
▍新型低型软体旋转气动执行器设计与分析
成均馆大学的研究团队在《A new design and analysis of low-profile soft rotary pneumatic actuator for enhanced rotation and torque》一文中提出了一种新型低型软体旋转气动执行器。随着模仿人类肌肉动作需求的增加,软体驱动器在抓取、可穿戴设备和生物医用装置等领域获得了广泛关注。

研究背景与挑战
传统软气动驱动器(SPA)利用弹性材料在施加压力后产生变形,展现出高柔性、低重量和低能耗的优点。然而,旋转型软体驱动器的发展相对滞后,现有设计多采用螺旋纤维在圆柱形弹性体上排列,使旋转量随软体长度增加而提高,但在空间有限场景中存在局限性。同时,现有建模方法多依赖对变形后固定形状的假设,无法准确描述实际变形过程。
创新设计与方法
研究团队提出的新型低型软体旋转气动执行器具有三大创新点:
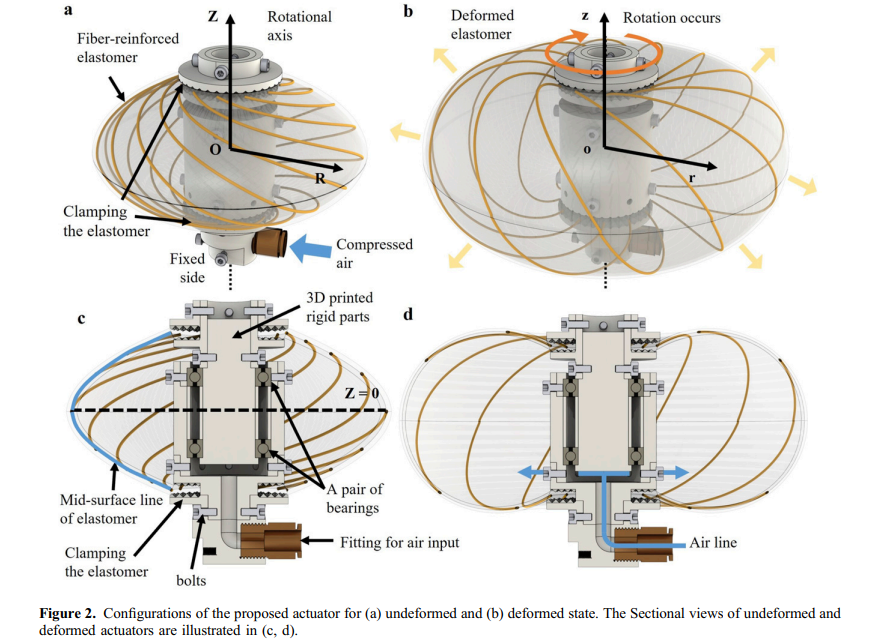
实验结果与分析
研究通过有限元模拟和实物实验进行了详尽验证:
- 有限元分析
显示,不同数量纤维(6、9、18根)和不同缠绕角(180°和240°)的模型在低压时差异较小,高压时出现明显偏差,但总体误差控制在20%以内。 - 实验验证
表明,尽管在高压区域存在一定滞后现象,但理论模型与实验数据总体趋势一致,理论模型与仿真数据之间平均绝对误差约1°,证明了模型的预测能力。
该研究为软体机器人领域提供了一种紧凑、高效的旋转驱动解决方案,未来可进一步改进材料滞后性建模、纤维滑移效应以及高动态情况下的粘弹性和惯性效应建模。

▍大规模室内运动捕捉数据集:THÖR-MAGNI
来自厄勒布鲁大学等机构的研究者在《THÖR-MAGNI: A large-scale indoor motion capture recording of human movement and robot interaction》中发布了一个创新性数据集,旨在解决社交导航与人机交互研究中的数据瓶颈。
研究背景与意义
现有数据集存在两大局限:一是上下文信息不足,缺乏环境语义和个体行为线索;二是模态单一,忽略眼动、力觉等多模态数据对意图预测的重要性。经典数据集如ETH/UCY仅记录室外行人轨迹,而工业场景数据集未涵盖动态机器人交互。

数据集特点与创新
THÖR-MAGNI数据集具有四大核心优势:

数据分析与应用价值
THÖR-MAGNI在多项数据指标上超越现有数据集:
- 追踪质量
:平均追踪时长达41.3秒,远超ETH/UCY(15-25秒),支持长期行为预测。 - 运动复杂度
:轨迹非线性系数(0.75-0.78)显著低于ETH/UCY(0.85-0.92),体现更复杂的避障与交互行为。 - 多模态验证
:实验表明,人类在接近机器人时视线集中在其运动方向,为意图预测提供关键线索;多模态策略在动态避障任务中比单一视觉模型成功率提升23%。
该数据集为社交导航与人机交互研究提供了标杆基准,支持长时轨迹预测、眼动–行为关联分析和机器人运动规划等任务,标志着人机交互研究从“单模态实验“迈向“多模态协同“的新阶段。
▍功能操作基准:FMB
加州大学伯克利分校的研究团队在《FMB: A functional manipulation benchmark for generalizable robotic learning》中提出了一个综合性的机器人操作基准测试平台。

研究背景与挑战
机器人操作研究面临两大挑战:一是物理复杂性,包括接触动力学和技能组合的复杂性;二是泛化能力不足,难以适应新物体或场景。现有研究要么聚焦于简单任务的广泛泛化,要么专注于复杂任务的狭窄优化,缺乏兼顾物理复杂性和泛化能力的统一基准。
基准设计与特点
FMB基准通过四大模块设计,成为机器人学习研究的标准化工具包:
1、多样化可复现物体:包含66种不同形状、尺寸和颜色的3D打印物体,支持单物体操作和多物体复杂装配,并提供CAD文件确保全球研究者可低成本复现。
2、大规模多模态数据集:提供22,500条人类演示轨迹,涵盖RGB/深度图像、机器人运动学数据、末端力/力矩信息,按技能和任务模块化分割。
3、模块化模仿学习框架:基于ResNet和Transformer的基线策略,支持分阶段技能训练或端到端长序列任务,灵活组合输入模态。
4、标准化评估协议:严格测试流程包括训练集外物体和随机初始位姿,量化策略的泛化性与鲁棒性。
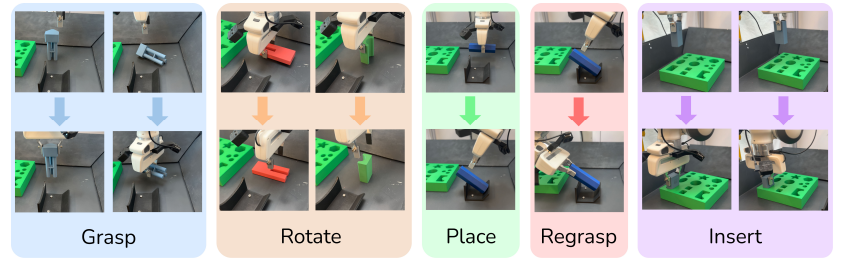
实验结果与验证
研究团队通过三类任务验证了FMB的有效性:
1、抓取任务:数据量和深度信息显著影响成功率(100%数据:27/50;RGB+深度比纯RGB提升约10%),而训练集外物体测试验证了泛化能力。
2、插入任务:加入力觉信息后,插入成功率从2/25提升至11/25,不同形状复杂度展现任务难度梯度(三叉形:4/25;矩形:19/25)。
3、多阶段任务:端到端策略因误差累积成功率接近0,而基于人类预设序列的分层策略显著提升性能(单物体:19/30;多物体:7/10)。
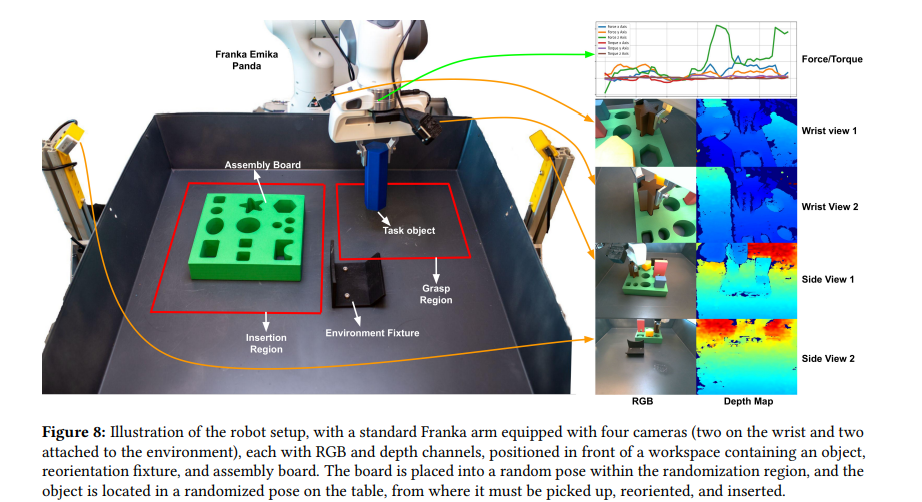
FMB通过标准化设计为机器人学习研究提供了可扩展的测试平台,其数据集、3D模型、代码和预训练模型已完全开源,为推动机器人操作技术发展提供了重要基础设施。
▍双臂机器人操作可变形线性物体
清华大学与加州大学伯克利分校的联合研究《Generalizable whole-body global manipulation of deformable linear objects by dual-arm robot in 3-D constrained environments》解决了双臂机器人在受限三维空间操作可变形线性物体(DLO)的复杂问题。
研究背景与挑战
在工业装配、医疗手术等场景中,机器人操作DLO(如电缆、绳索)面临三大挑战:
1、高维与多约束性:DLO形变自由度、双臂机器人高自由度、复杂环境中的碰撞避免导致规划和控制复杂度极高。
2、模型不确定性:DLO的非线性力学特性使精确建模困难,传统基于模型的开环规划易失效。
3、泛化能力不足:现有方法多针对特定任务或简化环境,难以适应不同DLO类型和复杂场景。

创新框架与方法
研究提出一种全局规划与局部控制互补的框架,包含三大创新:
1、全局规划器:基于离散弹性杆模型(DER)快速生成可行路径,采用改进双向RRT算法和投影方法约束节点生成,引入任务空间引导策略加速搜索,提出简化DER参数识别方法适应不同DLO。
2、局部控制器:设计模型预测控制器结合自适应DLO雅可比模型实时补偿规划误差,引入硬约束(碰撞避免、拉伸限制),通过闭环反馈实现高精度跟踪。
3、系统整合:首次实现双臂机器人在真实三维受限环境中对多种DLO的全身无碰撞操作,任务复杂度远超现有方法。
实验验证与结果
研究通过仿真和真实实验全面验证了方法的有效性:
- 仿真验证
:在4类复杂任务中,规划成功率100%,平均规划时间1-10秒,平均规划时间1-10秒(最复杂任务为10秒)。闭环控制下,400次测试全部成功,最终形变误差<0.5 mm,碰撞时间趋近于0;开环控制因模型误差碰撞率显著上升(如任务4碰撞时间从0.03秒增至1.71秒)。 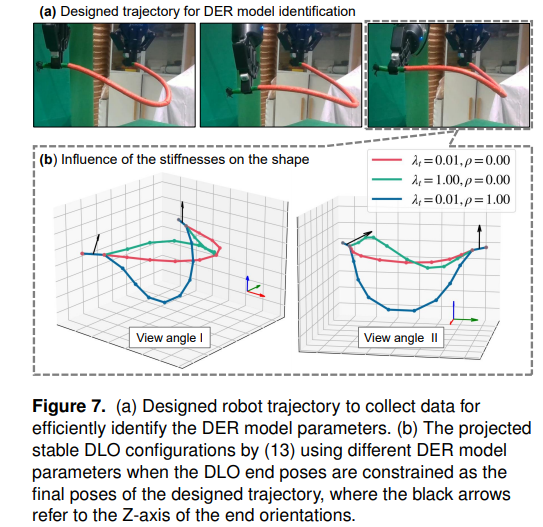
- 真实实验
:使用5种不同材质DLO(TPU弹性体、尼龙绳等)完成3类复杂任务(避障、旋转、穿窄缝),135次测试 全部成功,平均执行时间<60秒;闭环控制显著降低碰撞风险(仅1次轻微碰撞),开环控制成功率降至94%。 - 对比分析
-
模型优势:相比Bretl的六维流形模型,DER模型考虑重力效应,规划路径更短,执行时间减少50%。 -
框架优势:相比McConachie的弹性带方法,本文在碰撞避免和路径质量上表现更优,复杂任务规划成功率提升至100%。
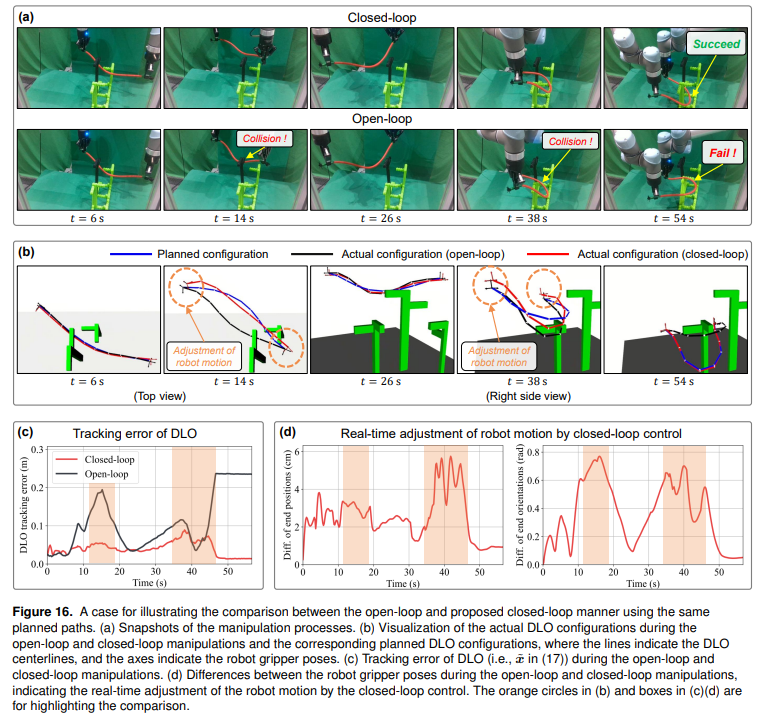
该研究为工业与医疗场景提供了通用解决方案,未来可进一步研究全局路径优化、加速DER投影计算、融合环境接触的DLO操作以及结合实时动态模型与深度学习提升预测精度。
▍大规模异构多机器人系统的实时规划
中国科学技术大学研究团队在《Real-time reactive task allocation and planning of large heterogeneous multi-robot systems with temporal logic specifications》中提出了一种创新的大规模异构多机器人系统实时规划方法。
研究背景与挑战
传统多机器人系统的任务分配与规划(TAP)方法面临三大问题:
1、计算成本高:随机器人数量和任务复杂度增加,状态空间呈指数级增长(“维度灾难“)。
2、实时性不足:难以应对动态环境中的突发状况,如火灾救援中的新火点或幸存者检测。
3、异构性支持有限:现有方法难以高效协调具有不同能力的异构机器人协作完成复杂任务。
创新方法与贡献
研究提出基于规划决策树(PDT)的实时反应式任务分配与规划框架,核心创新包括:
1、规划决策树结构:将任务进度和系统状态编码为树形结构,避免构建复杂的产品自动机,显著降低状态空间;支持增量式任务分配,任务分配复杂度仅与机器人数量和类型呈线性关系(O(n))。
2、双阶段搜索算法:包括离线规划(PDTS)生成满足全局时序逻辑(LTL)任务的初始计划,以及在线交互式规划(IPDTS)动态调整计划响应环境变化。
3、理论保证:提供可行性(生成的计划可执行且满足任务需求)和完备性(若存在可行解,算法保证找到)的数学证明。
4、超大规模适用性:可处理超过200个任务状态、100种机器人类型及10^4规模的机器人集群。
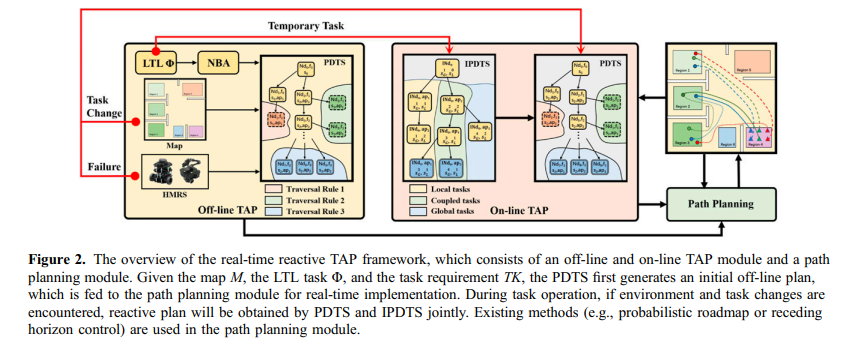
实验结果与应用
研究通过多项实验验证了方法的性能:
- 计算效率
:PDTS在200个任务状态和10^4机器人规模下规划时间仅16.4秒,比传统MILP方法快10^3倍;IPDTS在全局与临时任务耦合时平均规划时间仅0.0134秒。 - 场景测试
:在火灾救援(200个异构机器人实时协调)、医院清洁(4台异构机器人动态协作)和塔防游戏(防御与临时任务响应)等场景均表现出色。 - 鲁棒性
:机器人故障或环境突变时,系统可在10毫秒内重新规划;任务需求动态调整时,系统能无缝切换。 
该框架在灾害救援、工业物流等领域具有广泛应用潜力,未来研究方向包括考虑通信约束下的规划、引入时间敏感任务约束以及结合强化学习优化局部任务分配策略。
▍人机交互中的机器人学习通信
弗吉尼亚理工学院和普渡大学的研究者在《A survey of communicating robot learning during human-robot interaction》中系统性地综述了学习与通信闭环研究的进展。

研究背景与意义
随着机器人智能化与自主性提升,人类与机器人之间的理解鸿沟依然存在。传统研究通常将机器人学习算法与通信接口设计割裂开来:
-
学习算法(如模仿学习、强化学习)常被视为“黑箱“,人类难以实时理解机器人的学习进展与意图。 -
通信接口(如视觉、触觉、听觉)虽能传递信息,但往往未针对“学习状态“优化,缺乏直观性与多模态协同。
该研究首次系统性地探索了如何通过双向信息流提升人机协作效能。
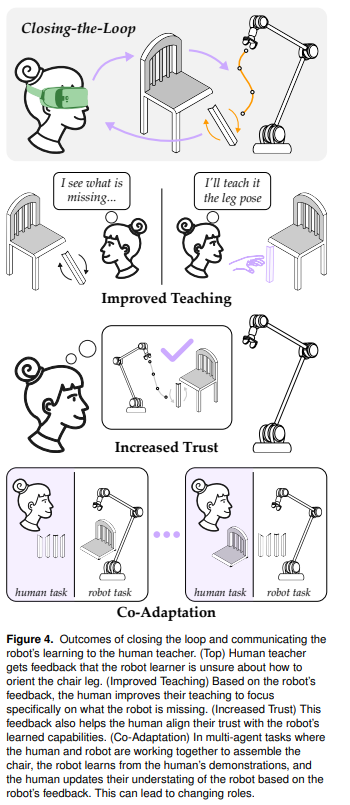
闭环通信框架与趋势
研究提出了一个完整的闭环学习与通信框架,包括:
通信方式分类:
隐式:通过人类参与学习过程间接传递学习状态(如机器人行为变化)。
显式:通过预处理(如行为树、层次化策略)或后处理(如关键状态可视化、自然语言解释)主动生成可解释信号。
研究趋势识别:
从单一视觉反馈转向沉浸式多模态接口(如AR投影结合触觉提示)。
从静态学习模型转向动态人机协同适应(co-adaptation)。
开放问题提出:
如何设计可解释且兼容多模态接口的学习表示?
如何开发标准化通信接口以支持复杂学习状态(如不确定性、决策逻辑)的传递?
如何实时测量人类对机器人学习的理解并优化反馈策略?
实验验证与未来方向
研究通过物理示教机械臂完成椅子组装任务的用户实验,对比了三种通信方式:
- 实验结果
:显式AR+触觉方式在正确预测率(100%)、任务误差(5.0cm)和用户信任度方面均优于仅GUI和隐式方式。
该研究系统性地论证了“学习与通信闭环“对人机协作的三大提升:
1、教学效率:显式反馈帮助人类聚焦机器人薄弱环节,减少无效示教。
2、信任建立:透明化学习状态使人类更准确评估机器人能力,增强协作信心。
3、协同适应:动态反馈促进人机角色调整(如机器人学习后接管重复任务)。

未来研究方向包括开发兼顾学习效率与可解释性的表示方法、设计标准化多模态接口协议、引入神经信号实时量化人类认知负荷与理解深度,推动机器人从“工具“向“伙伴“演进。
▍强化学习在双足机器人控制中的应用
加州大学伯克利分校等机构的研究团队在《Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control》中展示了强化学习在复杂双足机器人运动控制中的突破性应用。

研究背景与挑战
在复杂、非结构化的人类环境中实现稳定且多样化的双足机器人运动控制长期是机器人学的核心难题。传统的模型驱动控制方法在特定任务中表现良好,但面临三大挑战:
1、系统复杂性:高维、非线性、欠驱动系统难以精确建模。
2、动力学不连续:接触模式变化带来的动力学跳变难以处理。
3、多样化动作:非周期动作(如跳跃)对有限时间稳定性的需求难以满足。
创新方法与贡献
研究提出了五大创新点:
1、通用控制框架:统一的强化学习框架可训练涵盖周期性(走、跑)、非周期性(跳跃)、静止(站立)等多种动态技能的控制策略,实现从模拟到实机的零样本迁移。
2、双历史控制策略结构:非递归控制器结构融合短期I/O历史(4步,用于高频反馈控制)和长期I/O历史(2秒,66步,用于系统动态识别与状态估计),通过深度网络结合1D卷积与MLP实现。
3、适应性研究:实证展示RL策略可处理时间不变的系统参数变化和时间变异干扰,在稳定站立、跳跃着陆等场景展现适应能力。
4、鲁棒性提升机制:使用任务随机化(Task Randomization)训练策略,超越常规的动力学随机化(Dynamics Randomization),增强策略对多任务泛化能力和扰动合规性。

5、广泛实机验证:在Cassie机器人上展示了稳健站立、多速度行走、快速奔跑(400米冲刺)、多样跳跃任务(远跳、高跳、方向跳)及未训练地形适应能力,实验持续一年,验证了策略的一致性和实用性。
实验结果与对比
研究团队通过全面实验验证了方法的优越性:
- 行走能力
:同时实现多速度、多高度行走和地形适应,而绝大多数基线方法无法同时实现。 - 奔跑表现
:支持转向并完成400米冲刺,多数基线方法无法完成此任务。 - 跳跃性能
:实现0.47米脚尖离地高度和0.58秒滞空时间,远超其他方法(最大0.42米)。 - 迁移能力
:纯模拟训练可直接无调参部署到实机,而多数基线方法需微调或失败。 - 鲁棒性
:展示了对非预设扰动的恢复能力,多数基线方法未展示此能力。
该研究展示了强化学习在复杂双足机器人运动控制中的通用性与实用性,标志着多技能、动态、稳健的仿人机器人控制向实用化迈出重要一步,为未来更复杂系统的强化学习应用提供了指导路径。
▍结语
本文综述的七篇《International Journal of Robotics Research》近期精选论文,展示了机器人学研究的多个前沿方向。从软体驱动器的精确建模到大规模多机器人系统的实时规划,从功能操作基准到双足机器人的强化学习控制,这些研究不仅推动了各细分领域的技术进步,更共同指向了机器人技术发展的未来趋势:更灵活、更智能、更可靠的机器人系统将逐步融入人类生活和工作环境。
通过多模态感知、闭环控制、学习与通信融合以及强化学习等先进技术的应用,机器人正从简单重复的工业应用向复杂、动态、非结构化环境中的智能助手转变。这些研究成果不仅具有学术价值,更为解决实际问题提供了可行方案,推动了机器人技术向更广泛的应用领域扩展。
如果您对这些研究感兴趣,欢迎深入阅读原论文(下方为相关信息),探索机器人技术的更多可能!
[1] Lee, Young Min, et al. “A new design and analysis of low-profile soft rotary pneumatic actuator for enhanced rotation and torque.” The International Journal of Robotics Research (2024): 02783649241273662.
[2] Schreiter, Tim, et al. “THÖR-MAGNI: A large-scale indoor motion capture recording of human movement and robot interaction.” The International Journal of Robotics Research (2024): 02783649241274794.
[3] Luo, Jianlan, et al. “Fmb: a functional manipulation benchmark for generalizable robotic learning.” The International Journal of Robotics Research (2023): 02783649241276017.
[4] Yu, Mingrui, et al. “Generalizable whole-body global manipulation of deformable linear objects by dual-arm robot in 3-d constrained environments.” The International Journal of Robotics Research (2023): 02783649241276886.
[5] Chen, Ziyang, and Zhen Kan. “Real-time reactive task allocation and planning of large heterogeneous multi-robot systems with temporal logic specifications.” The International Journal of Robotics Research (2024): 02783649241278372.
[6] Habibian, Soheil, et al. “A survey of communicating robot learning during human-robot interaction.” The International Journal of Robotics Research (2024): 02783649241281369.
[7] Li, Zhongyu, et al. “Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control.” The International Journal of Robotics Research (2024): 02783649241285161.
(文:机器人大讲堂)