

今天是2025年5月7日,星期三,北京,晴。
我们今天来看两个问题。
一个是关于Graph用于记忆管理。由于LLMs无法在超出其上下文窗口的对话中维持连贯性,这限制了它们在长时间交互中的表现,所以解决的思路就是采用可扩展的记忆中心架构,通过动态提取、整合和检索对话中的重要信息。这么一来,目前用Graph来做Agent记忆管理看来是个趋势,因为正好涵盖住了抽取、整合以及检索几个步骤。所以,我们来看两个代表工作。
另一个是看看领域RAG的进展,关于医药领域的一个RAG总结,Retrieval-Augmented Generation in Biomedicine: A Survey of Technologies, Datasets, and Clinical Applications,https://arxiv.org/pdf/2505.01146,探讨RAG在生物医学领域的应用,重点关注其技术组件、可用数据集和临床应用。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Mem0^g:基于GraphRAG进行Agent记忆管理实现解析
目前Graph用于Agent记忆管理已经有了几个代表工作。
例如,之前说过的,GraphRAG用在agent进展,在文章《GraphRAG如何用于Agent做memory记忆管理?Graphiti实现解读及相关技术进展回顾》(https://mp.weixin.qq.com/s/S8BG_XIQ3FIYKNq_RsC0AQ)中有介绍过《Zep: A Temporal Knowledge Graph Architecture for Agent Memory》(https://arxiv.org/pdf/2501.13956,https://github.com/getzep/graphiti,https://github.com/getzep/graphiti/blob/main/mcp_server/README.md)的工作,这个工作也搞成了MCP就叫做Graphiti MCP Server,直接理解就是,用来管agent里面memory的graphrag,把agent 的memory 进行graph化存储跟检索的组件。
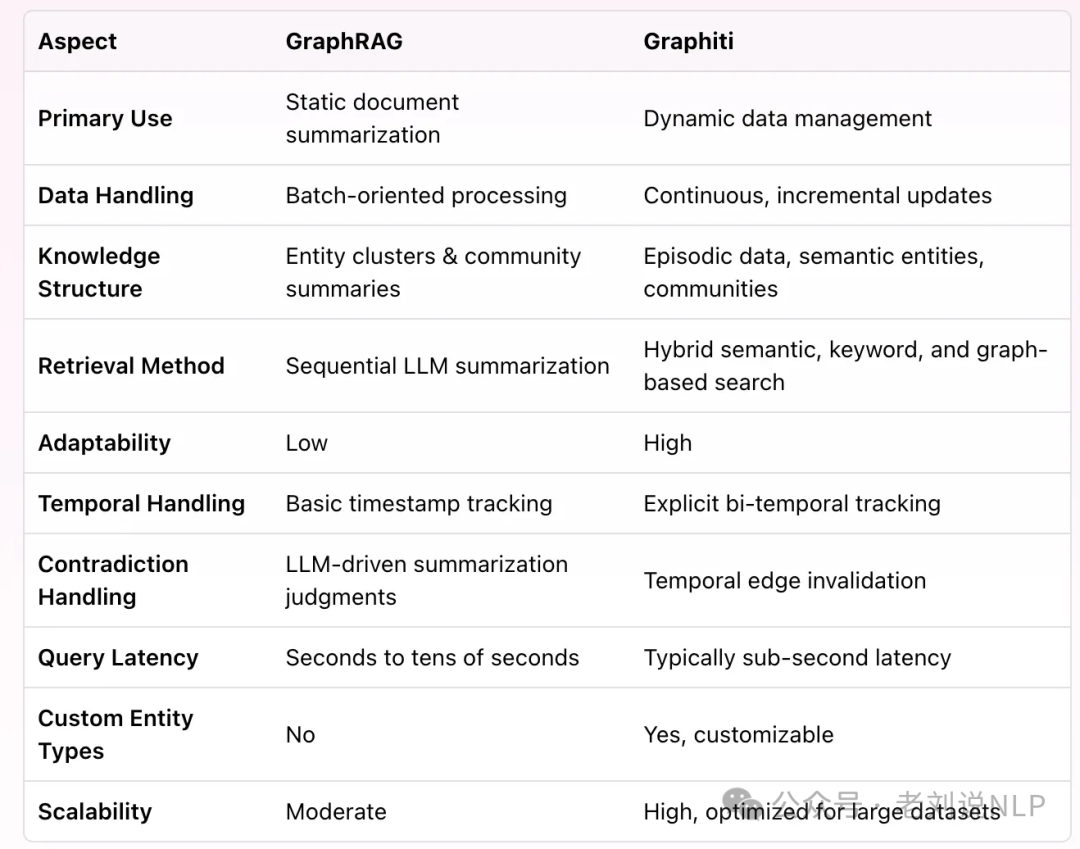
现在整理成论文的,也有一个新的工作,《Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory》(https://arxiv.org/pdf/2504.19413v1,https://mem0.ai/research),提出了一个增强版本Mem0^g,利用基于图的记忆表示来捕捉对话元素之间的复杂关系,从论文表述来看,与其他方法相比,Mem0和Mem0g在保持高精度的同时,显著降低了计算开销,社区成员实际使用过程中也有如此发现。

我们来看看具体是怎么做的。
1、Mem0方案
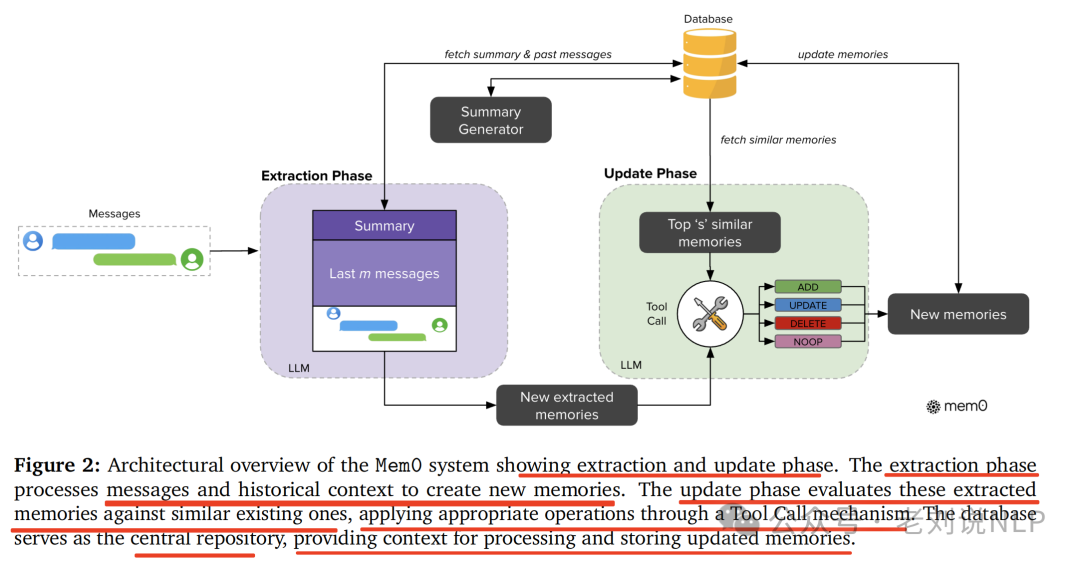
先看不带Graph的方案,Mem0,实现逻辑是通过专用模块从对话中提取、评估和管理重要信息,系统的完整流程包括提取和更新两个阶段。
其中:
在提取阶段,当摄入一对新消息时,系统利用对话摘要和最近的消息序列作为上下文,通过LLM提取一组显著的记忆。
具体地,在摄入一条新的消息对(mt−1,mt) 时启动,其中mt代表当前消息,mt−1代表前一条消息。这对通常包括一条用户消息和一条助手回复,捕捉了一个完整的互动单元。
为了为记忆提取建立适当的上下文,系统采用两个互补的来源:(1)从数据库检索的对话摘要S,封装了整个对话历史的语义内容,以及(2)**对话历史中的一系列最近的消息{mt−m,mt−m+1,…,mt−2}**,其中m是控制最近窗口大小的超参数。
为了支持上下文感知的记忆提取,采用一个异步摘要生成模块,该模块定期刷新对话摘要。这个组件独立于主处理流程运行,确保记忆提取始终受益于最新的上下文信息,而不会引入处理延迟。虽然S提供了整个对话的全局主题理解,但最近的消息序列提供了可能包含摘要中未合并的相关细节的细粒度时间上下文。
这种双重上下文信息与新的消息对相结合,形成提示**P=(S,{mt-m,…,mt-2},mt-1,mt),用于通过大模型实现的提取函数ϕ,然后函数ϕ(P)专门从新交流中提取一组显著的记忆Ω={ω1,ω2,…,ωn}**,同时保持对对话更广泛上下文的认识,从而得到可能包含在知识库中的候选事实。
提取后,更新阶段将每个候选事实与现有记忆进行对比,以保持一致性和避免冗余。该阶段确定每个提取出的事实ωi∈Ω的适当记忆管理操作。
这个更新操作,就是比对操作,算法如下,做的是一个遍历操作,并且还是个分类路由,需要判定出来是具体哪种操作。

具体实现还蛮有趣:
对于每个事实,系统首先使用向量嵌入从数据库检索前s个语义上相似的记忆。这些检索到的记忆与候选事实一起通过称之为“工具调用”的函数调用接口呈现给大模型,LLM本身决定执行四种不同操作中的哪一种:当不存在语义上等效的记忆时,使用ADD创建新记忆;使用UPDATE用补充信息增强现有记忆;使用DELETE移除与新信息相矛盾的记忆;当候选事实不需要修改知识库时使用NOOP。
但是,不是使用单独的分类器,而是利用LLM的推理能力直接基于候选事实与现有记忆之间的语义关系选择合适的操作。在此决定之后,系统执行提供的操作,从而保持知识库的一致性和时间上的连贯性。
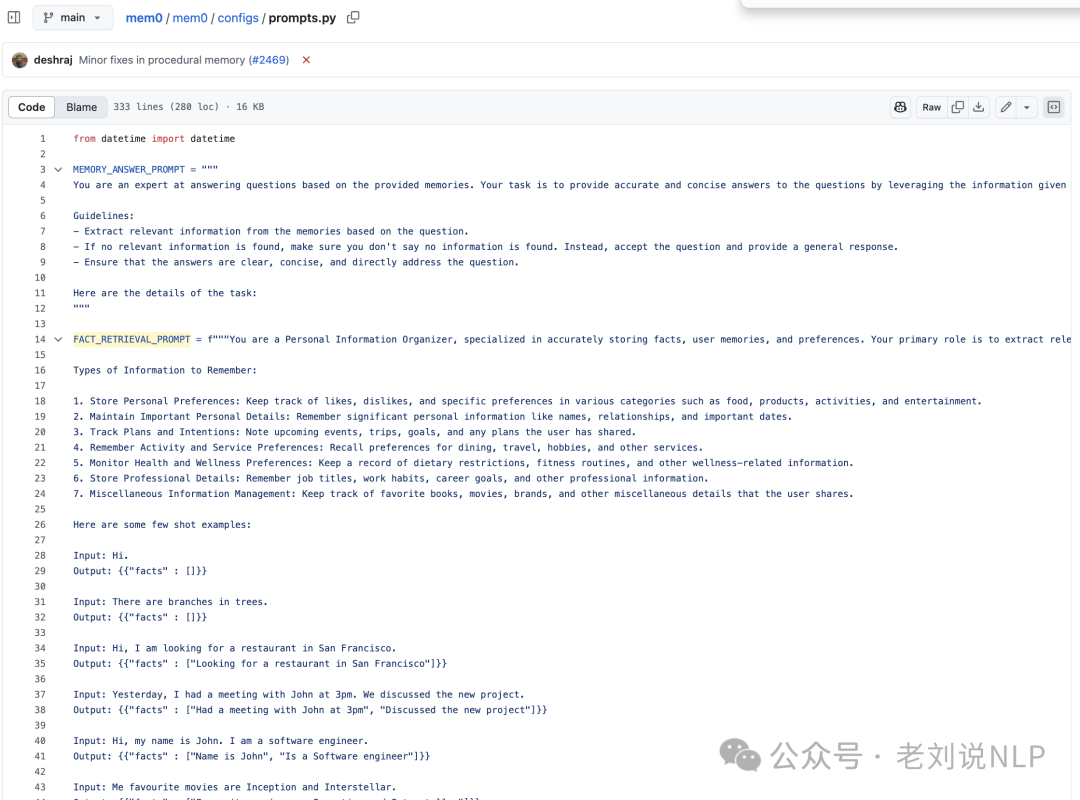
在检索阶段,核心还是对应的prompt,工作量很大,放在https://github.com/mem0ai/mem0/blob/main/mem0/configs/prompts.py,涉及到MEMORY_ANSWER_PROMPT、FACT_RETRIEVAL_PROMPT以及等。
2、Mem0^g
再看带Graph的方案Mem0^g,实现思路是通过图内存表示法扩展Mem0的基础架构,从而更有效地捕捉、存储和检索上下文信息。
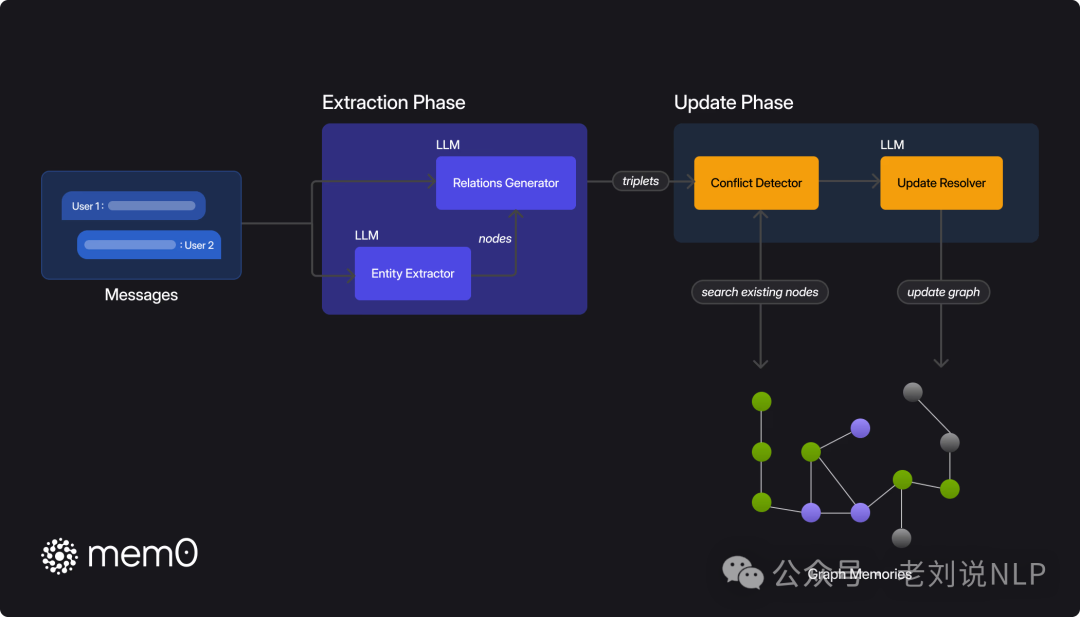
在此框架中,首先是记忆的定义,记忆被表示为有向标记图G=(V,E,L),其中:
节点V代表实体(例如,ALICE,SAN_FRANCISCO);边E代表实体间的关系(例如,LIVES_IN);标签L为节点分配语义类型(例如,ALICE-person,SAN_FRANCISCO-city)
每个实体节点v∈V包含三个组成部分:(1)实体类型分类,对实体进行分类(例如,人、地点、事件);(2)捕捉实体语义含义的嵌入向量e;(3)包括创建时间戳tv在内的元数据。
系统中的关系被结构化地表示为三元组(vs,r,vd)的形式,其中vs和vd分别是源和目标实体节点,r是连接它们的标记边。

然后是记忆单元的提取,采用了一个两阶段流程,利用大模型将非结构化文本转换为结构化图形表示,处理后,保存在neo4j数据库中,并且很有趣的是,每个处理组件,都封装成了tools的形式,如https://github.com/mem0ai/mem0/blob/main/mem0/graphs/tools.py中可以看到。
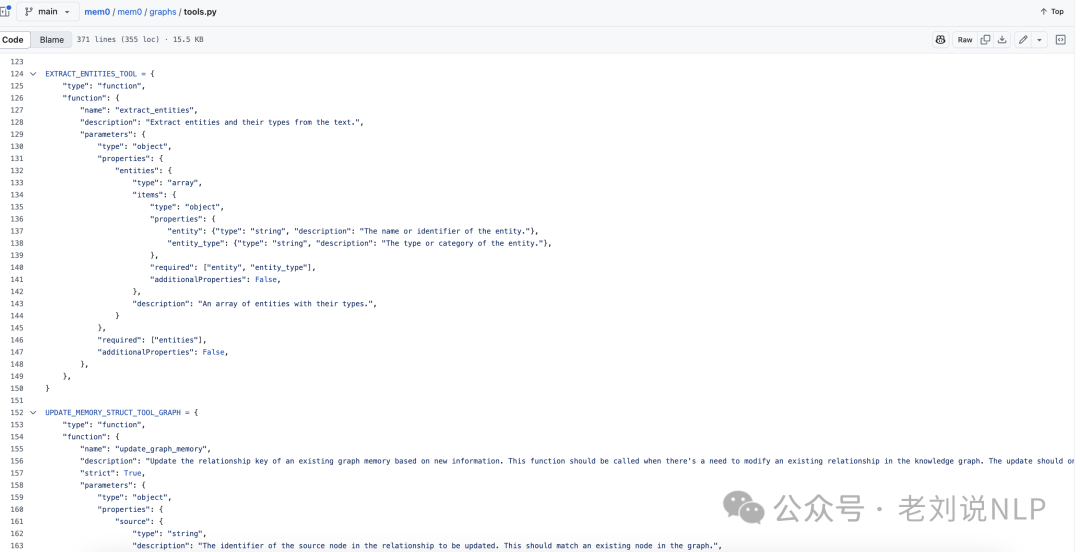
首先,实体提取,输入文本以识别一组实体及其对应的类型。实体代表对话中的关键信息元素——包括人、地点、物体、概念、事件以及值得在记忆图中表示的属性。实体提取器通过分析对话中元素的语义重要性、唯一性和持久性来识别这些多样化的信息单位。例如,在关于旅行计划的对话中,实体可能包括目的地(城市、国家)、交通方式、日期、活动以及参与者的偏好,这种是任何可能对将来参考或推理有关的离散信息。
实体抽取的prompt很简单,可以看看https://github.com/mem0ai/mem0/blob/main/mem0/memory/graph_memory.py中的_retrieve_nodes_from_data函数,如下:

接下来,关系生成。推导出这些实体之间有意义的关系,建立一组捕捉信息语义结构的关系三元组。也是基于大模型来做的,通过分析提取出的实体及其在对话中的上下文,以识别语义上重要的联系。对于每一对潜在的实体,评估是否存在有意义的关系,如果存在,则用适当的标签(例如,“居住在”、“偏好”、“拥有”、“发生在”)对这种关系进行分类。
这块的逻辑在:https://github.com/mem0ai/mem0/blob/main/mem0/graphs/utils.py
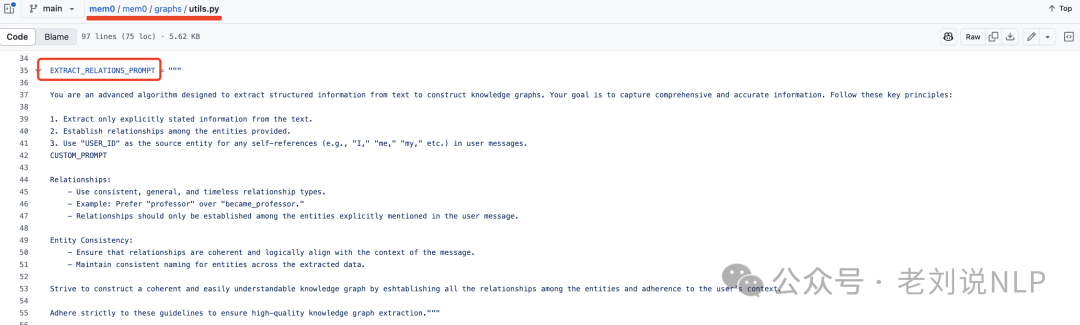
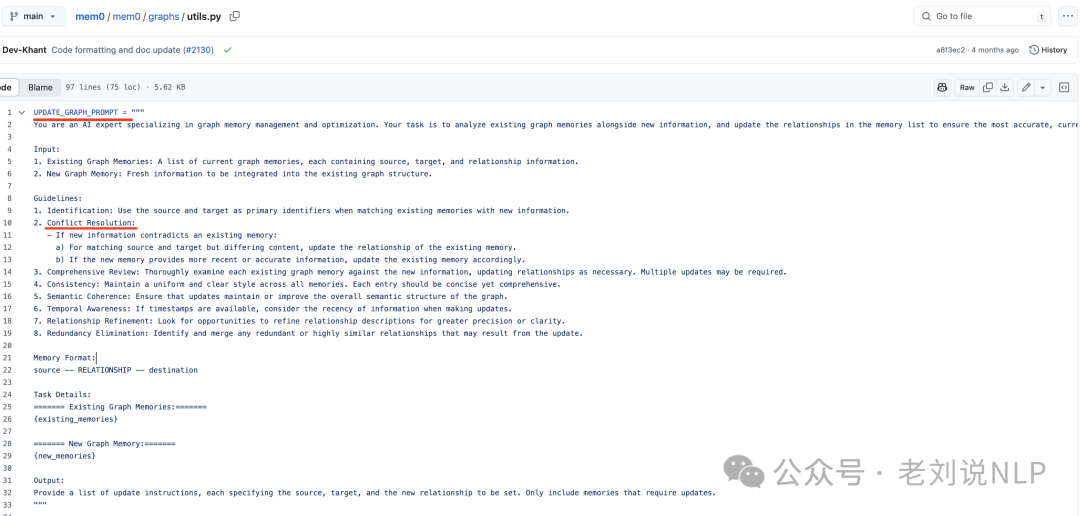
最后是信息整合。对于每个新的关系三元组,计算源实体和目标实体的嵌入,然后在定义的阈值’t’以上搜索具有语义相似性的现有节点。根据节点的存在情况,系统可能会创建两个节点、只创建一个节点,或在用适当的元数据建立关系之前使用现有节点。为了维护一致的知识图谱,实施一个冲突检测机制,当新信息到来时识别可能发生冲突的现有关系。这里,基于大模型的更新解析器确定某些关系是否应该被淘汰,将其标记为无效而不是物理上移除它们,以支持时间推理。这块实现逻辑在:https://github.com/mem0ai/mem0/blob/main/mem0/graphs/utils.py,其中涉及到UPDATE_GRAPH_PROMP,如下:
当然,既然库建立好了,那就需要进行检索,也需要配套的检索设施。所以也来看下Mem0g中的记忆检索功能采用双策略方法以优化信息访问,也就是如下图的实体为中心和语义三元组为中心的方式去做。
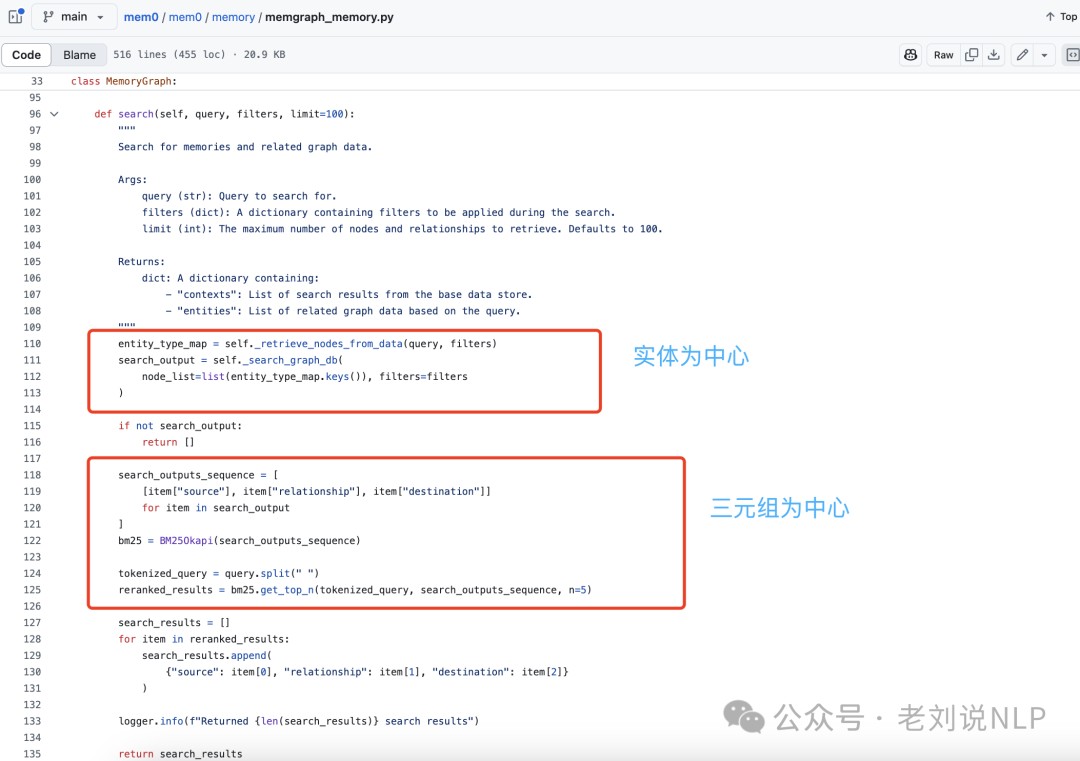
一个是以实体为中心的方法,首先识别查询中的关键实体,
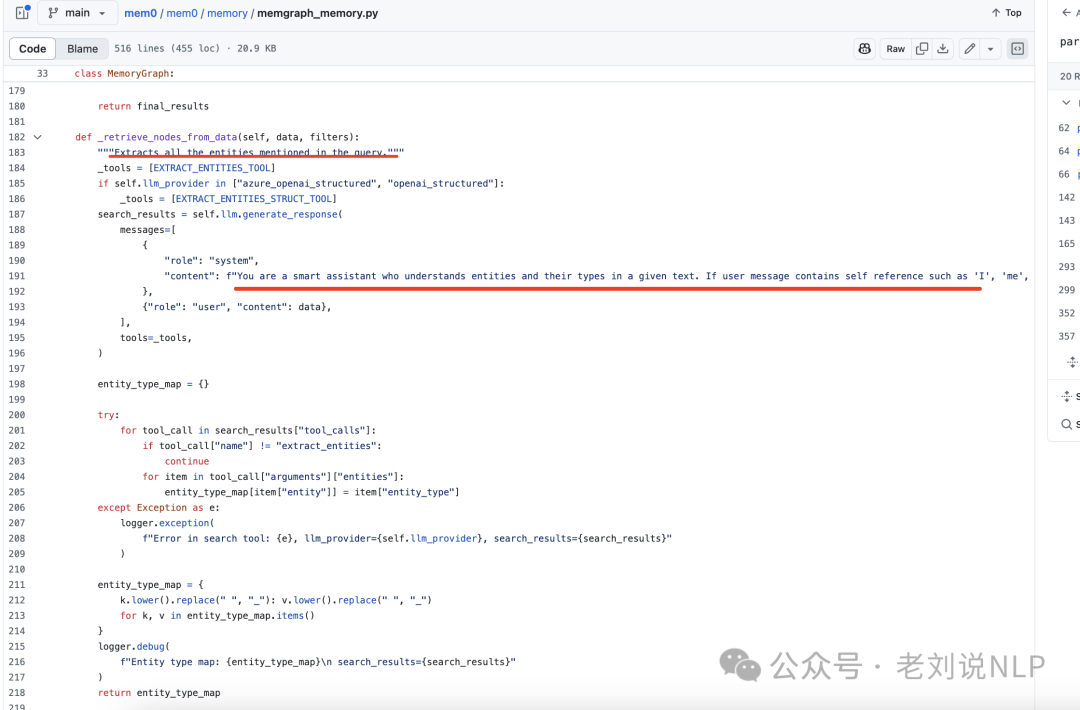
然后利用语义相似性在知识图中定位相应的节点,然后基于neo4j-cypher这些锚节点的输入和输出关系,这个cypher语句写的很长,构建一个子图,捕捉相关的上下文信息。
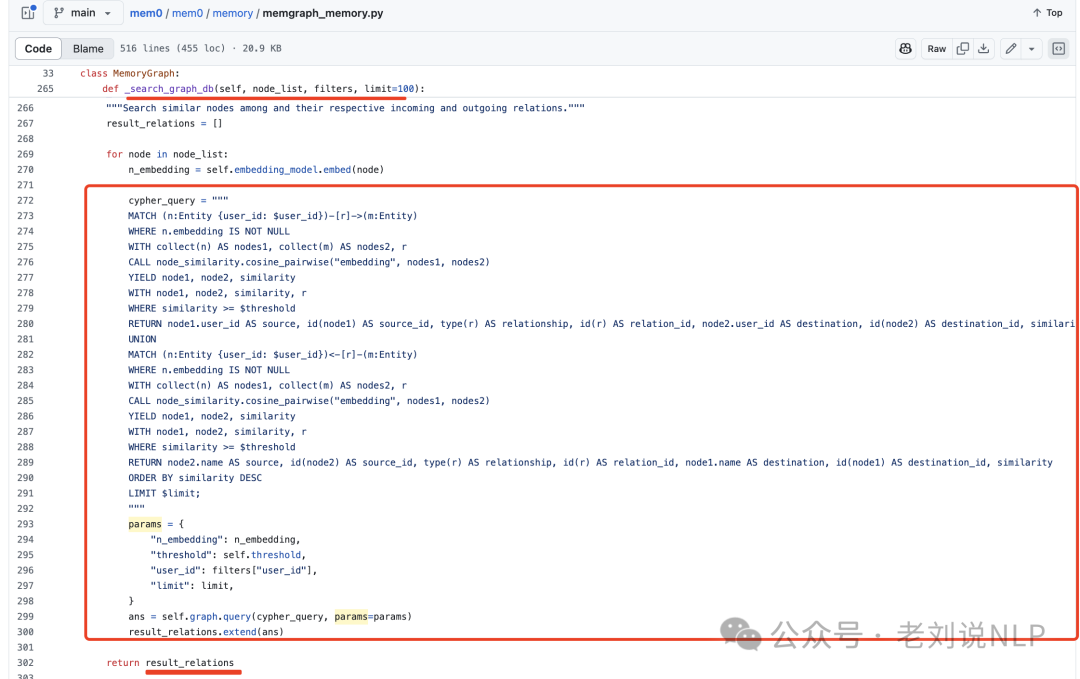
一个是语义三元组方法,通过将整个查询编码为一个密集嵌入向量,然后与上一步骤中输出的每个关系三元组的文本编码进行匹配。
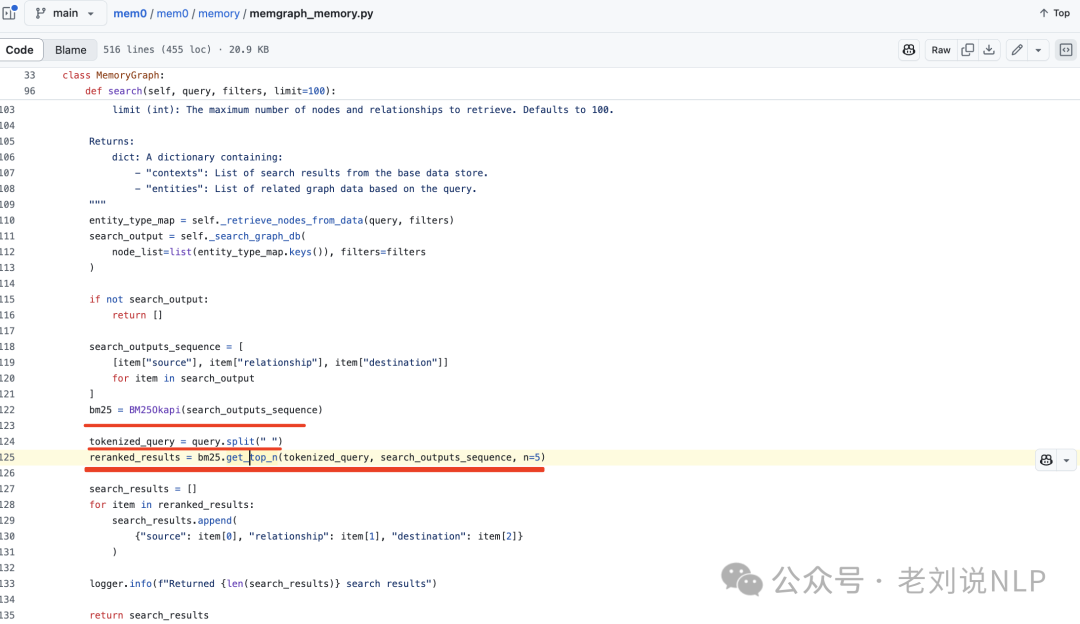
这个步骤,其实事串行的,起到的是一个rerank的作用,使用bm25做的。
3、简单角度看具体如何操作的?
在https://github.com/mem0ai/mem0中,我们可以开箱即用、很清晰的看到里面的使用方式。执行Retrieve relevant memories->Generate Assistant response->Create new memories from the conversation三个步骤,如下:
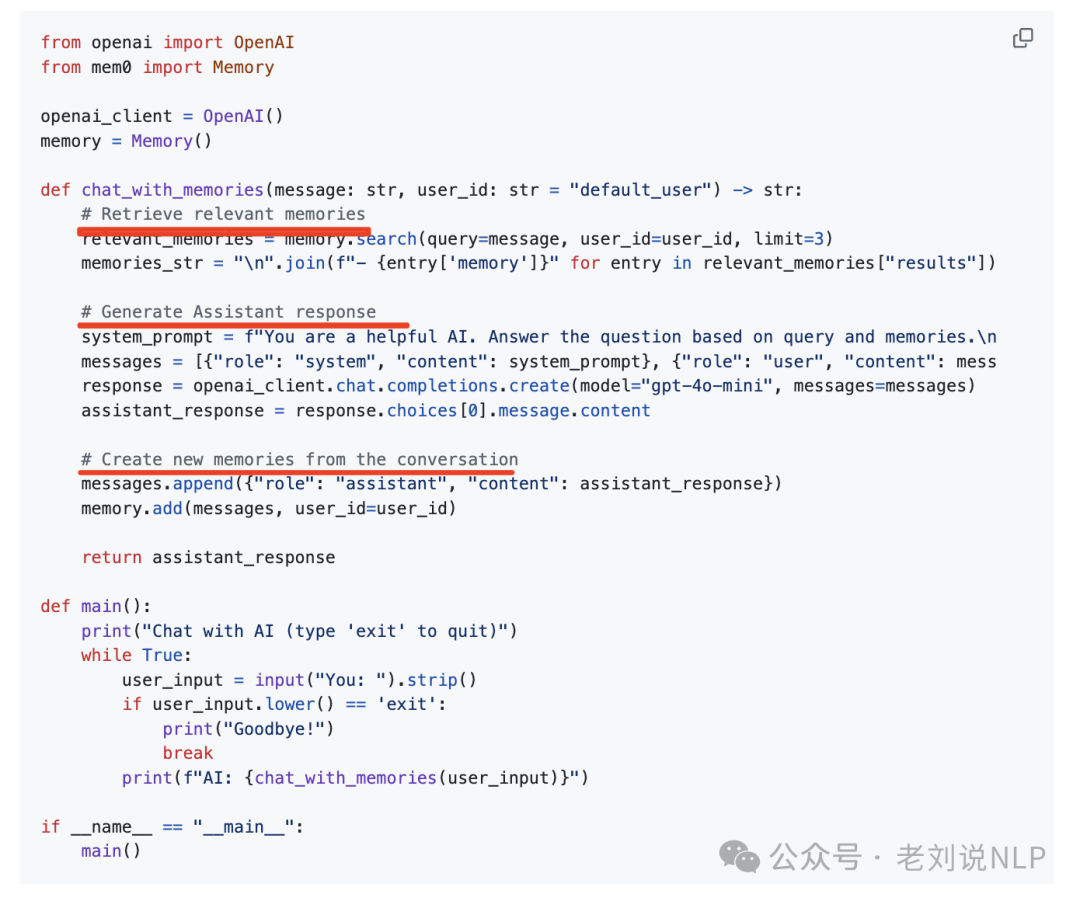
从其表述来看,其发现,与其他方法,例如 A-Mem、LangMem、Zep、OpenAI,Mem0和Mem0g在保持高精度的同时,显著降低了计算开销。

但是,具体情况如何表现,需要我们具体测试,以实际测试为准。
二、医药领域RAG技术总结
我们再来看看领域RAG的进展,关于医药领域的一个RAG总结,最近的工作《Retrieval-Augmented Generation in Biomedicine: A Survey of Technologies, Datasets, and Clinical Applications》,https://arxiv.org/pdf/2505.01146,探讨RAG在生物医学领域的应用,重点关注其技术组件、可用数据集和临床应用。
例如,在应用方面,包括临床决策支持系统:RAG系统在证据支持的问答平台中的应用,如Clinfo.ai;医学问答:提供准确的医疗信息以支持临床决策;诊断和治疗决策支持:通过连接电子健康记录和医疗知识库来增强诊断预测;罕见病识别和管理:利用RAG系统聚合和综合知识以识别和管理罕见病;临床报告生成:通过RAG框架自动生成放射学报告。
由于医药领域,很多都是结构化数据形式,如有许多知识图谱,所以是个很好的知识图谱RAG的试验场,也就是知识图谱增强的检索,如下:
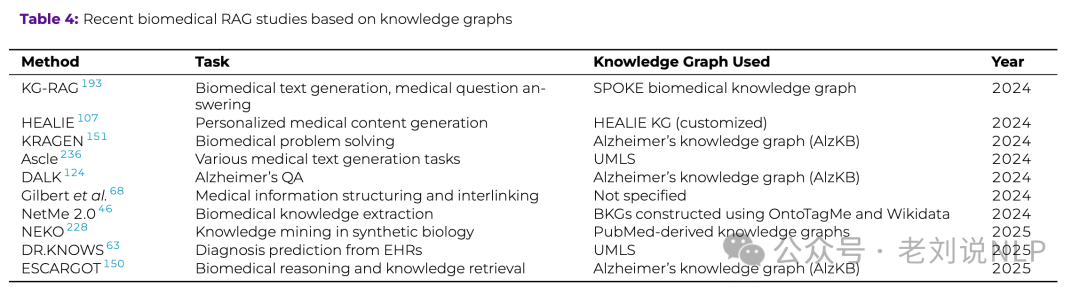
实现流程如下:
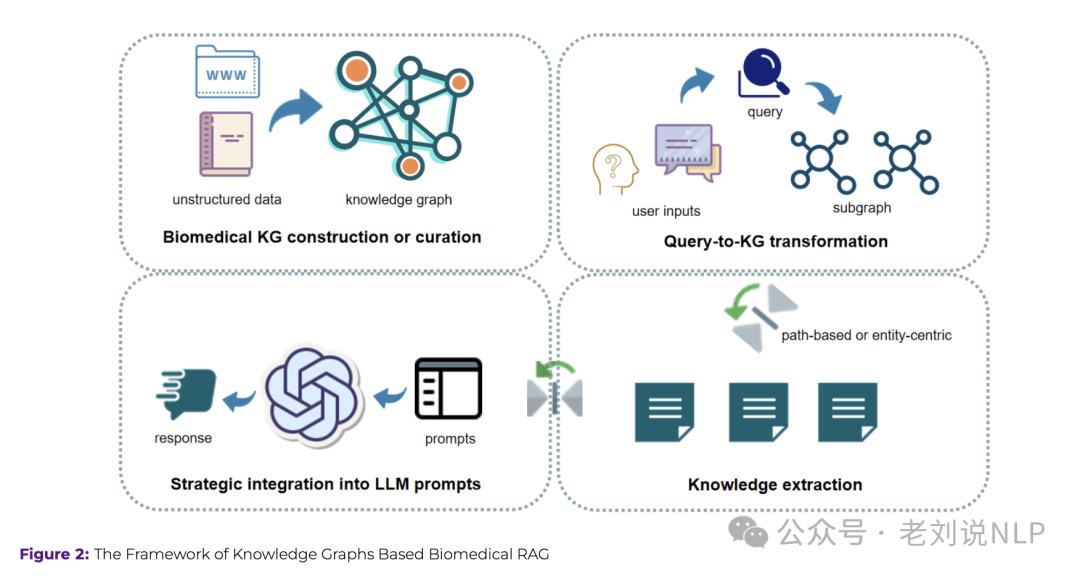
此外,医药领域还涉及到许多医学影像如医学图像、心电图(ECG)和其他临床测量数据,所以多模态RAG也有用武之地,因此,也有一些应用点,如弱视检测、处方标签解读、肺癌分期、数字病理分析以及自动化放射科报告生成。
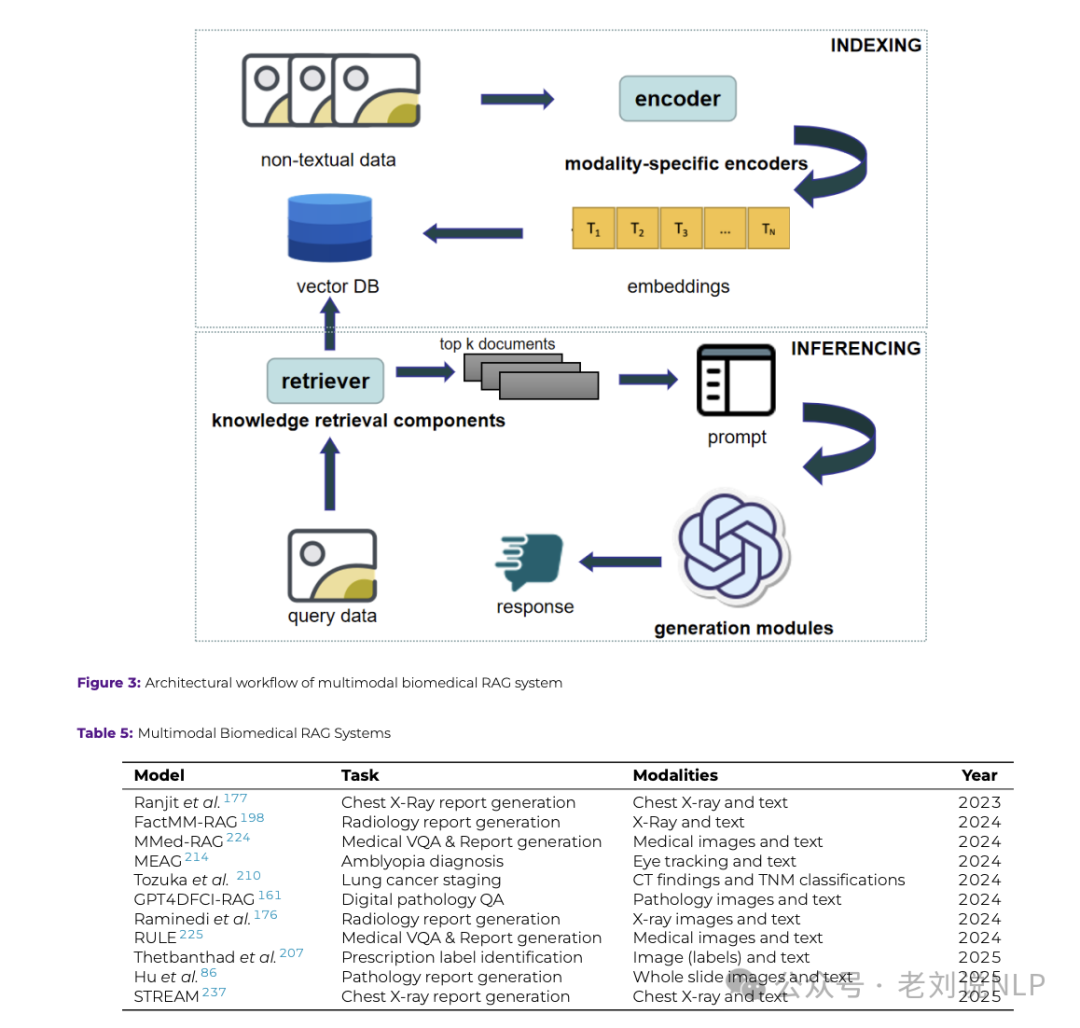
但无论怎么用,数据还是需要的,所以也可以看看医药领域的一些任务数据集,如下:

总结
本文主要介绍了两个工作,一个是Graph用于记忆管理的工作,从中可以看看两个开发框架。另一个是医药领域RAG的总结,包括KGRAG以及多模态RAG的一些总结性工作,这些都可以深入了解。
参考文献
1、https://arxiv.org/pdf/2504.19413v1
2、https://mem0.ai/research
3、https://mp.weixin.qq.com/s/S8BG_XIQ3FIYKNq_RsC0AQ
(文:老刘说NLP)