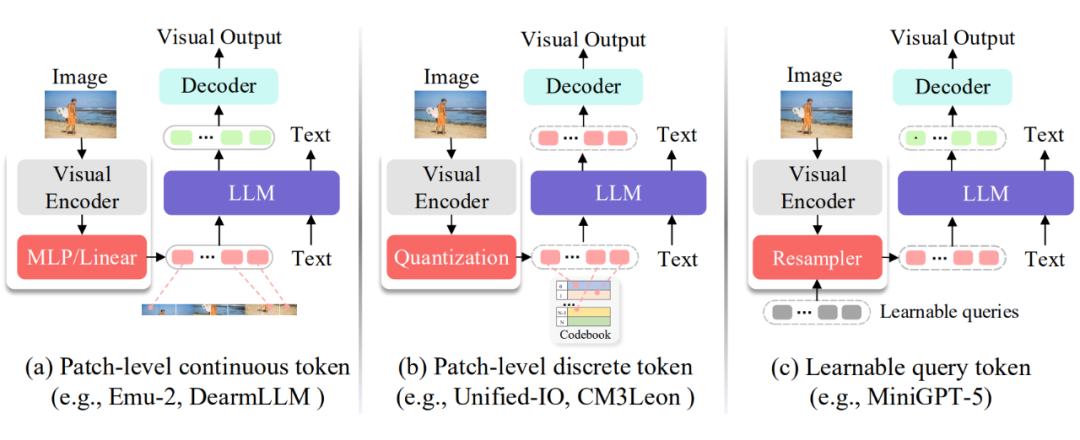
▲ 图2:现有的用于 MLLMs 的视觉 tokenizer

▲ 图3:Patch-level 离散与连续视觉 token 与语言 token 之间的语义对应关系
这种视觉与语言之间的对齐失真,严重限制了 MLLMs 对视觉信号的精确理解,尤其在需要细粒度语义对齐的复杂推理与生成任务中,成为模型性能提升的重要障碍。因此,如何在视觉分词阶段更好地保留视觉语义完整性,并实现更自然、更精准的视觉-语言对齐,成为亟需解决的问题。

方法
为了解决以上的问题,我们提出构建一个 Semantic-Equivalent Tokenizer(SeTok),旨在增强 MLLMs 中视觉与语言 token 的语义一致性。其核心思想是对输入图像的视觉特征进行自动聚类分组,使得到的每个聚类单元对应一个完整的视觉语义单元。
如下图所示,红色区域表征为“人(person)”这一概念(concept),而黄色区域表征为“帆板(surface board)” 这一概念(concept)。
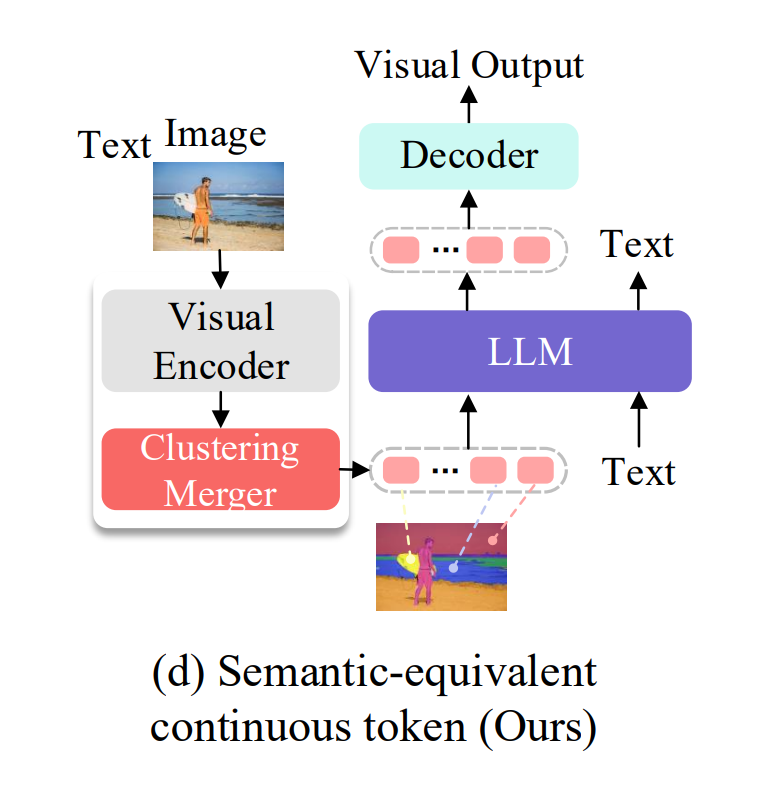
▲ 图4:本文提出的 Semantic-Equivalent Tokenizer(SeTok)
具体实现上,共包括 3 个步骤:
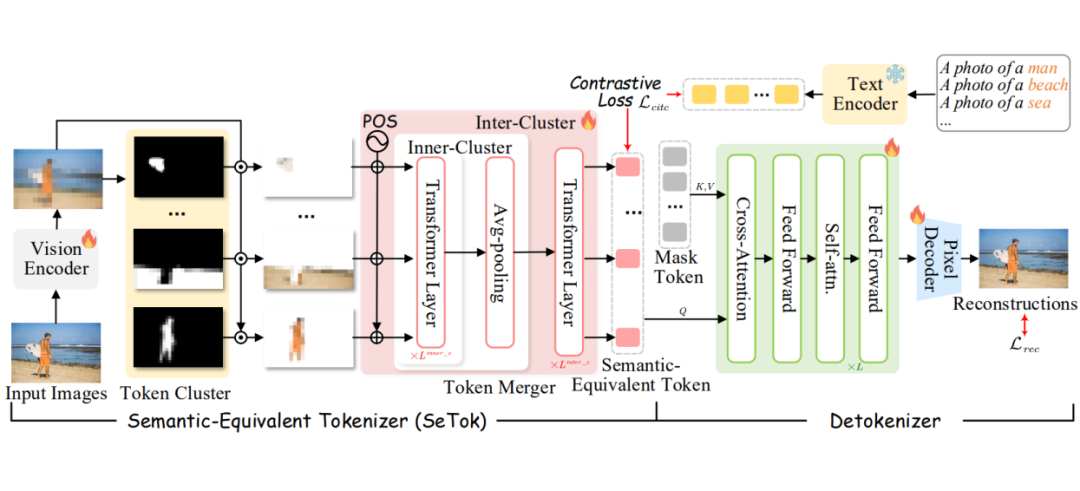
▲ 图5:SeTok 的整体结构示意图
2.1 Token Cluster
首先,给定输入的图片,我们首先利用视觉编码器将图像编码为视觉 patch embedding。然后,我们计算每个 patch (i,j) 的 density peaks:


通过将局部密度 和最小距离 结合起来,得到每个 patch 的 density peaks 分数 。根据得分 ,选择尚未被分配到聚类中的视觉特征中得分最高的位置(i,j),并将其迭代地分配到对应的聚类中。该过程重复进行,直到满足终止条件。
详细的算法如下:

最后,通过 token cluster,我们可以得到一个具有可变数量的语义概念掩码,其中 表示等价语义视觉 token 的数量。并且,对于图像中任意坐标位置为(i,j)的 patch token,满足 ,即每个 patch 被唯一分配到某一个语义概念中。
2.2 Token Merger
在完成聚类后,我们根据注意力掩码 𝑀 对视觉嵌入进行分组。为了在每个聚类中更充分地保留语义信息,我们引入了 token 聚合器(token merger),不再简单地使用聚类中心作为视觉 token 的代表,而是对每个聚类内的所有视觉嵌入进行特征聚合。
考虑到位置编码对于图像中语义概念的表示尤为重要,我们在聚合过程中引入了二维位置编码(2D Position Embedding,PE)。聚合特征计算方式为:
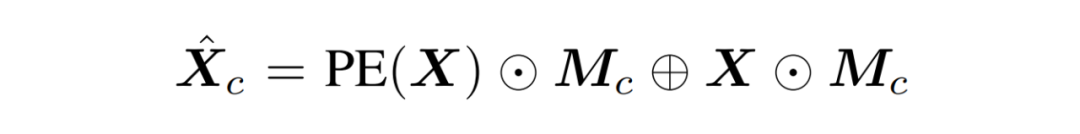
随后,我们对每个类内的视觉嵌入应用 Transformer 以建模局部上下文关系,并通过平均池化获取最终的 token 特征:
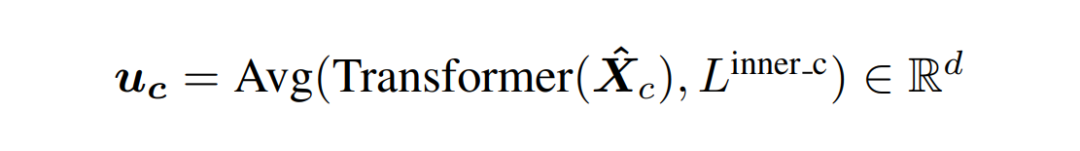
为了进一步建模不同语义 token 之间的上下文依赖关系,我们引入了跨聚类的 Transformer 层(inter-cluster Transformer),用于捕捉语义 token 间的相互关系。最终获得语义等价的视觉 token 序列:

2.3 SeTok Training
为了支持 MLLMs 在多样化的视觉理解与生成任务中的表现,我们认为,高质量的语义等价视觉 token 应同时具备两个关键属性:完备而丰富的高级语义信息,以及尽可能无失真的像素级细节。
为此,本文在训练阶段引入了概念级(concept-level)图文对比损失与图像重建损失(如上图 5 所示)。
首先,为了确保每个视觉 token 具备语义独立性与完整性,我们引入概念级(concept-level)图文对比损失。该损失在语义层面对齐视觉 token 与对应的文本概念,从而提升其在语言模型中的可集成性。
其次,为了保证生成的 token 能够保留充分的像素级图像细节,我们将这些 token 输入到一个解码器(Detokenizer),以重建原始图像,并据此计算图像重建损失。
最终,我们将对比损失与重建损失加权求和,从而在训练过程中同时优化语义保真度与视觉细节的保留能力:
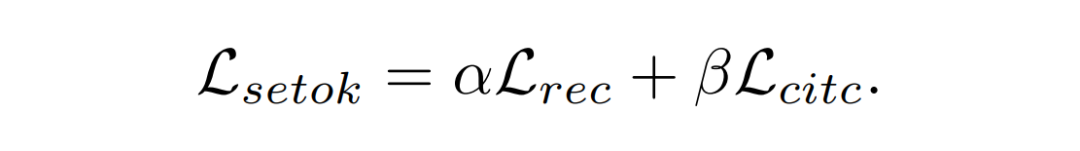
2.4 SeTok 与语言模型的集成:SETOKIM 框架
在获得语义等价视觉分词器 SeTok 之后,我们进一步将其集成到预训练大语言模型(LLM)中,构建出多模态大语言模型 SETOKIM。整体框架如图 6 所示。
具体来说,输入图像首先通过 SeTok 被分割为一系列语义等价的视觉 token,然后与文本 token 拼接,组成统一的多模态输入序列。为了区分模态并辅助视觉内容的生成,我们在视觉 token 序列前后分别引入两个特殊标记:[Img] 和 [/Img],用于标识视觉序列的起止位置。
接下来,主干 LLM 对该多模态序列进行处理,实现图文的联合理解与生成任务。生成的视觉 token 不仅可用于文本生成,还可进一步输入至视觉解码器(detokenizer),用于图像的重建。
此外,我们观察到,生成的以概念为中心的 token 天然编码了原图中每个概念的大致空间位置(如图 6 所示)。
为充分利用这一语义与空间联合嵌入的信息,我们引入了一个轻量级的掩码解码器(mask decoder),以生成的视觉 token 作为输入,预测图像中各语义概念的位置掩码(referring mask)。
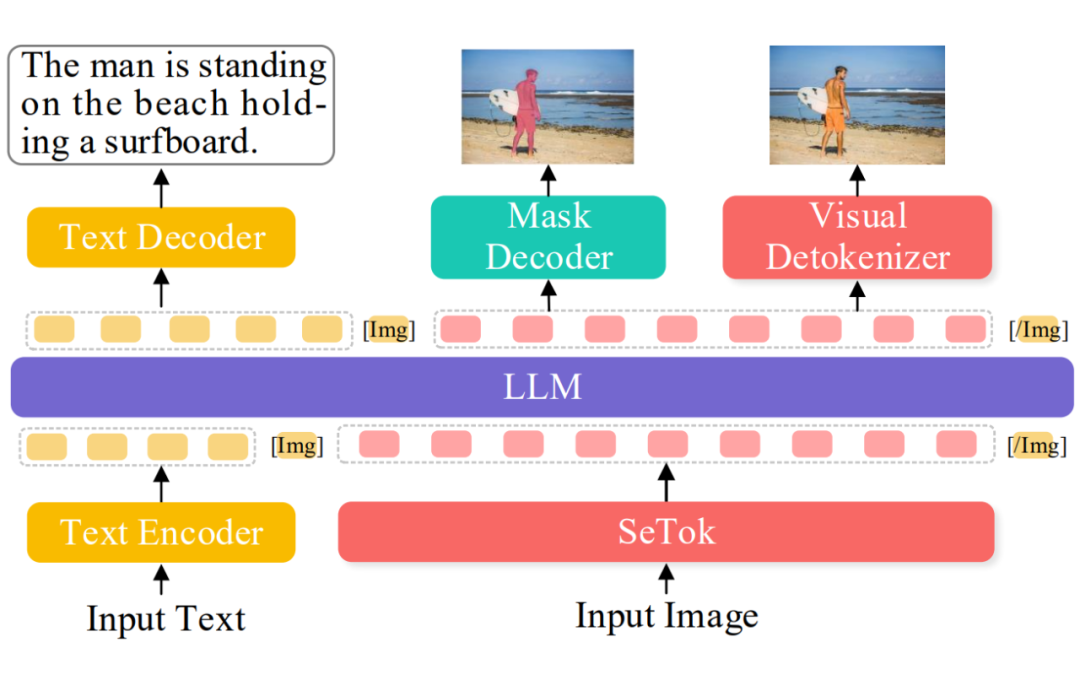
▲ 图6:通过整合 SeTok 与 LLM 提出的多模态语言模型——SETOKIM 的整体结构示意图
2.5 SETOKIM 训练
训练主要包含两个阶段:
-
阶段 1:多模态对齐预训练,我们在大量的 text-image pair 数据上进行对齐预训练。同时,我们也会引入纯文本训练数据保证模型对于文本理解的性能。
-
阶段 2:多模态指令训练。我们在大量为多模态指令数据集上进一步微调训练。

实验结果
3.1 视觉理解实验结果
我们在多个视觉理解基准任务上系统评估了所提模型与现有 MLLMs 的性能,详细结果见表 1。
通过引入语义等价视觉 token,我们的模型在各类视觉理解任务中取得了具有竞争力的性能表现。特别地,在 GQA 推理任务上,我们的方法带来了 3.6% 的准确率提升,进一步验证了 SeTok 在建模复杂关系推理与对象数量理解方面的显著优势。
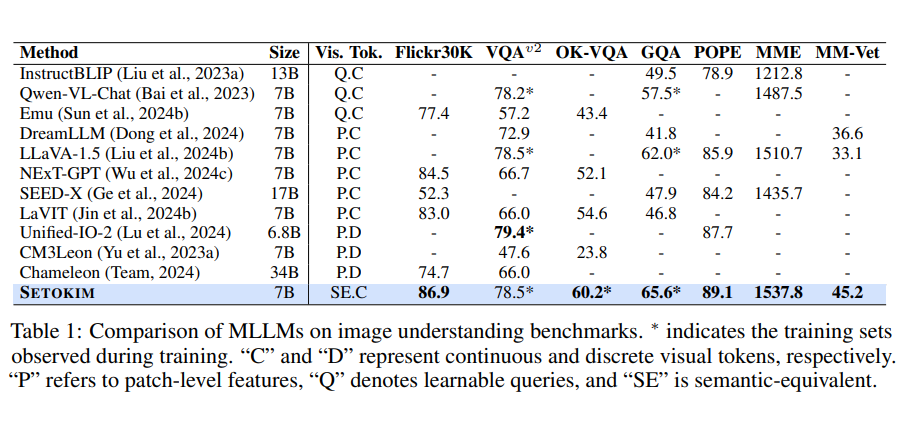
▲ 表1:现有模型与 SETOKIM 在多个视觉理解数据集上的性能比较

▲ 图7:视觉理解案例
3.2 视觉生成与编辑实验结果
进一步,我们比较了现有模型与 SETOKIM 在各个视觉生成与编辑的 benchmark 上的性能,实验结果如表 2 所示。通过进一步可视化发现,SETOKIM 在遵循用户指令和保持图像细节方面表现出更优异的性能。
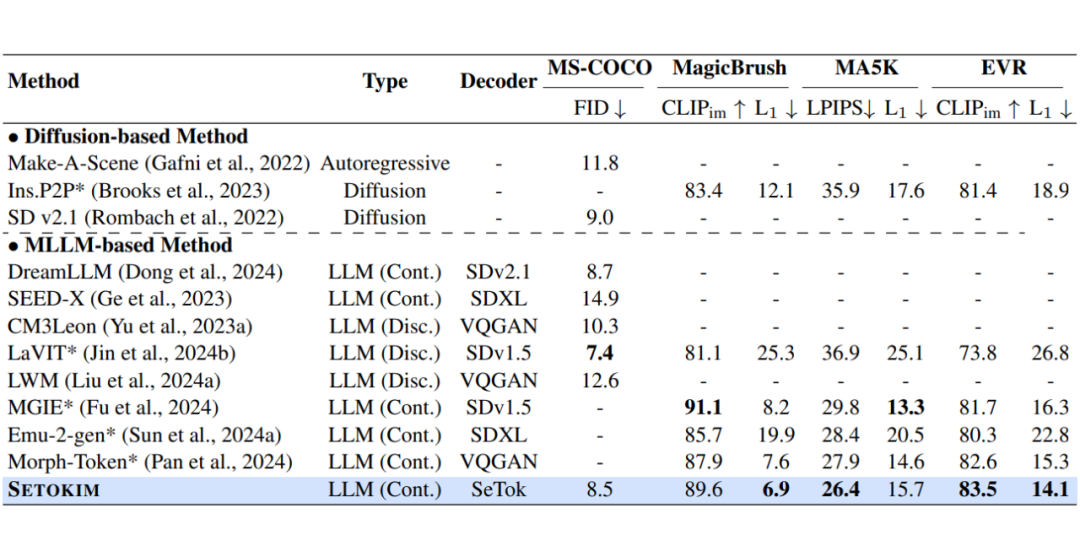
▲ 表2:现有模型与 SETOKIM 在多个视觉生成与编辑数据集上的性能比较

▲ 图8:视觉编辑结果案例
3.3 指代表达分割实验结果
同时,在指代表达分割的数据集上,我们的模型获得了更优的性能,实验结果如表 3 所示。 通过可视化分析可以直观地观察到,模型生成的注意力掩码能够紧密对齐于目标物体的真实分割掩码,且 SETOKIM 在分割精度与细节完整性方面,相较于其他基于大语言模型(LLM-based)的分割方法表现更为出色。

▲ 表3:现有模型与 SETOKIM 在多个指代表达分割数据集上的性能比较

▲ 图9:指代分割案例可视化
3.4 视觉语义token 可视化分析
最后,我们可视化了输入视觉特征在经过分词(tokenization)后的分配情况,如图 10 所示。

▲ 图10:视觉 token 可视化

总结
本文提出了 SeTok,一种实用的语义等价视觉分词器,能够将 patch 级别的视觉特征自适应划分为可变数量的语义完整的概念视觉 token。
随后,我们将 SeTok 集成到预训练大语言模型(LLM)中,构建了统一的多模态大模型 SETOKIM。
在大量实验中,SETOKIM 在理解、生成、分割与编辑等多种任务上均取得了优异表现,充分验证了 SeTok 在提升多模态模型性能方面的重要作用。
(文:PaperWeekly)