
阿联酋大学、纽约大学阿布扎比分校以及巴基斯坦国立科技大学的研究人员,联合推出了一种高效内存重放方法Replay4NCL,以解决嵌入式 AI 系统在动态环境中持续学习的难题。
值得一提的是,该研究成果已经被第62届设计自动化大会(DAC)审核通过,会在2025年6月在旧金山举办的大会上展示。

随着AI技术的快速迭代发展,嵌入式 AI 系统在各种应用场景中扮演着越来越重要的角色,例如,移动机器人、无人驾驶、无人机等。这些系统需要具备持续学习的能力,以适应动态变化的环境,同时避免灾难性遗忘。
但传统的持续学习方法在嵌入式系统中面临着显著的延迟、能量消耗和内存占用问题,而Replay4NCL通过优化记忆重放过程,为嵌入式 AI 系统提供了一种高效的神经形态持续学习解决方案。
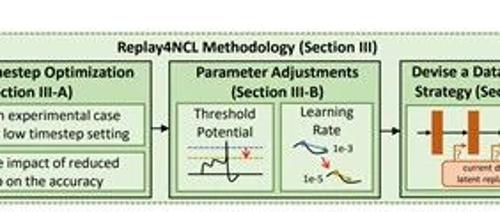
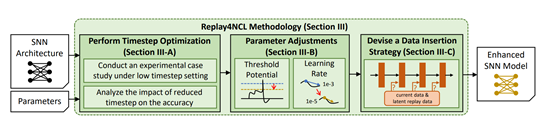
Replay4NCL核心架构介绍
Replay4NCL的第一个核心创新模块是时序优化。在脉冲神经网络中,时序是一个关键参数,决定了神经元在每个时间步内处理信息的频率。
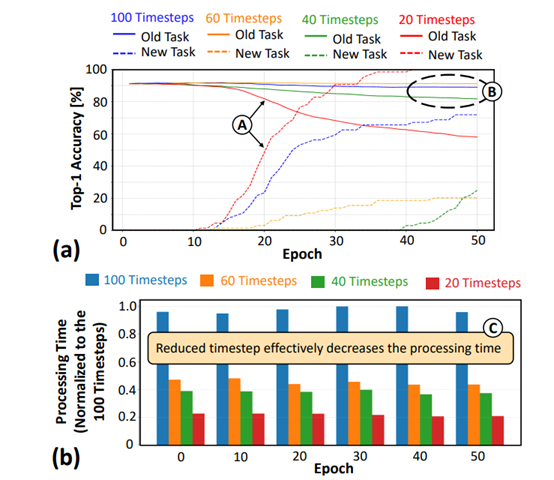
传统的 SNN 模型通常采用较长的时序,以确保网络能够充分处理输入数据并达到较高的精度。然而,长时序也带来了显著的处理延迟,这对于需要快速响应的嵌入式 AI 系统来说是不可接受的。
Replay4NCL通过实验研究了不同时序设置对网络精度和延迟的影响。研究人员发现,将时序从传统的 100 降低到 40,虽然会导致精度略有下降,但仍然能够保持在可接受的范围内,同时显著减少了处理时间。这一发现为优化时序提供了理论依据。此外,
Replay4NCL还引入了一种基于减少时序的数据压缩 – 解压缩机制,进一步减少了潜在数据(旧知识)的内存占用。通过这种机制,潜在数据在存储时被压缩,而在使用时再进行解压缩,从而在不损失信息的前提下,显著减少了潜在数据的存储空间。
时序的减少虽然降低了延迟和内存占用,但也带来了新的挑战。由于时序减少,神经元接收到的脉冲数量减少,这可能导致神经元的膜电位难以达到阈值电位,从而影响网络的性能。为了解决这一难题,Replay4NCL提出了参数调整模块,通过调整神经元的阈值电位和学习率来弥补信息损失。
研究人员降低了阈值电位 Vthr 的值,使得神经元更容易发射脉冲,即使在脉冲数量较少的情况下,也能够保持与原始预训练模型相近的脉冲活动。同时,学习率也被降低,以减缓网络的学习速度。这一调整确保了在训练阶段,网络能够更加谨慎地更新权重,尤其是在脉冲数量较少的情况下,从而提高了网络对旧知识的保持能力和对新知识的学习能力。
Replay4NCL的另一个核心创新是其动态训练策略,可将时序优化、参数调整和潜在重放数据插入策略有机地结合起来,形成了一种高效的训练机制。
在预训练阶段,SNN 模型首先被训练以学习所有预训练任务。在准备网络进行持续学习训练阶段时,模型会生成LR 数据激活,并根据选定的层将网络分割为两部分:冻结层和学习层。冻结层负责将输入脉冲传递到学习层,而学习层则在训练新任务时进行更新。
在持续学习训练阶段,网络会动态调整阈值电位和学习率。通过这种方式,网络能够在处理较少脉冲的情况下,仍然保持高效的权重更新和学习能力。
实验数据
为了测试Replay4NCL 的性能,研究人员在Spiking Heidelberg Digits、Class-Incremental Learning上进行了综合评估,来检测其精度、处理延迟和内存占用等关键参数。
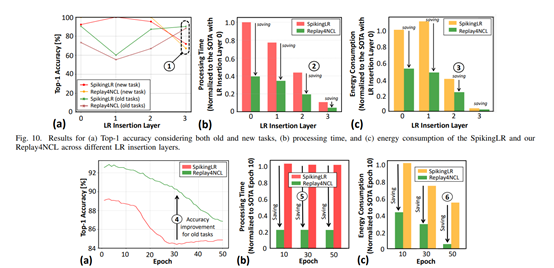
实验结果显示,Replay4NCL在保持旧知识方面表现出色,其 Top-1 精度达到了 90.43%,相比现有的最先进方法SpikingLR提高了 4.21 个百分点。同时,在学习新任务时,Replay4NCL 方法也展现出了良好的性能,其精度与 SpikingLR 方法相当。
在处理延迟方面,Replay4NCL 方法取得了显著的改进。与时序为100的 SpikingLR 方法相比,Replay4NCL方法通过采用 40 时序的设置,将处理延迟降低了 4.88 倍。这一改进使得嵌入式 AI 系统能够更快地响应输入信号,提高了系统的实时性。
在潜在数据内存占用方面,Replay4NCL 方法也取得了显著的节省。由于采用了减少时序的数据压缩 – 解压缩机制,Replay4NCL 方法将潜在数据的内存占用减少了20%。这一节省对于资源受限的嵌入式 AI 系统来说至关重要,因为它可以显著减少系统的存储需求,从而降低硬件成本和功耗。
在能量消耗方面,Replay4NCL 方法同样表现出色。实验结果表明,与 SpikingLR 方法相比,Replay4NCL 方法将能量消耗降低了 36.43%。这一节能效果主要得益于减少的时序设置,因为它减少了脉冲的生成和处理数量,从而降低了系统的能量消耗。
(文:AIGC开放社区)