

前文:图解Vllm V1系列1,整体流程
在前文中,我们讨论了 vllm v1 在 offline batching / online serving 这两种场景下的整体运作流程,以offline batching为例:
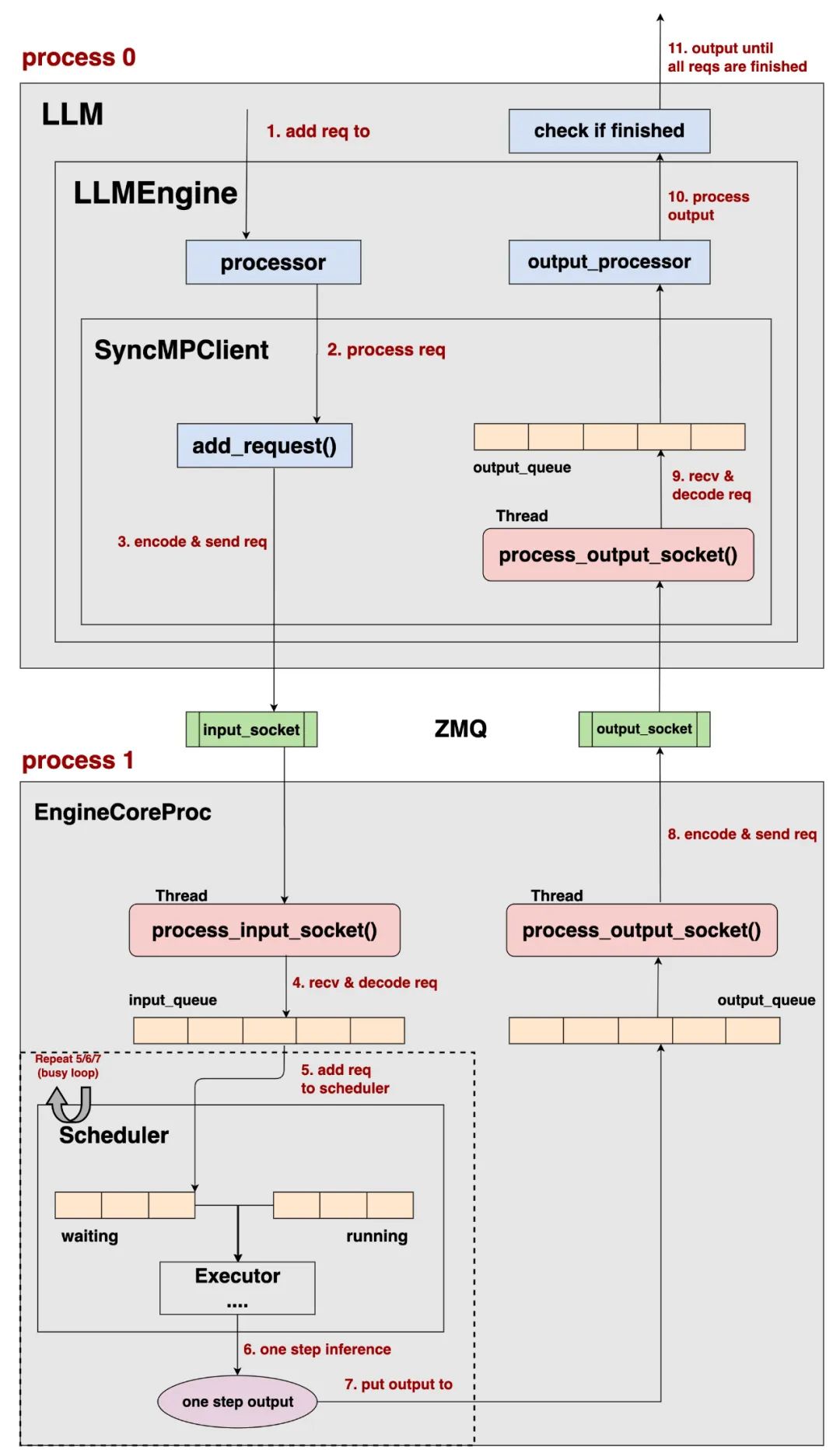
整体上来看:
-
vllm v1将 请求的pre-process和输出结果的post-process与实际的推理过程拆分在2个不同的进程中(process0, process1)。 -
Client负责 请求的pre-process和输出结果的post-process,EngineCore负责实际的推理过程,不同进程间使用ZMQ来通信数据。 -
对于offline batching和online serving来说,它们会选取不同类型的Client进行运作,但是它们的EngineCore部分运作基本是一致的,如上图所示。 -
通过这样的进程拆分,在更好实现cpu和gpu运作的overlap的同时,也将各种模型复杂的前置和后置处理模块化,统一交给processor和output_processor进行管理。
本文我们来关注上图中的Executor部分,也就是管控模型分布式推理的核心部分,我们关注的是它的整体架构和初始化过程,而它实际执行推理的细节,我们留到后续文章细说。
一、Executor的类型
在vllm中,Executor一共有4种类型,由配置参数--distributed-executor-backend决定,相关的代码和文档参见:
代码:
决定executor的类型:https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/config.py#L1465 根据executor的类型,import具体的executor:https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/executor/abstract.py#L25
文档:
https://docs.vllm.ai/en/stable/serving/engine_args.html https://docs.vllm.ai/en/stable/serving/distributed_serving.html#distributed-inference-and-serving
对于--distributed-executor-backend,默认情况下为None,你当然也可以手动指定。在默认情况下,vllm会根据你的分布式配置(world_size)和你所使用的平台特征(cuda、neuron、是否安装/初始化/配置了ray等)来自动决定--distributed-executor-backend的取值。
我们来简单介绍下这4种类型的Executor。
(1)mp:MultiprocExecutor
-
适用场景:单机多卡。当单机的卡数满足分布式配置,且没有正在运行的ray pg时,默认使用mp -
在mp的情况下,Executor成为一个主进程,其下的若干个workers构成了它的子进程们
(2)ray:RayDistributedExecutor
-
适用场景:多机多卡 -
在ray的情况下,Executor成为一个ray driver process,其下管控着若干worker process
(3)uni:UniProcExecutor
-
适用场景:单卡或 Neuron环境
(4)external_launcher:ExecutorWithExternalLauncher
-
适用场景:想要用自定义的外部工具(例如Slurm)来做分布式管理
注意:以上的“适用场景”描述的是一般情况,更具体的细节,请参见“决定executor类型”的相关代码。
在本文中,我们将以mp: MultiProcExecutor进行讲解,并假设这里的分布式配置仅用了tp,其余的细节留给用户自行阅读。
二、Executor -> Workers
2.1 整体架构-官网版
我们先来看下官方给出的Executor-Workers架构图。
https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
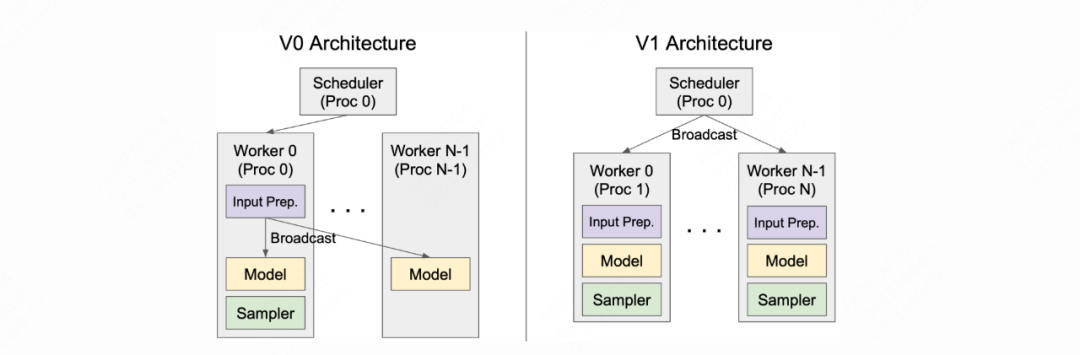
上图右侧刻画了V1的架构:
-
Scheduler和Executor都位于EngineCoreProc所在的进程上。如本文第一章offline batching的流程图所示,Scheduler决定单次调度步骤中要送去推理的请求,并将这些请求发送给Executor。 -
一个Executor下管理着若干workers,每个workers位于独立的进程上,可以理解成一个workers占据着一张卡 -
Executor负责把请求broadcast到各个workers上 -
各个workers接收到请求,负责执行实际的推理过程,并将推理结果返回给Executor。
相比于V0,V1这种架构设计的优势在于:在V0中,worker0既要负责调度和数据分发、又要负责实际的推理计算。如此一来,各个workers间存在负载不均的问题,而worker0将成为性能的瓶颈。而V1通过拆分【调度】和【计算】过程解决了这个问题。
2.2 整体架构-细节版
现在我们已经通过vllm官方的示例图,初步了解了V1下Executor-Workers的架构,现在我们扩展这张架构图,来看更多的细节,为了画图简明,这里我们只展示了其中1个worker,没有画出全部workers:
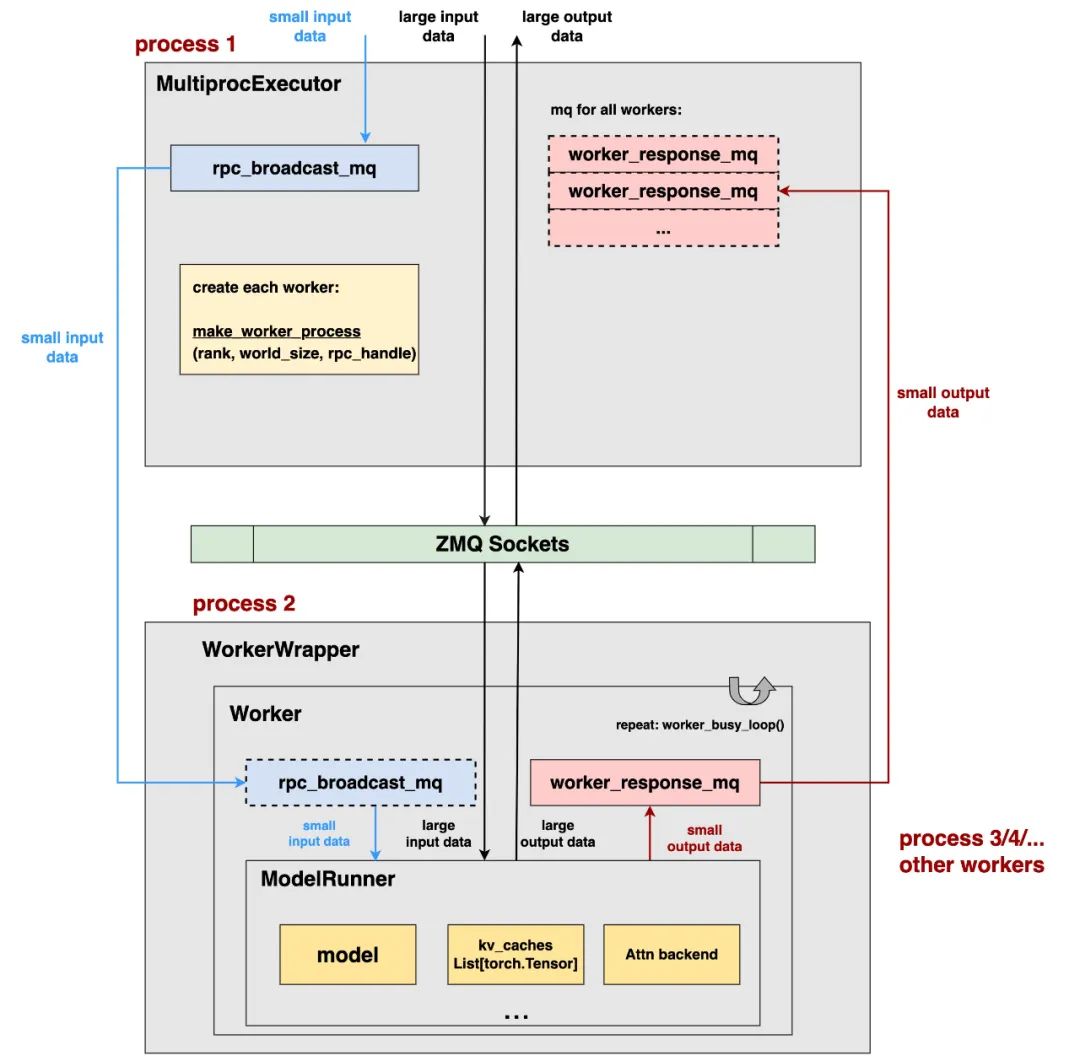
上图展示的是使用MultiprocExecutor下的架构,如前文所说,该类型的Executor常被用于单机多卡的推理场景,我们按照从上到下,从左到右的顺序来解读上图。
1、MultiprocExecutor和Scheduler都位于EngineCoreProc所在的进程中。Scheduler负责决定单次调度步骤中,要送去推理的reqs,并将这些reqs传递给MultiprocExecutor。
2、在MultiprocExecutor上,我们将创建一个rpc_broadcast_mq队列:
-
该队列存储着Executor要broadcast给各个workers的【小数据(<=10MB)】,而【大数据(>10MB)】则不会进入此队列,而是通过zmq socket进行传输
-
每条数据可以被粗糙理解成是(method, data)的形式,data = 数据本身,method=你期望worker上调用什么样的方法来处理这条数据。 -
针对这个队列、以及大小数据的传输细节,我们将在本文第三部分详细介绍。
3、在MultiProcExecutor上,通过make_worker_process创建子进程:
-
每个进程占据一张卡,每个进程上运行着一个worker实例 -
在创建每个子进程时,我们会将rpc_broadcast_mq_handler,也就是输入队列的句柄也传递给子进程,这里你可以粗糙将“handler(句柄)”理解成是一个“地址”,有了这个地址,每个子进程才知道要去哪里找到并【连接】这个队列,以此读到队列中的数据。相关细节我们同样在后文给出。
4、每个Worker实例又由以下几部分组成:
-
WorkerWrapper,每个Worker实例都有属于自己的WorkerWrapper。你可以将它形象理解成是一个worker的manager,它负责管控一个worker的生命周期(创建->销毁)、所占资源、扩展功能(例如在rlhf场景下的一些功能)等等。 -
Worker,真正的Worker实例,它上面维护着两个重要队列: -
rpc_broadcast_mq:正如3中所说,单个worker通过rpc_broadcast_mq_handler这个句柄,连接上了Executor的rpc_broadcast_mq队列,这样它就能从这个队列中读取(method, data)数据。注意,这里说的是【连接】而不是创建,为了强调这一点,图中单worker上的该队列用虚线表示。 -
worker_response_mq:单个worker【创建】的、用于存放这个worker上推理输出结果的队列。同样也会产出worker_response_mq_handler这个句柄。后续这个句柄将通过zmq socket传送给Executor,让Executor可以连接上这个队列,这样Executor就可以获得每个worker的输出结果。 -
ModelRunner,一个worker实例下维护着一个ModelRunner实例,这个实例上维护着模型权重分片(model weights sharding)、这块卡上的kv_caches、attn_backend等一系列的具体模型信息,它将最终负责模型权重的加载(load_model),并执行实际的推理过程。
5、连接Executor和Worker的ZMQ sockets:
-
Executor和Worker分属不同的进程,这里依然采用ZMQ sockets做进程间的通信。 -
这里其实创建了多个不同socket(为了表达简便,我统一画成ZMQ sockets),每个socket会用于不同内容的通信,例如: -
ready_socket:worker进程向Executor发送ready信号 + worker_broadcast_mq_handler -
local_socket:如前文所说,除了使用上述的2个队列做Executor->Worker间的输入输出通信外,我们还会直接使用local_socket做输入输出通信。前者用于单机内快速通信较小的数据(<=10MB),后者用于通信大数据(>10MB)。我们会在后文细说这一点。 -
等等
6、worker_busy_loop():在worker上启动busy loop,持续监听Executor发送的数据、做推理、并将推理结果持续返回给Executor。这样一来,这个worker就无限运转起来了,除非收到用户信号,显式终止掉这个worker,否则这个busy loop不会停止。
到此为止,我们简单总结一下在Executor->Workers的初始化环节都做了什么事:
-
首先,按照上图所示,创建了Executor->Workers架构,特别注意上述2个输入输出队列的初始化和连接。 -
对于每个Worker,我们通过 init_device(),将它绑到指定的卡上,并对它做分布式环境初始化(即制定它的分布式通信group) -
对于每个worker,我们通过 load_model(),当ModelRunner实际去加载这个worker所要的模型分片 -
在每个worker上启动run_busy_loop(),让worker持续不断地运转起来。 更多的细节,请大家自行阅读源码。
接下来,我们着重来讨论这rpc_broadcast_mq和worker_response_mq这两个输入输出队列。
三、Executor与Worker间的数据传输机制
我们先快速回顾一下上文的内容:
(1)在我们的例子中,Executor的具体类型是MultiprocExecutor,它一般适用于单机多卡推理。
(2)Executor和Worker分属不同的进程,Executor需要把输入数据broadcast到Worker上,Worker需要把推理的输出结果返回给Executor。
(3)对于小数据(<=10MB),vllm使用rpc_broadcast_mq和worker_response_mq来做数据传输,这两个队列的本质是ShmRingBuffer(环形共享缓存),其中Shm即我们熟知的shared_memory,而ring是使用环形的方式往shm中读写数据(看不懂也没关系,我们马上来说细节)。
(4)对于大数据(>10MB),vllm使用zmq socket来做数据传输。
为什么要设计2种不同的进程间通信机制,来分别处理【小数据】和【大数据】呢?这里简单说几个我能想到的原因:
(1)首先,通过shm的方式读写数据时,不同的进程都从同一块共享内存(shm)上直接读取,这样数据不需要从一个进程的地址空间复制到另一个进程的的地址空间,也就是可以实现数据的“零拷贝访问”
(2)其次,通过shm的方式读写数据时,可以避免网络协议栈和数据重复写入的开销,可以实现更高效、更快的数据访问。
(3)那么,既然shm这么好,为什么只让【小数据】使用它,而让【大数据】走zmq socket呢?这是因为shm是一块固定的内存大小,一旦预分配好,就不能被改变了。在实际使用场景中,可能需要传输的数据量本身就不大,只是会偶发出现一些【大数据】传输的情况,因此我们没必要预留更大的shm空间,来应对这些只是偶发情况,这样会造成内存的浪费。所以我们额外使用zmq socket来处理这些偶发情况。
3.1 ShmRingBuffer(共享环形缓存)
我们先来看小数据传输的实现机制,相关代码参见:
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/distributed/device_communicators/shm_broadcast.py#L44
假设我们现在只使用tp,即一个Executor下有若干tp workers,那么:
-
Scheduler生成单次调度的结果,将这些结果传递给Executor,我们称单次调度的结果为一个chunk -
Executor拿到单次调度的结果,写入 rpc_broadcast_mq(本质是ShmRingBuffer)中 -
这些tp workers都需要从rpc_broadcast_mq读取这个chunk(每个tp worker的输入是相同的) -
各个tp workers执行推理,并将推理结果写入各自维护的 worker_broadcast_mq(本质是ShmRingBuffer)中。 -
Scheduler继续生成单次调度结果(chunk),重复以上步骤。 -
不难发现,对于一个chunk,我们总有1个writer,和1个或若干个readers,例如: -
rpc_broadcast_mq的chunk中,writer = Executor,readers = tp workers -
worker_broadcast_mq的chunk中,writer = 某个tp worker,reader = Executor
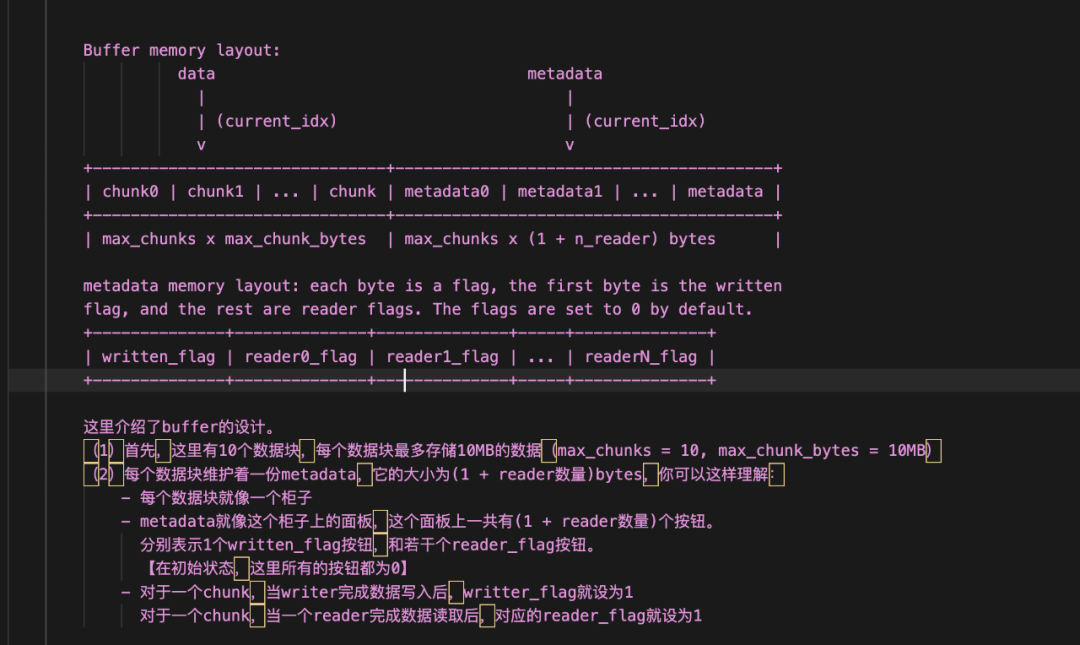
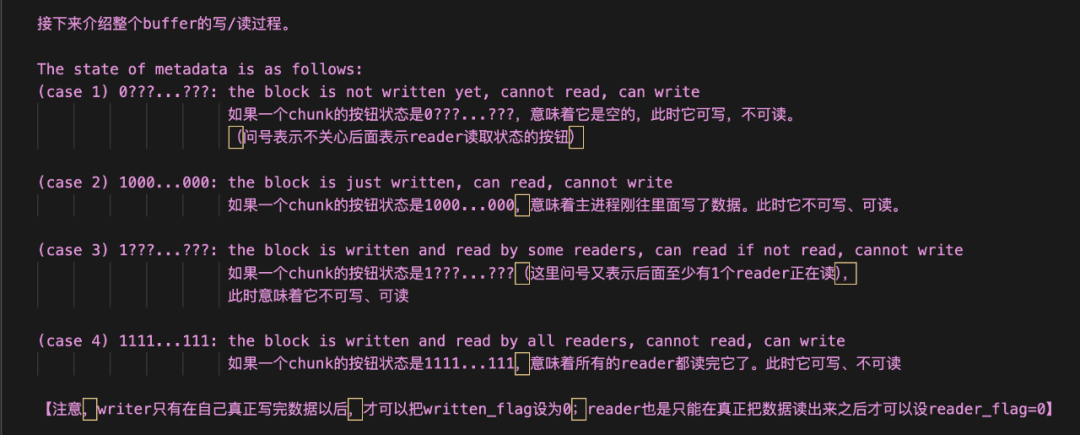
现在,让我们将ShmRingBuffer想象成是一个存储站:
-
这个存储站中有 max_chunks个柜子,每个柜子用于存储一块数据(chunk),max_chunk默认值为10 -
每个柜子的最大数据存储量为 max_chunk_bytes,该值当前默认为10MB -
每个柜子上有一个面板( metadata),这个面板上有1 + n_reader个指示灯。其中1这个指示灯代表written_flag,即用于指示writer是否把chunk塞进了柜子(写入完毕),n_reader个指示灯代表reader_flags,分别表示这些readers是否已经将这个chunk读取完毕。 -
由此可知,对于一个柜子,只有当writer写入完毕后,readers才可以去读。只有当所有readers都读取完毕后,这个柜子里的chunk才可以被“废弃”,也就是这个柜子才可以重新回到“可写入”的状态,让writer写入新数据。 -
Scheduler在做一轮又一轮的调度,产出一个又一个的chunk,那么这些chunk就按照顺序,依次装入这些柜子中,当这10个柜子的数据都被轮番用过以后,下一次再来新chunk前,就从0号柜开始复用起(当然要按照上条所说的,检查该柜子是否达到可复用状态),这种环形使用的方式,称之为“ring”。
有了以上这个形象的理解,现在我们再回过头来看vllm代码中的这部分注释,就不难读懂了,而关于代码的更多细节,请大家自行阅读源码:
3.2 zmq socket
正如前文所说,在Executor和Worker间做大数据(>10MB)的传输时,可以使用zmq socket,这块就是传统的zmq socket构建流程了,没有太多可说的。这里我们想结合worker.worker_busy_loop()(也就是一个worker持续读取输入、进行推理、写入输出)的过程,来具体看一下shm和zmq socket是如何配合运作的。
worker_busy_loop()入口:
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/executor/multiproc_executor.py#L362
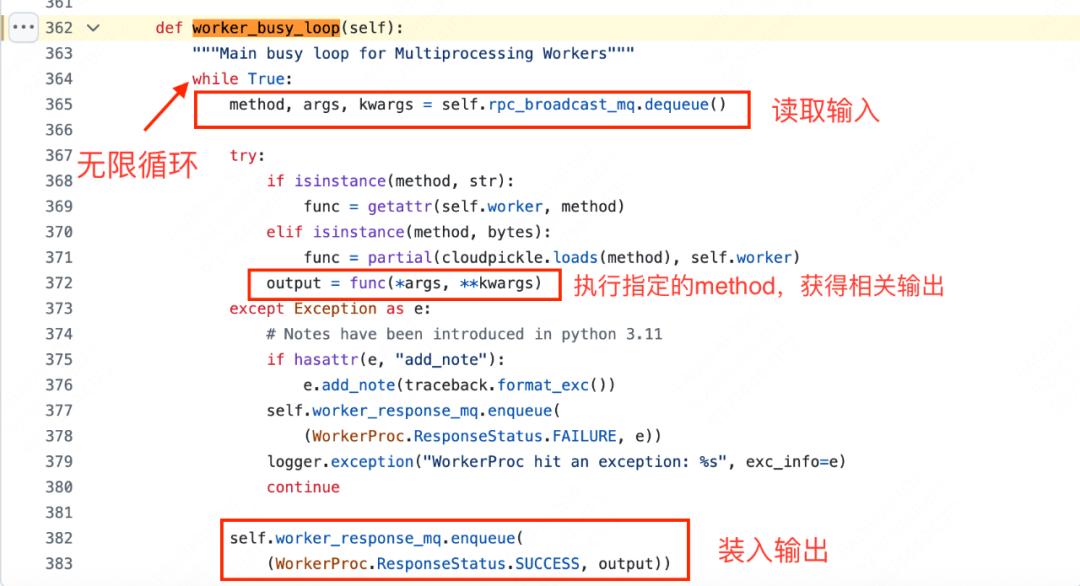
从代码中我们发现一件有趣的事:这里好像只从shm上读取数据,并没有通过zmq socket呀!不要紧,我们现在深入rpc_broadcast_mq.dequeue()中一探究竟。
rpc_broadcast_mq.dequeue():
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/distributed/device_communicators/shm_broadcast.py#L462

整体上说:
-
当一个chunk过来时,我们会先检查它的大小: -
如果<=10MB,则装入shm对应的柜子中 -
如果 > 10MB,则先在shm对应的柜子中记上一笔(buf[0]==1),然后再通过zmq sokcet去send这份数据 -
以上过程不在所提供的代码截图中,需要大家自行找相关代码阅读 -
接着,我们会根据这个柜子的标志buf[0]是否为1,来检测对应的chunk是装在柜子里,还是通过zmq socket发送了。如果是前者,那么直接从shm读;如果是后者,那么就通过zmq socket做receive。 -
最后,如果当前chunk是大数据,虽然它不会装在对应的柜子里,但我们也会认为这个柜子已经被使用过。这样后一个chunk来的时候,它不会使用当前的柜子,而是使用下一个可用的柜子。
你可能会发现,在上述dequeue的代码中,存在2种zmq socket:local_socket和remote_socket,前者用于单机内的通信(writer和readers在一台node内),后者用于多机间的通信(writer和readers不在一台内)。由于我们当前都是以MultiprocExecutor这种单机场景为例的,所以我们提到的zmq socket都是指local_socket。
好,关于Executor->Worker架构的介绍就到这里了,大家可以配合本文,自行阅读源码,获取更多细节。在这个系列后面的文章中,我们还会看到更多Executor-> Worker配合运行的更多例子。
(文:GiantPandaCV)