作者|沐风
来源|AI先锋官
既造手机又造车,既布局IoT生活家电又搞机器人的小米,堪称科技公司中的“跨界王”。
日前,小米正式发布并宣布开源其首个“为推理而生”的大模型 Xiaomi MiMo,联动预训练到后训练,全面提升推理能力。
MiMo系列共开源了4个模型,分别为MiMo-7B、MiMo-7B-RL-Zero、MiMo-7B-RL以及一个MiMo-7B监督微调(SFT)模型。
据小米官方介绍,MiMo是来自成立不久的“小米大模型 Core 团队”的初步尝试。
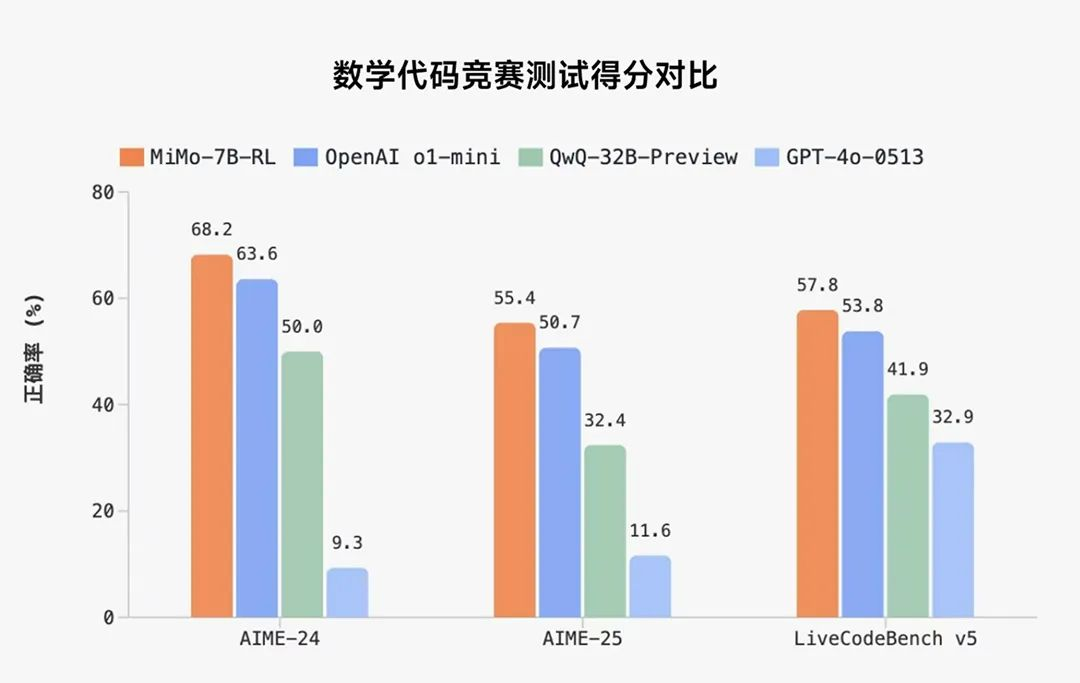
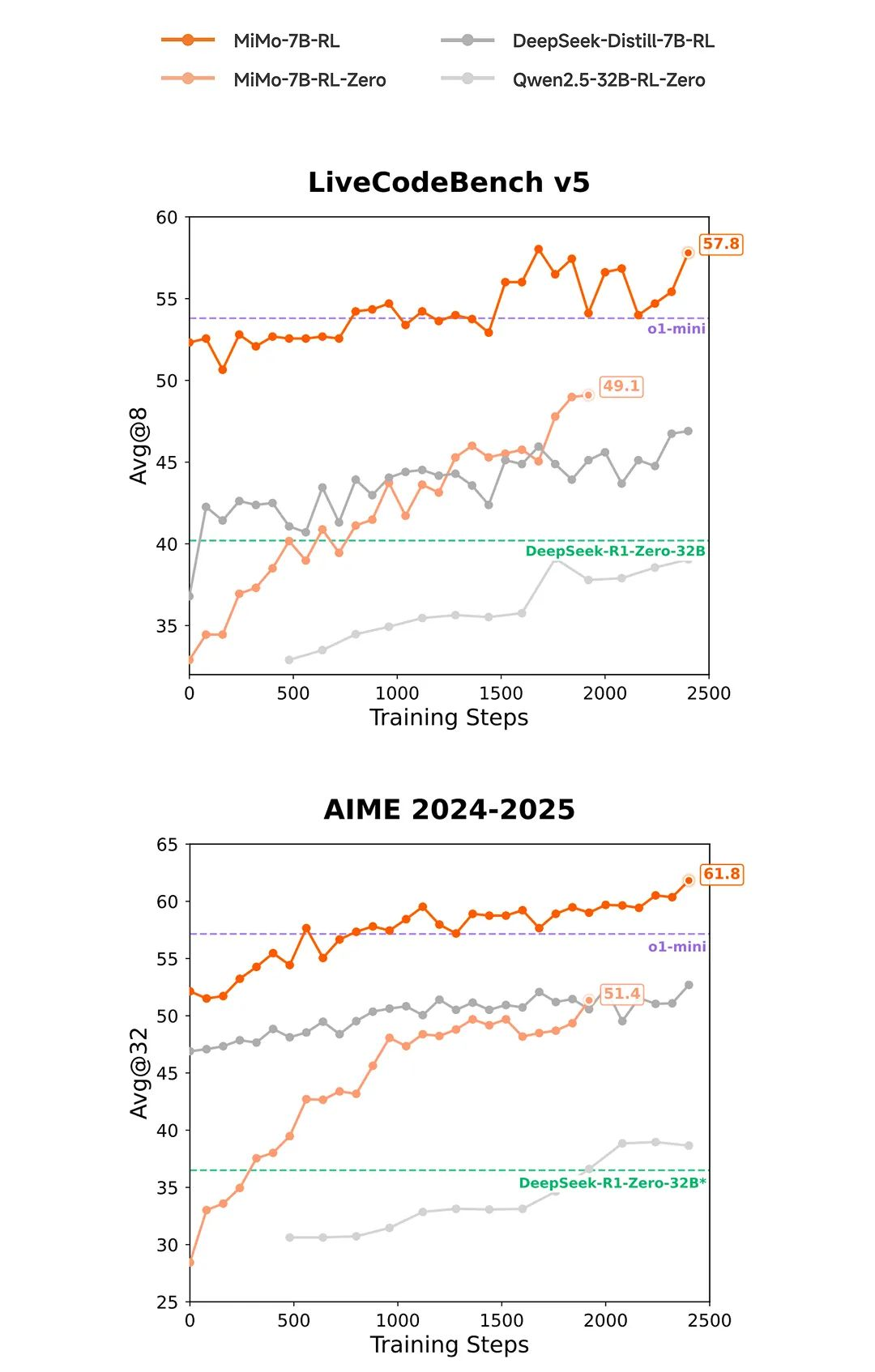
虽然是初步尝试,但MiMo仅以7B(70亿)的参数规模,就在数学推理(AIME 24-25)和代码竞赛(LiveCodeBench v5)公开测评中,超越了OpenAI的闭源推理模型o1-mini,及阿里Qwen更大规模的开源推理模型QwQ-32B-Preview。
小米技术团队表示,MiMo推理能力的核心突破在于,预训练与后训练阶段的协同优化。
据MiMo-7B论文介绍,小米技术团队认为,强化学习训练的推理模型有效性,依赖于基础模型的内在推理潜力。
为了充分释放语言模型的推理潜力,不仅要专注于后训练阶段,还必须致力于为推理量身定制的预训练策略。
在预训练阶段,其模型通过挖掘高质量推理语料并合成约2000亿tokens专项数据。
并且,MiMo采用了三阶段数据混合策略,以增强基础模型的推理潜力,累计训练量达25万亿tokens。
后训练阶段,则引入创新强化学习技术,包括自研的”Test Difficulty Driven Reward”算法和”Easy Data Re-Sampling”策略,有效提升模型在复杂任务中的稳定性。
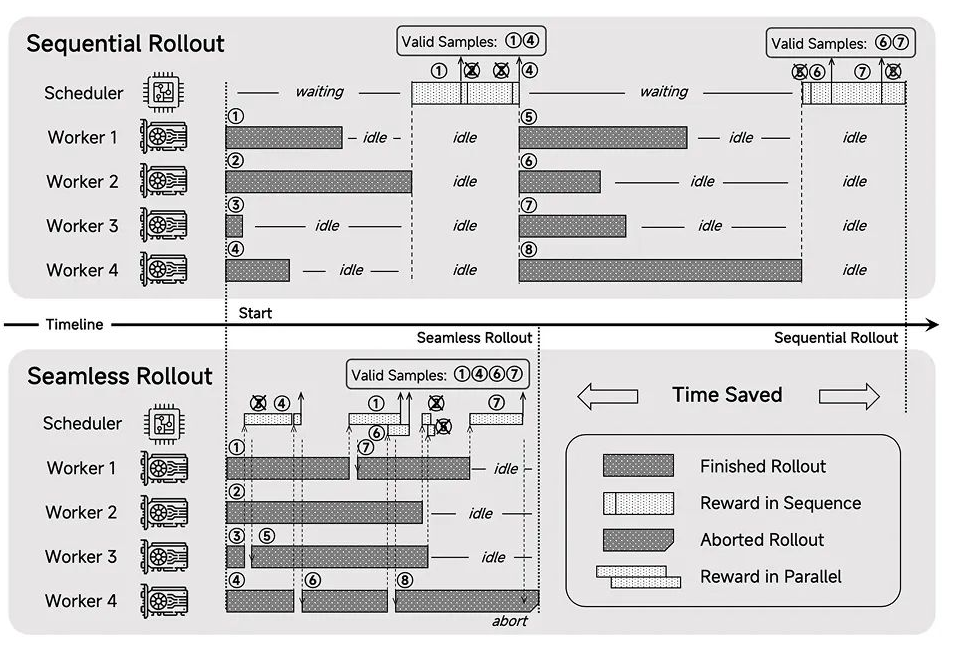
技术团队还设计了”Seamless Rollout”系统,整合了连续采样、异步奖励计算以及提前终止机制,从而将GPU的闲置时间降至最低,使RL(强化学习)训练效率提升2.29倍,验证速度加快1.96倍。
另外,据小米团队称,MiMo-7B在相同RL训练数据下,数学与代码领域的表现,显著优于当前业界广泛使用的DeepSeek-R1-Distill-7B和Qwen2.5-32B模型。
但就目前推出的MiMo-7B来看,仅仅只是超越了 OpenAI的o1-mini,其距离最先进的水平还是有一段路要走。
早在2023年,小米创始人雷军就表示,自2016年组建AI团队以来,到2023年4月第一时间成立专职大模型团队,经过多次扩展,小米AI团队相关人员规模已达3000多人。
去年11月,小米被传出内部成立了AI平台部发力AI大模型,由张铎担任负责人。
张铎曾在2016年至2021年期间在小米负责开源工作的规划与推进,2021年离开小米后曾入职神策数据担任研发负责人和首席架构师,2024年9月再度回归小米。
去年12月,小米又被曝出正着手搭建了自己的GPU万卡集群,将对AI大模型进行大力投入。
值得一提的是,在2024年小米集团营收3659亿元创历史新高,选择当下进军AGI、发力AI大模型可谓“粮草”充足。
随着小米的加入,2025年AI开源大模型下半场的竞争或许将变得更加激烈。
(文:AI先锋官)