

北航联合团队 投稿
量子位 | 公众号 QbitAI
Qwen3强势刷新开源模型SOTA,但如何让其在资源受限场景中,既能实现低比特量化,又能保证模型“智商”不掉线?
来自北京航空航天大学、西安电子科技大学和苏黎世联邦理工学院的联合研究团队找到了破局关键。
团队对Qwen3的5种后训练量化技术进行了首次系统性评估,涵盖从1比特到8比特的位宽和多个数据集,此外还与LLaMA3进行了量化比较。
研究发现,Qwen3在中度位宽下保持了竞争性能,但在超低精度下,语言任务性能显著下降,和LLaMA3相比差异则更加明显,亟需进一步解决方案以减轻性能损失。

Qwen3登场:优势与挑战并存
由阿里巴巴集团开发的Qwen系列,是基于Transformer架构、极具竞争力的开源自回归大型语言模型(LLM)。
自发布以来,Qwen展现出了卓越的可扩展性,其70亿参数模型在某些基准测试中甚至可与更大的专有模型,如GPT-3.5相媲美。
最近推出的Qwen3,参数规模从6亿到2350亿不等,通过在多样化、高质量语料库上的精炼预训练进一步提升了性能。
这使得Qwen家族成为最具能力的开源LLM之一,适应多种部署场景。
尽管Qwen3具有诸多优势,但其实际部署因高计算和内存需求而面临挑战。
低比特量化已成为缓解这些问题的重要技术,能够在资源受限设备上实现高效推理。然而,量化往往会导致性能下降。
Qwen3的尖端能力为重新评估量化技术提供了及时机会,以揭示其在尖端模型上的效能与局限性。
在本实证研究中,系统性地评估了Qwen3在后训练量化 (PTQ)方法下的鲁棒性。
团队测试了5种经典PTQ方法,包括Round-To-Nearest (RTN)、GPTQ、AWQ、SmoothQuant和BiLLM,覆盖从1比特到8比特的位宽。
评估涵盖多种语言任务,使用了如Perplexity (WikiText2、C4)、0-shot常识推理 (PIQA、ARC-Easy/Challenge、HellaSwag、Winogrande、BoolQ)和5-shot MMLU等基准测试。
本研究旨在:
-
基准量化引起的性能权衡。 -
识别特定位宽下的最佳方法。 -
突出未解决的挑战,特别是在超低比特场景中。
团队希望研究结果能为未来研究提供指导,推动压缩模型实现更高精度,提升Qwen3及后续LLM的实用性。
深度剖析Qwen3量化的背后
实验设置
团队评估了Qwen3后训练模型(0.6B、1.8B、4B、7B、14B和72B)及其预训练版本(Qwen3-0.6/1.8/4/7/14B-Base)的低比特量化性能,预训练权重来源于官方仓库。
- 量化方法:
为全面评估Qwen3的量化鲁棒性,研究人员选择了5种具有代表性的后训练量化(PTQ)方法,涵盖多种技术路线。
所有实现均遵循其原始开源代码库。实验在1块NVIDIA A800 80GB GPU上进行,以确保评估条件一致。
- 量化协议:
为确保所有量化方法的公平比较,研究人员保持以下三项一致性措施:
-
所有方法使用相同的校准数据(来自C4数据集的128个样本,序列长度为2048)。对于每组量化,通道分组采用128的块大小,遵循LLM量化的既定实践。 -
对于每组量化,通道分组采用128的块大小,遵循LLM量化的既定实践。 -
权重量化统一应用于1到8比特。
这些控制变量使得量化方法的性能可以直接比较,同时最大限度减少干扰因素。
在权重-激活量化方法中,激活值被量化为4或8比特,这是最常用的设置,因为更低位宽通常会导致显著的性能下降。
- 评估协议:
为进行全面的PTQ评估,团队在WikiText2和C4的256个样本子集上测量困惑度(PPL),序列长度为2048。
零样本准确性通过六个公认的推理基准测试进行评估:PIQA、Winogrande、ARC-Easy、ARC-Challenge、HellaSwag和BoolQ。
少样本能力通过5-shot MMLU进一步检验。这一多维评估框架为量化后的Qwen3在不同任务类型和难度水平上的能力提供了严格评估。
PTQ结果
下面详细展示了实验结果(表1,表2,表3,表4),并根据数据提供了直观的视觉图示(图1,图2,图3,图4)。
表1展示了Qwen3-Base模型每通道2到8位的PTQ结果,展现了在Wikitext2和c4上的困惑度、零样本推理任务以及5样本MMLU性能。其中W表示权重量化位宽,A表示激活量化位宽。
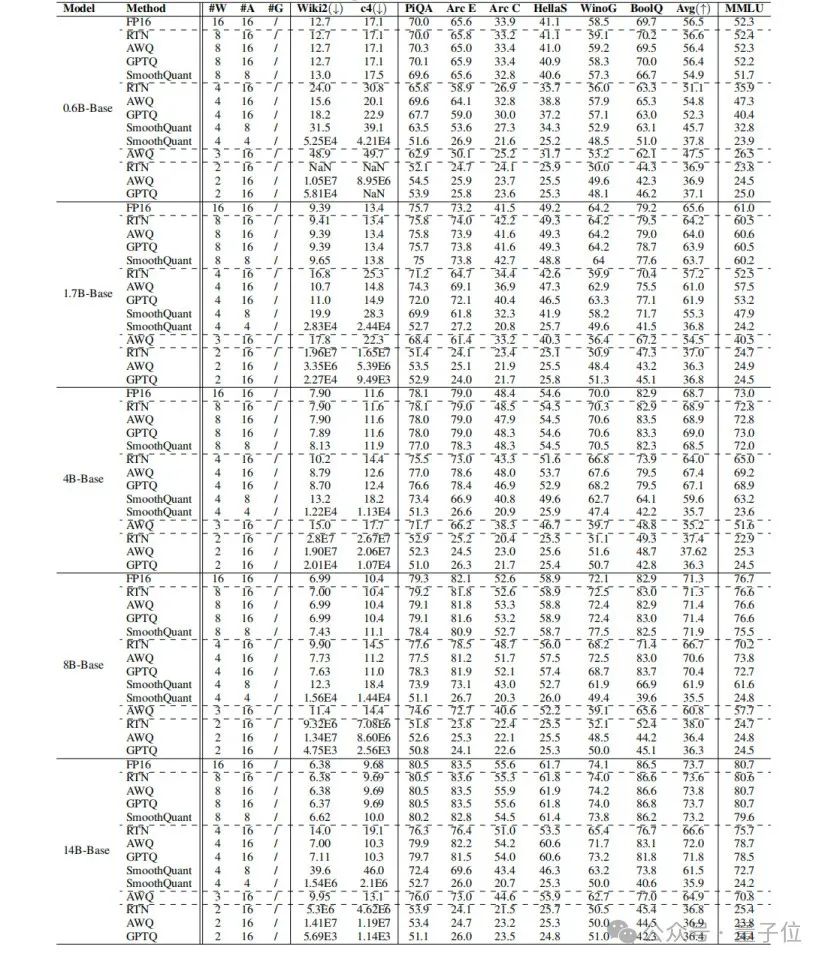
表2是Qwen3模型每通道2到8位的PTQ结果。
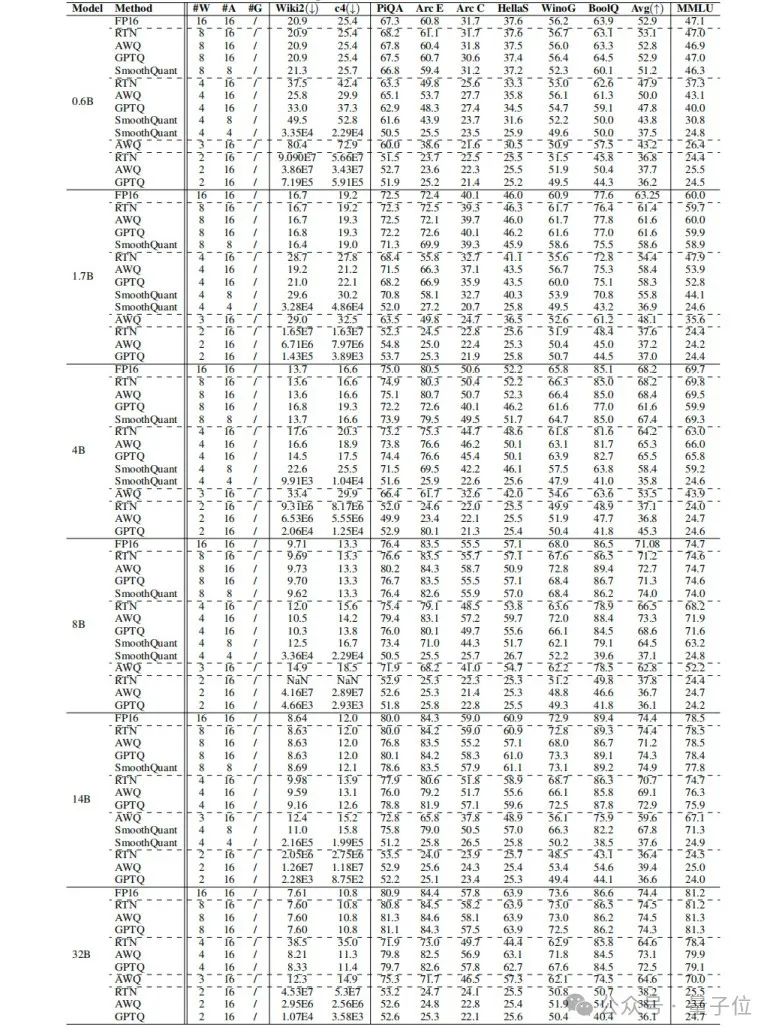
表3是Qwen3-Base模型每组1到8位的PTQ结果,验证了在Wikitext2和c4上的困惑度、零样本推理任务以及5样本的MMLU性能。其中G表示组大小。
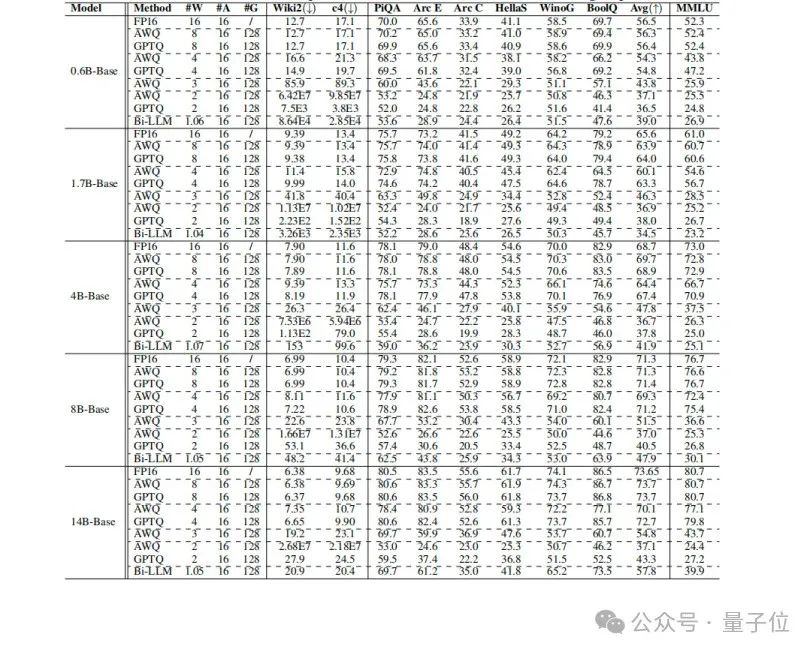
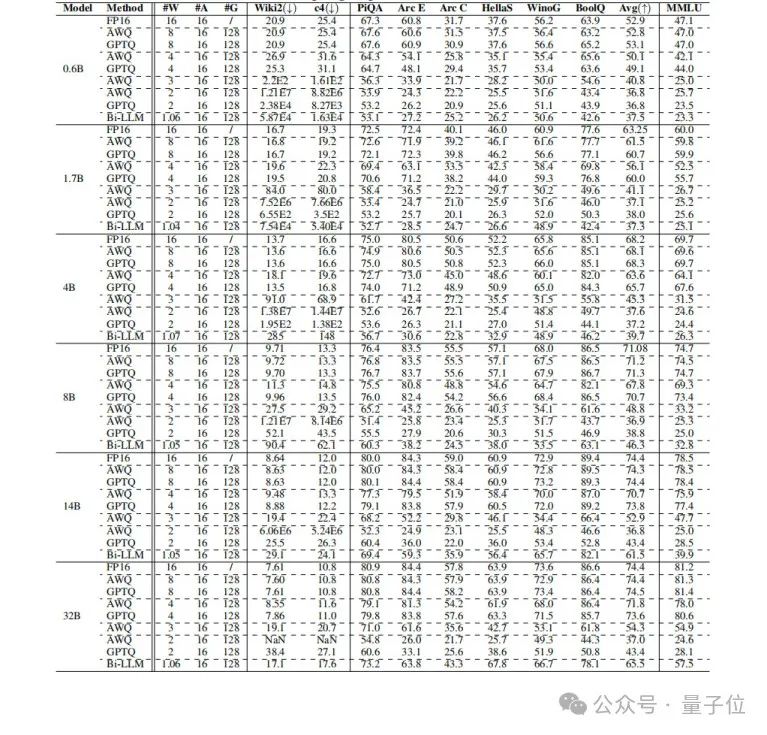
表4是Qwen3模型每组1到8位的PTQ结果。
- 权重量化的影响:
在8比特时,Qwen3始终保持接近无损的性能,表明高比特量化在实际部署中仍具有很大潜力。
然而,当位宽降低到4比特时,所有量化方法均显示出明显的性能下降。例如,Qwen-8B的MMLU分数从74.7降至69.3。
当位宽进一步降至3比特时,尽管AWQ仍保留一定能力,但原始模型的大部分优势已丧失。
在2比特时,仅有像GPTQ这样利用校准补偿的方法能够保持最低限度的性能。
同时,团队观察到二值化方法Bi-LLM表现出相对有前景的结果,在32B模型中甚至超越了3比特的AWQ,凸显了二值化的潜力。
- 激活量化的影响:
在应用经典激活量化方法SmoothQuant时,团队观察到即使在w8a8设置下,与全精度模型相比,性能已有明显下降。
当位宽降至w4a8时,模型性能显著下降,远不如仅权重量化。
这一结果与近期研究发现一致,表明大型模型可能对激活量化特别敏感,可能是由于激活值异常导致的显著性能下降。
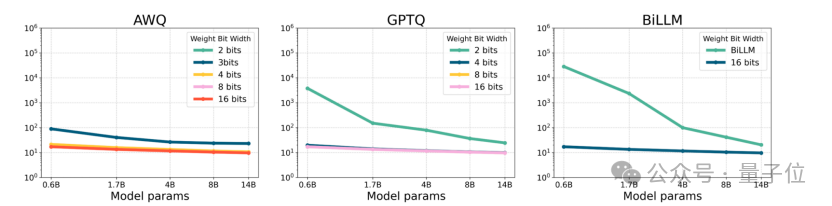
△图1:Qwen3-Base在C4数据集上按照per-group的困惑度
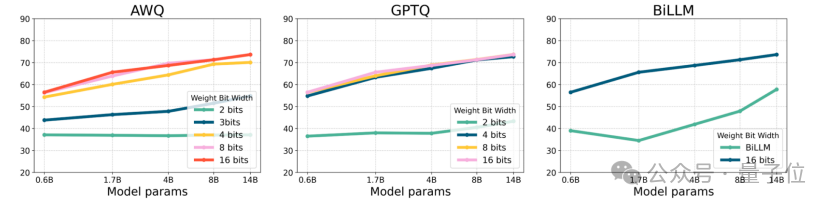
△图2:Qwen3-Base每组量化的0样本常识推理准确率
- 不同参数规模的比较:
团队观察到较大模型在量化下表现出更强的稳定性。
具体来说,Qwen3-14B在4比特GPTQ下的MMLU性能仅下降1%,而Qwen3-0.6B在相同设置下下降约10%,这凸显了较大参数空间缓解量化噪声的能力。
- 与LLaMA3的比较:
团队此前对LLaMA3进行了经典方法的实验。
与LLaMA3的先前结果相比,Qwen3在低比特量化(3比特或更低)下表现出更显著的性能下降。
具体来说,在LLaMA3-8B中,AWQ的w3a16g128量化使C4上的PPL从9.2仅增至11.6,而在Qwen3-8B-Base中,相同AWQ设置使PPL从10.4增至23.8。
这与团队之前的实证观察和假设一致:更彻底的预训练过程可能导致更强的LLM中冗余表示更少,使其对量化更敏感。
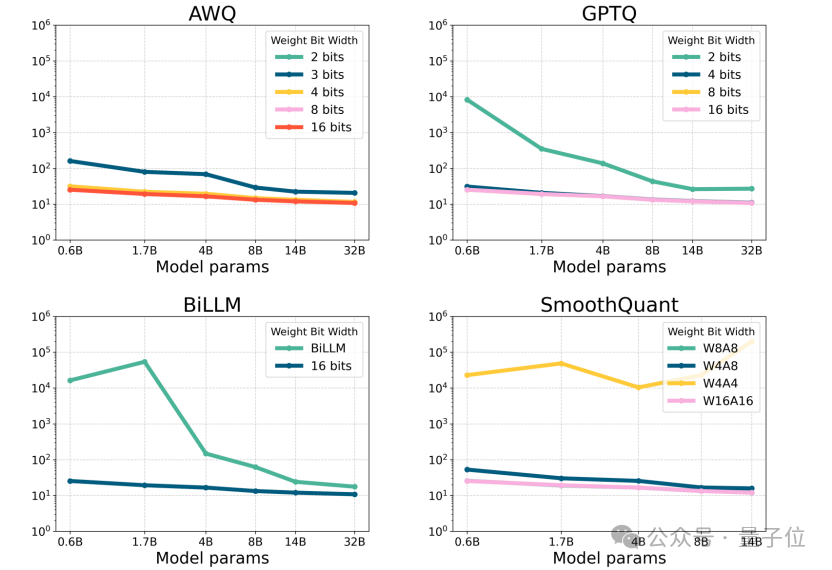
△图3:Qwen3在C4数据集上per-group和per-channel量化方法的困惑度
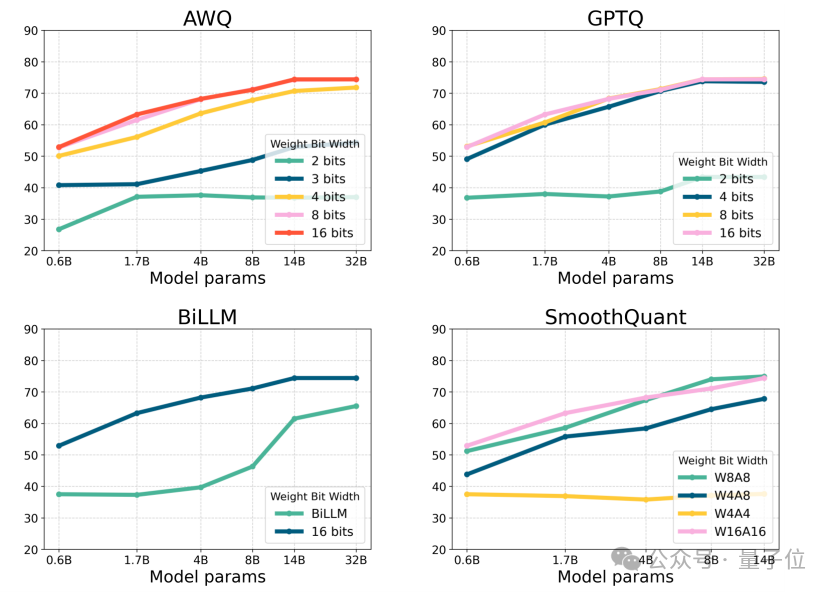
△图4:Qwen3 per-group量化和per-channel量化方法的0样本常识推理准确率
结论与展望
新发布的Qwen3系列已成为最强大的开源大型语言模型(LLM)家族之一,吸引了学术界和工业界的广泛关注。
本研究首次系统性地评估了Qwen3在多种低比特量化方案下的鲁棒性,特别聚焦于后训练量化方法。
通过全面的量化分析,旨在为在资源受限场景下部署Qwen3建立实际界限。
实验结果表明,Qwen3在较高位宽(4比特及以上)下保持了竞争性能,但与前几代模型相比,在量化为3比特或以下时,性能下降更为明显。
这一观察与团队的假设一致,即Qwen3广泛采用的先进预训练技术往往生成参数冗余较少的模型,从而使其对量化引起的信息损失更为敏感,尤其在复杂推理任务和少样本学习场景中,性能下降尤为显著。
这些发现突显了两个关键含义:
-
当前的量化技术需要进一步创新,以更好地保留Qwen3的先进能力; -
对于尖端LLM,模型压缩与性能保留之间的权衡需要仔细重新考虑。
研究团队相信,这一实证分析为LLM量化的未来研究方向提供了宝贵指导,特别是在开发能够在超低位宽下保持高准确性的方法方面。
随着领域的进步,研究团队期待这些见解将有助于像Qwen3这样强大模型的更高效部署,最终在降低计算开销的同时推动大型语言模型的实际应用。
未来该团队计划评估更高级的量化方法,例如基于通道重排序的方法和基于旋转的量化策略,以评估Qwen3在这些技术下的性能,特别是它们对激活量化的影响。
论文链接:https://arxiv.org/pdf/2505.02214
项目链接:https://huggingface.co/collections/Efficient-ML/qwen3-quantization-68164450decb1c868788cb2b
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)