


新智元报道
新智元报道
【新智元导读】AI也会偷偷努力了?Letta和UC伯克利的研究者提出「睡眠时计算」技术,能让LLM在空闲时间提前思考,大幅提升推理效率。
AI「睡觉」时也能思考了?
Letta和UC伯克利研究者提出了「睡眠时计算」(Sleep-time Compute)技术,旨在提高LLM推理效率,让模型在空闲时间思考。

过去一年,推理模型可太火了。回答问题之前,它会先自己琢磨琢磨。
然而,测试时扩展计算存在明显的弊端,会导致高延迟,推理成本也大幅增加。
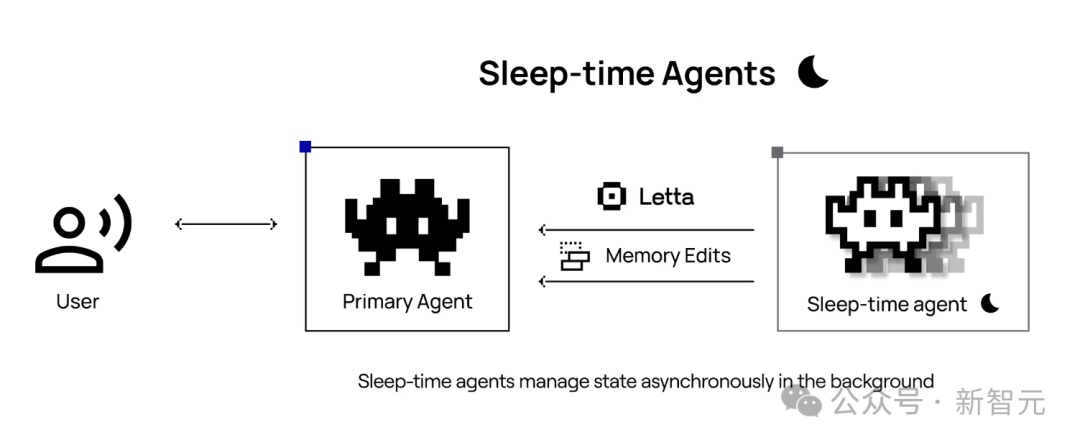
睡眠时计算让模型在空闲时也「动动脑筋」。

简单来讲,模型在没有接收用户查询的空闲时间,提前分析和推理上下文信息。
通过预测用户可能提出的问题,预先算出有用结果,这样用户提问时,模型就能更快、更高效地给出答案。
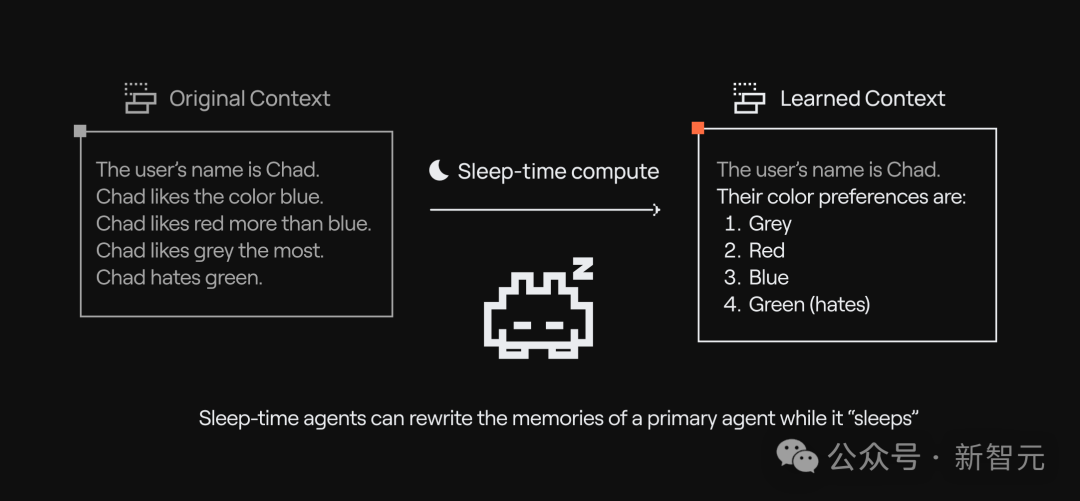
这项技术在保持准确性的同时,降低了推理成本,给AI系统提供了全新的方向。

论文链接:https://arxiv.org/abs/2504.13171
研究发现:
-
睡眠时计算能将达到相同准确率所需的测试时计算量减少约5倍。
-
通过扩展睡眠时计算,模型性能可提升13%。在Stateful AIME任务中,提升幅度高达18%。
-
通过分摊睡眠时计算的成本,可以将每个查询的平均成本降低2.5倍。
-
睡眠时计算在查询从上下文可预测的场景中效果更好。

在标准的测试时计算中,用户输入提示(包含上下文c和查询q),模型进行推理并输出答案a,可表示为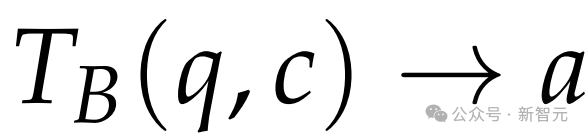 。
。
但在实际中,很多时候在q到来之前就已经有了c,此时模型通常处于空闲状态。
睡眠时计算是利用这段空闲时间,让模型仅基于上下文c进行推理,生成一个新的、更有利于回答查询的上下文c’,这个过程表示为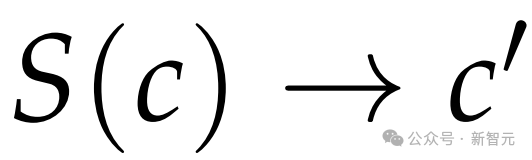 。
。
在测试时,用c’代替c,模型通过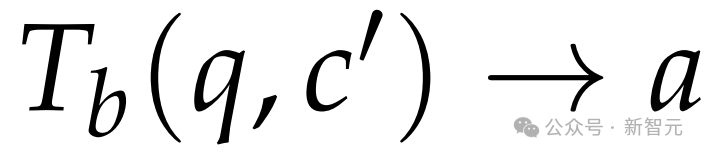 给出答案。
给出答案。
由于提前做了很多准备工作,此时所需的测试时预算b会远小于原来的B,大大减少了计算量。
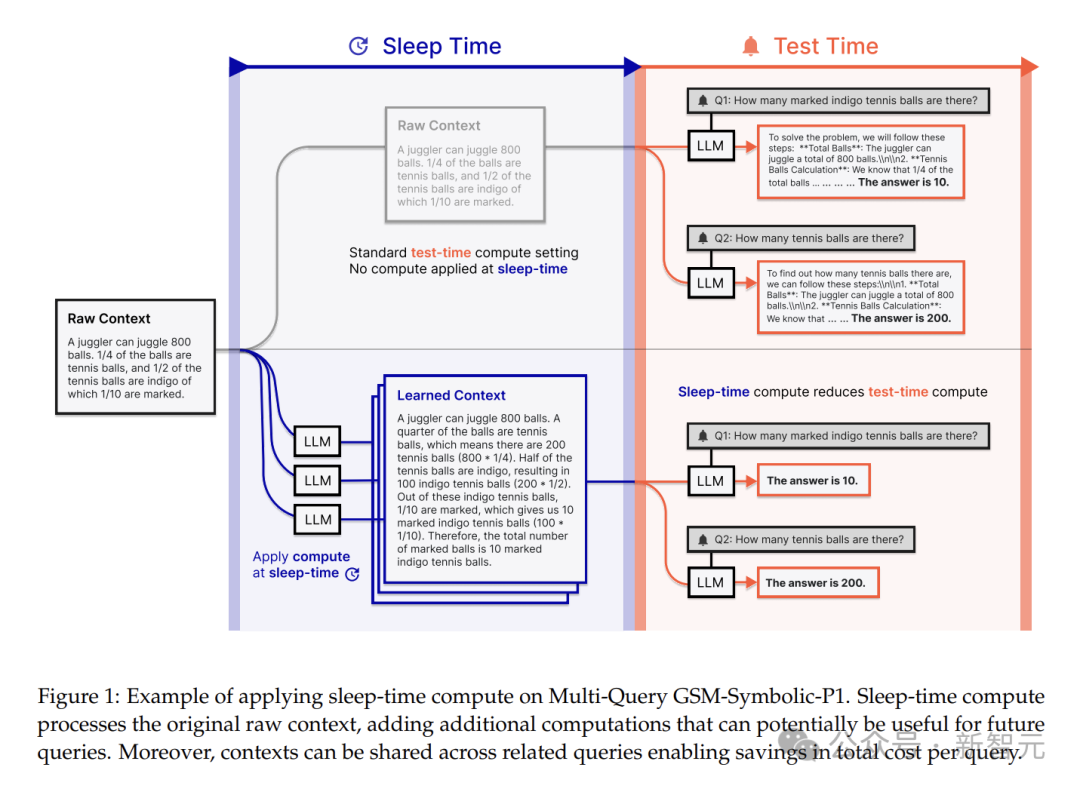
打个比方,你是一个图书管理员(模型),有人来问图书馆的藏书(上下文)。
以往,有人问了,才去图书馆找答案,这样效率很低。而现在,你可以在空闲时,先整理分类书籍,预测读者可能会问的问题,并做好相应的笔记(预计算)。
这样读者提问时,就能根据笔记和整理好的书籍迅速回答。
为验证睡眠时计算的有效性,研究人员进行了一系列实验。
Stateful GSM-Symbolic是从GSM-Symbolic的P1和P2拆分而来,增加了问题的难度。
Stateful AIME则从2024年和2025年美国数学邀请赛题目中选了60个问题,同样拆分成上下文和问题。
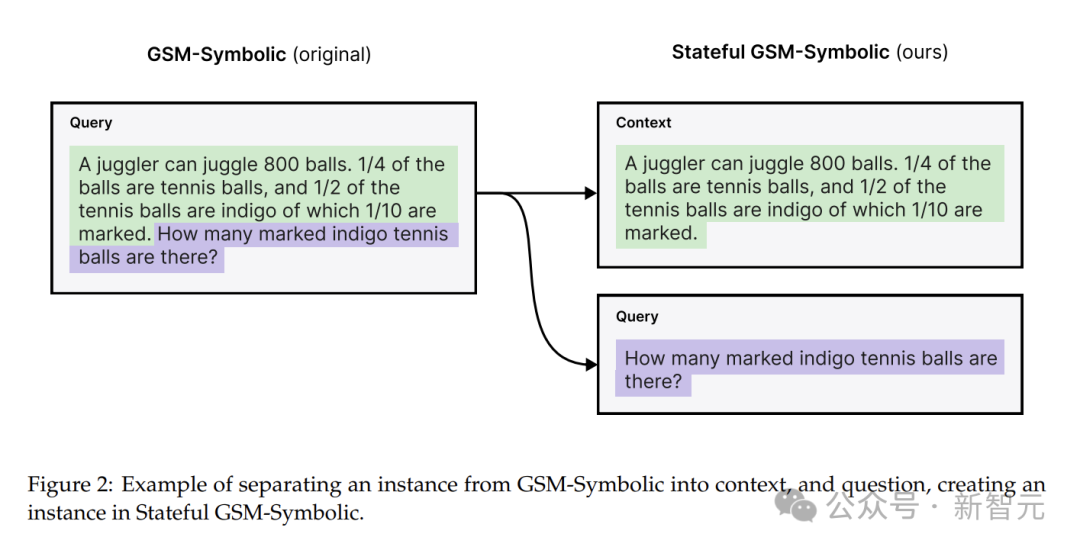
Multi-QueryGSM-Symbolic数据集是为了研究共享上下文的影响,每个上下文包含多个查询。
在GSM-Symbolic数据集上,用GPT-4o-mini和GPT-4o进行实验。在AIME数据集上,使用OpenAI的o1、o3-mini、Anthropic的Claude Sonnet 3.7 Extended Thinking以及Deepseek-R1等模型。
基线采用标准测试时计算,即测试时同时把上下文c和查询q提供给模型。

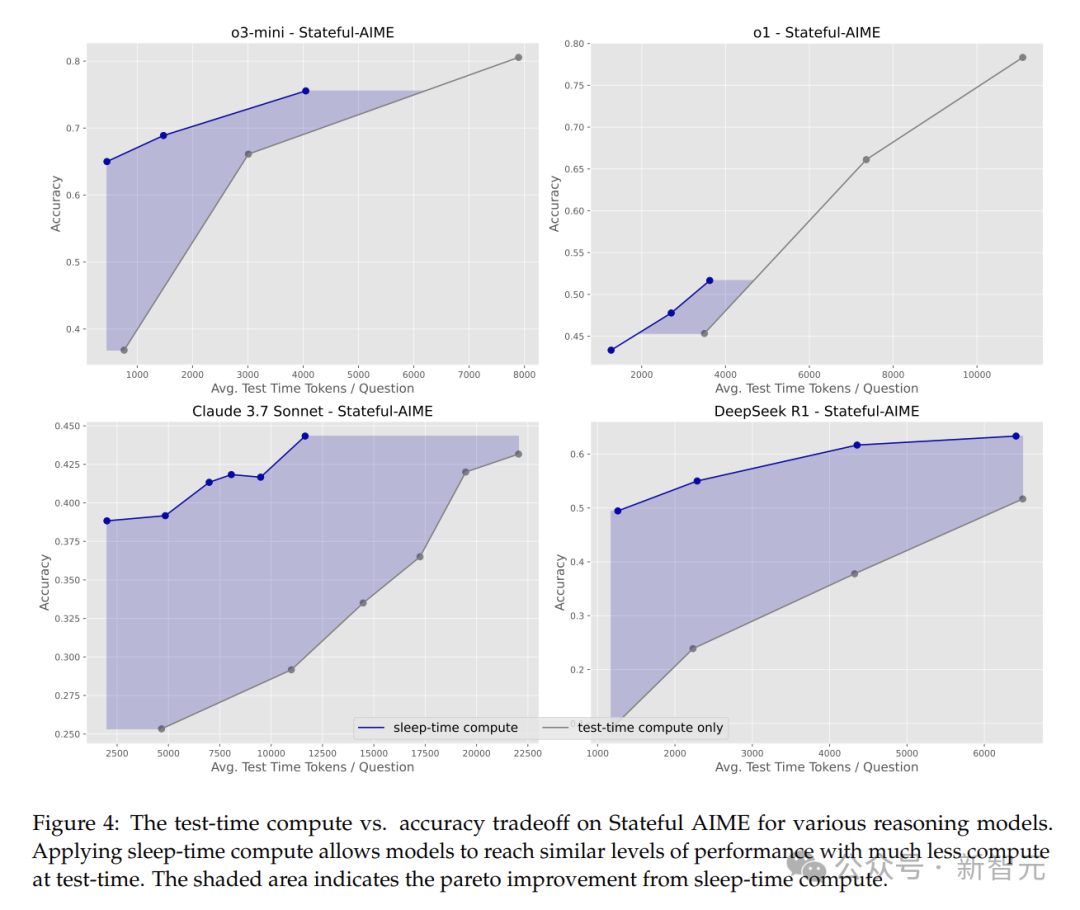
睡眠时计算能否改变测试时计算与准确率之间的帕累托边界?
在Stateful GSM-Symbolic和Stateful AIME中,睡眠时计算展现出了强大的优势,它能将达到相同准确率所需的测试时计算量减少约5倍!
这意味着在资源有限时,用睡眠时计算可让模型保证准确率的同时,大幅减少计算资源消耗。
从图中可以看出,在低测试时预算下,睡眠时计算的性能远超过基线。
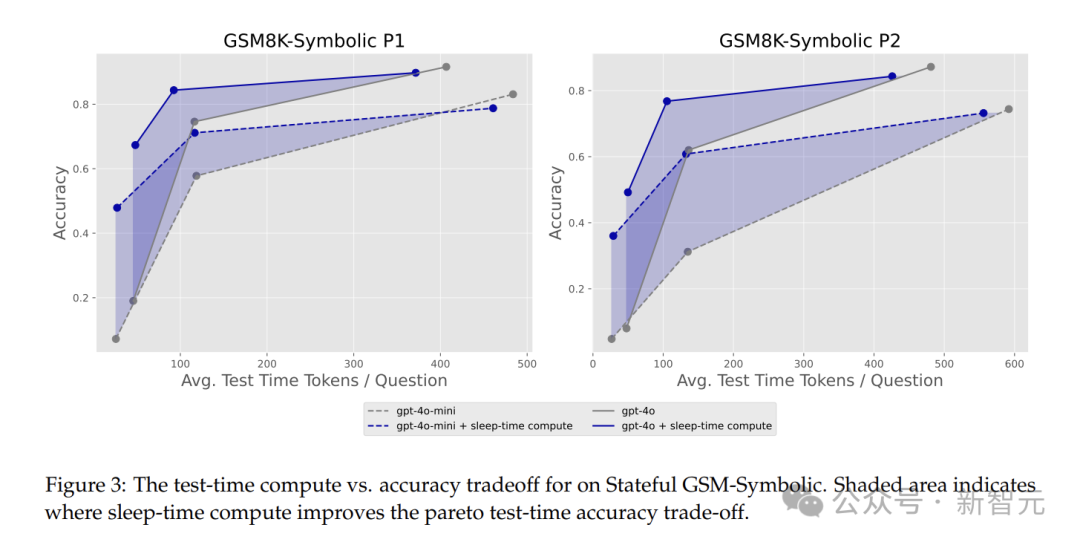
应用睡眠时计算后,测试时间和准确率有显著的帕累托偏移。
扩展睡眠时计算规模,能否进一步优化帕累托边界?
Stateful GSM-Symbolic任务中,扩展睡眠时计算会使帕累托曲线外移,相似的测试时间预算下,性能最高提升13%。
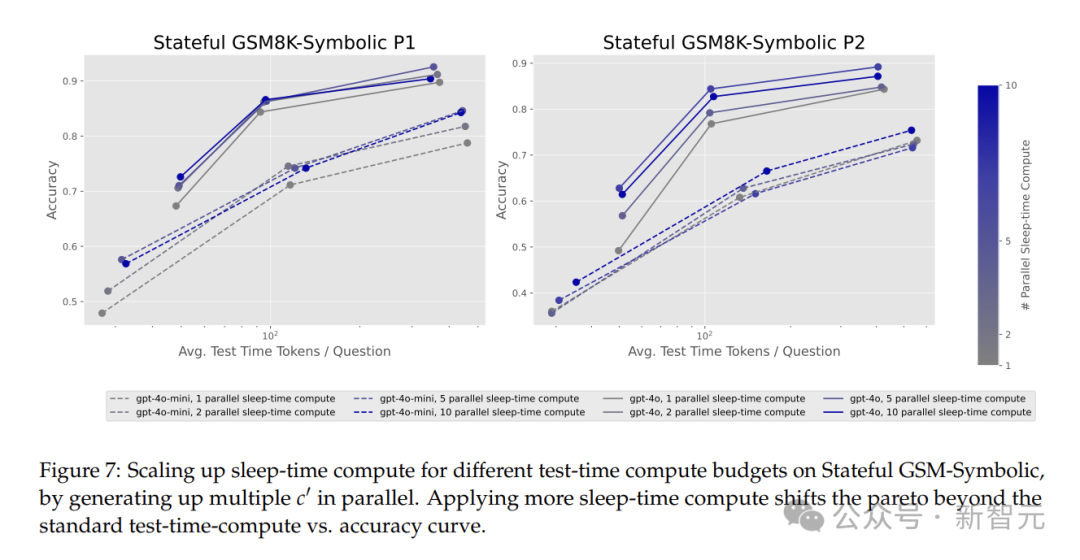
在Stateful AIME任务中,扩展睡眠时计算,性能提升高达18%。
这表明通过合理增加睡眠时的计算资源投入,可以进一步优化模型性能。
当单个上下文对应多个关联问题时,分摊测试时计算与睡眠时计算能否带来总体token效率提升?
研究人员想了解如何在每个上下文都有多个查询的设置中,应用睡眠时计算来改善推理的总成本。
Multi-Query GSM-Symbolic数据集中,当每个上下文有10个查询时,通过分摊睡眠时计算的成本,每个查询的平均成本降低2.5倍。

这对实际应用意义重大,处理大量相关查询时,能大幅降低计算成本。
研究人员还发现,睡眠时计算在查询可预测性高的场景中效果更好。
随着问题从上下文中变得更加可预测,睡眠时计算和标准测试时间计算之间的准确度差距不断扩大。
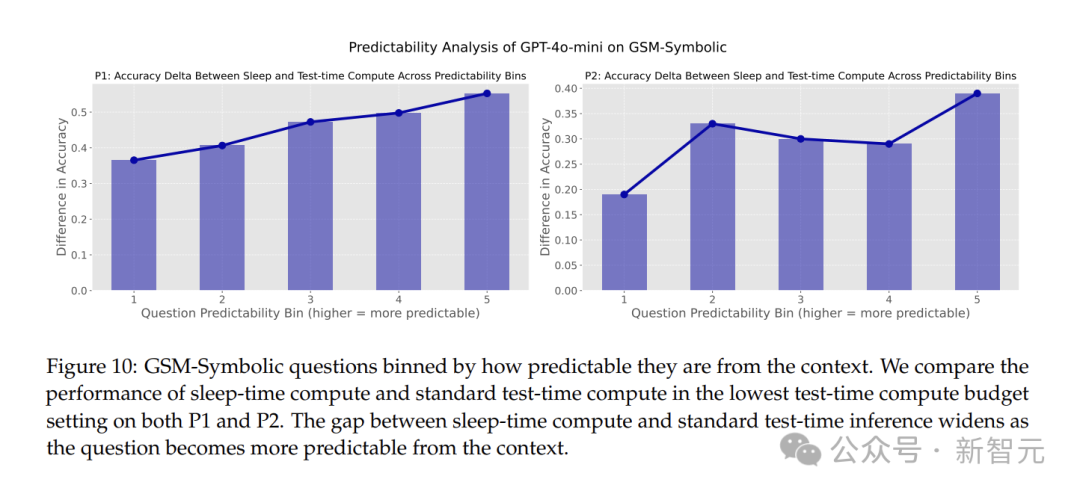
当问题更容易从上下文中预测时,睡眠时计算的效果就越好,模型的性能提升也更为明显。
除了在数学推理任务中的出色表现,睡眠时计算在实际的软件工程任务中也进行了测试。
研究人员引入了SWE-Features这个软件工程基准,它聚焦于需要编辑多个文件和实现新功能的任务。
在这个场景中,研究人员将拉取请求(PR)作为查询q,相关的PR作为上下文c。
在睡眠时间,智能体可以探索存储库,提前总结对相关PR的理解,生成新上下文c’。
而标准测试时计算的基线设置中,智能体在测试时才同时收到上下文和查询信息。
评估方式是比较智能体预测的修改文件集和实际的修改文件集,通过计算F1分数衡量智能体表现。
结果显示,在较低测试时计算预算下,利用睡眠时计算可显著提高性能,测试时token数最多可减少约1.5倍。
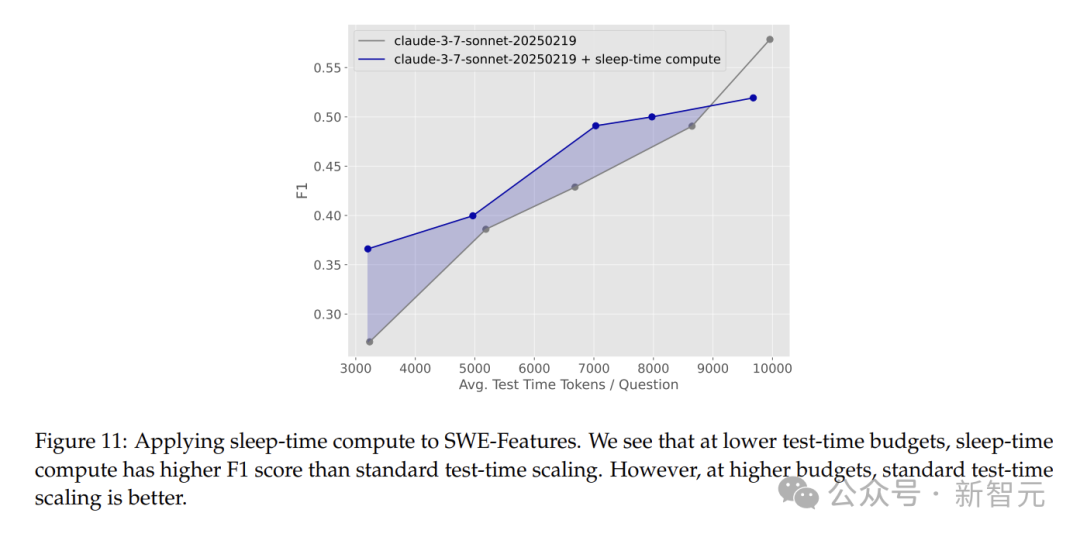
但在高测试时计算预算下,仅用标准测试时计算表现更好,因为它能更早开始编辑文件,且总体编辑文件较少。
启用睡眠时计算的智能体虽然精度略低,但在处理复杂任务方面有一定优势。
(文:新智元)