


就在刚刚(2小时前),DeepSeek在开源社区huggingface上发布了新模型,不是R2,也不是V4。
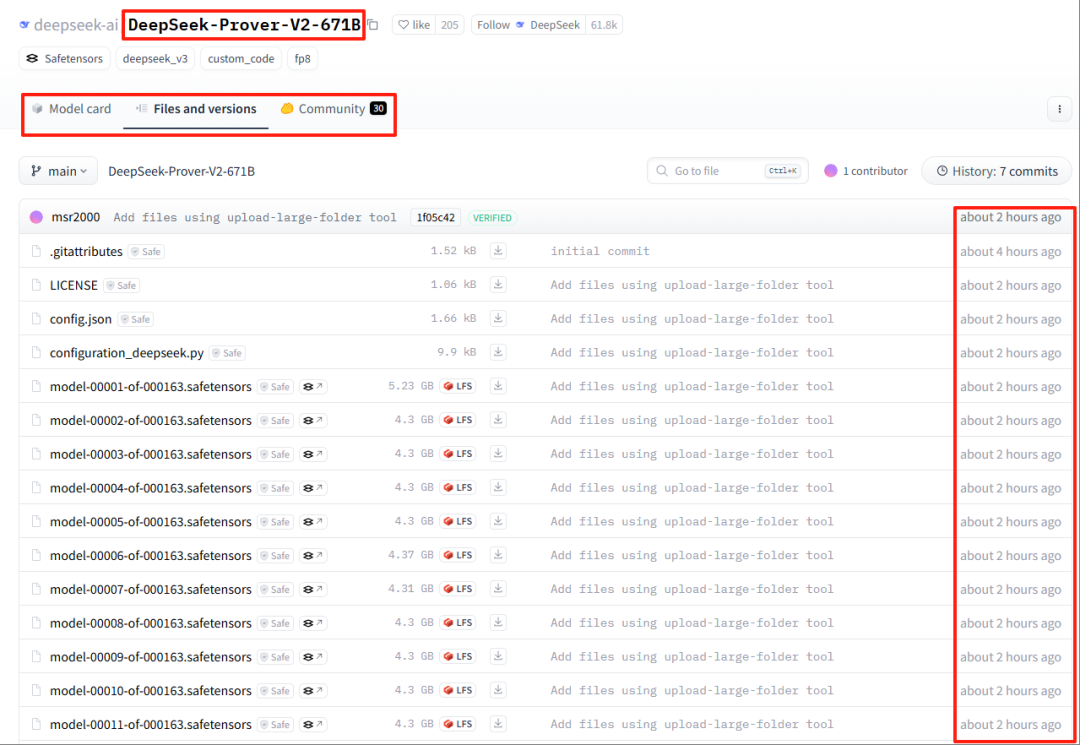
而是【DeepSeek-Prover-V2-671B】,一个专门解决数学问题的专家模型Prover-V2。

新模型依旧采用自由度最高的MIT协议(任何人都可以免费使用、修改、分发和商用)开源。

这是开源网址。
Huggingface社区:
https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B
上一代的DeepSeek-Prover模型,是于去年8月16日发布的DeepSeek-Prover-V1.5模型。当时只有7B,而新一代直接来到了671B,相当炸裂。
Prover在数学中,是证明者的意思, 指“提供证明的一方”,通常与验证者(Verifier)对应。
比如:在交互式证明系统(Interactive Proof System)中,Prover试图说服Verifier某个命题为真。
模型一发,大家纷纷表示“这个五一过不下去了”。

果然,劳动节,劳动者最光荣。
X上有网友@jimmyhe688 用o3整理了Prover与Reason的区别。

以及DeepSeek模型家族的时间线。
这是模型的核心配置json。
{"architectures": ["DeepseekV3ForCausalLM"],"attention_bias": false,"attention_dropout": 0.0,"auto_map": {"AutoConfig": "configuration_deepseek.DeepseekV3Config","AutoModel": "modeling_deepseek.DeepseekV3Model","AutoModelForCausalLM": "modeling_deepseek.DeepseekV3ForCausalLM"},"bos_token_id": 0,"eos_token_id": 1,"ep_size": 1,"first_k_dense_replace": 3,"hidden_act": "silu","hidden_size": 7168,"initializer_range": 0.02,"intermediate_size": 18432,"kv_lora_rank": 512,"max_position_embeddings": 163840,"model_type": "deepseek_v3","moe_intermediate_size": 2048,"moe_layer_freq": 1,"n_group": 8,"n_routed_experts": 256,"n_shared_experts": 1,"norm_topk_prob": true,"num_attention_heads": 128,"num_experts_per_tok": 8,"num_hidden_layers": 61,"num_key_value_heads": 128,"num_nextn_predict_layers": 1,"q_lora_rank": 1536,"qk_nope_head_dim": 128,"qk_rope_head_dim": 64,"quantization_config": {"activation_scheme": "dynamic","fmt": "e4m3","quant_method": "fp8","weight_block_size": [128,128]},"rms_norm_eps": 1e-06,"rope_scaling": {"beta_fast": 32,"beta_slow": 1,"factor": 40,"mscale": 1.0,"mscale_all_dim": 1.0,"original_max_position_embeddings": 4096,"type": "yarn"},"rope_theta": 10000,"routed_scaling_factor": 2.5,"scoring_func": "sigmoid","tie_word_embeddings": false,"topk_group": 4,"topk_method": "noaux_tc","torch_dtype": "bfloat16","transformers_version": "4.46.3","use_cache": true,"v_head_dim": 128,"vocab_size": 129280}
这是模型的configuration_deepseek.py配置。
from transformers.configuration_utils import PretrainedConfigfrom transformers.utils import logginglogger = logging.get_logger(__name__)DEEPSEEK_PRETRAINED_CONFIG_ARCHIVE_MAP = {}class DeepseekV3Config(PretrainedConfig):r"""This is the configuration class to store the configuration of a [`DeepseekV3Model`]. It is used to instantiate an DeepSeekmodel according to the specified arguments, defining the model architecture. Instantiating a configuration with thedefaults will yield a similar configuration to that of the DeepSeek-V3.Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read thedocumentation from [`PretrainedConfig`] for more information.Args:vocab_size (`int`, *optional*, defaults to 129280):Vocabulary size of the Deep model. Defines the number of different tokens that can be represented by the`inputs_ids` passed when calling [`DeepseekV3Model`]hidden_size (`int`, *optional*, defaults to 4096):Dimension of the hidden representations.intermediate_size (`int`, *optional*, defaults to 11008):Dimension of the MLP representations.moe_intermediate_size (`int`, *optional*, defaults to 1407):Dimension of the MoE representations.num_hidden_layers (`int`, *optional*, defaults to 32):Number of hidden layers in the Transformer decoder.num_nextn_predict_layers (`int`, *optional*, defaults to 1):Number of nextn predict layers in the DeepSeekV3 Model.num_attention_heads (`int`, *optional*, defaults to 32):Number of attention heads for each attention layer in the Transformer decoder.n_shared_experts (`int`, *optional*, defaults to None):Number of shared experts, None means dense model.n_routed_experts (`int`, *optional*, defaults to None):Number of routed experts, None means dense model.routed_scaling_factor (`float`, *optional*, defaults to 1.0):Scaling factor or routed experts.topk_method (`str`, *optional*, defaults to `gready`):Topk method used in routed gate.n_group (`int`, *optional*, defaults to None):Number of groups for routed experts.topk_group (`int`, *optional*, defaults to None):Number of selected groups for each token(for each token, ensuring the selected experts is only within `topk_group` groups).num_experts_per_tok (`int`, *optional*, defaults to None):Number of selected experts, None means dense model.moe_layer_freq (`int`, *optional*, defaults to 1):The frequency of the MoE layer: one expert layer for every `moe_layer_freq - 1` dense layers.first_k_dense_replace (`int`, *optional*, defaults to 0):Number of dense layers in shallow layers(embed->dense->dense->...->dense->moe->moe...->lm_head).\--k dense layers--/norm_topk_prob (`bool`, *optional*, defaults to False):Whether to normalize the weights of the routed experts.scoring_func (`str`, *optional*, defaults to 'softmax'):Method of computing expert weights.aux_loss_alpha (`float`, *optional*, defaults to 0.001):Auxiliary loss weight coefficient.seq_aux = (`bool`, *optional*, defaults to True):Whether to compute the auxiliary loss for each individual sample.num_key_value_heads (`int`, *optional*):This is the number of key_value heads that should be used to implement Grouped Query Attention. If`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. Whenconverting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructedby meanpooling all the original heads within that group. For more details checkout [thispaper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to`num_attention_heads`.hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):The non-linear activation function (function or string) in the decoder.max_position_embeddings (`int`, *optional*, defaults to 2048):The maximum sequence length that this model might ever be used with.initializer_range (`float`, *optional*, defaults to 0.02):The standard deviation of the truncated_normal_initializer for initializing all weight matrices.rms_norm_eps (`float`, *optional*, defaults to 1e-06):The epsilon used by the rms normalization layers.use_cache (`bool`, *optional*, defaults to `True`):Whether or not the model should return the last key/values attentions (not used by all models). Onlyrelevant if `config.is_decoder=True`.pad_token_id (`int`, *optional*):Padding token id.bos_token_id (`int`, *optional*, defaults to 1):Beginning of stream token id.eos_token_id (`int`, *optional*, defaults to 2):End of stream token id.tie_word_embeddings (`bool`, *optional*, defaults to `False`):Whether to tie weight embeddingsrope_theta (`float`, *optional*, defaults to 10000.0):The base period of the RoPE embeddings.rope_scaling (`Dict`, *optional*):Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scalingstrategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update`max_position_embeddings` to the expected new maximum.attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):Whether to use a bias in the query, key, value and output projection layers during self-attention.attention_dropout (`float`, *optional*, defaults to 0.0):The dropout ratio for the attention probabilities.```python>>> from transformers import DeepseekV3Model, DeepseekV3Config>>> # Initializing a Deepseek-V3 style configuration>>> configuration = DeepseekV3Config()>>> # Accessing the model configuration>>> configuration = model.config```"""
这款专家模型有着以下特点:
-
模型规模巨大:DeepSeek-Prover-V2-671B模型参数量达671B,上一代V1.5才只有7B,这一代直接飙升到671B,非常炸裂。
-
沿用DeepSeek-V3架构:模型采用MoE(混合专家)模式,利用Lean 4框架进行形式化推理训练,有61层Transformer层,7168维隐藏层。
-
专注数学问题:从模型名称”Prover”可以看出,这是一款专门解决数学问题的专家模型。
-
超长上下文:最大上下文可达163840 tokens,便于处理复杂的数学问题。
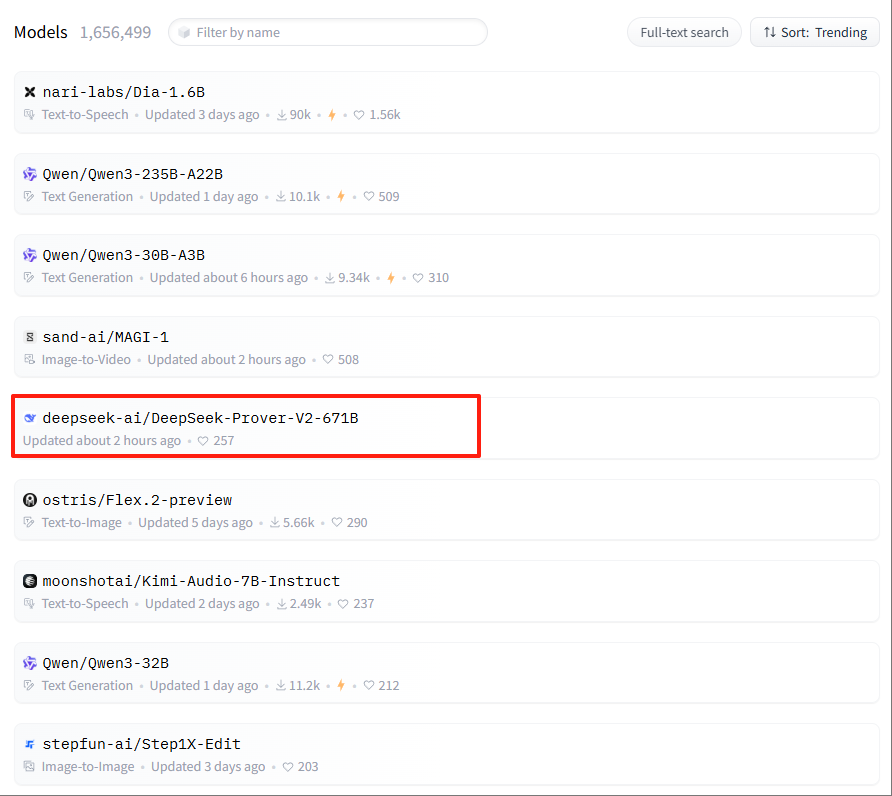
目前,还没有放出这款模型的测评基准。如果有的话,个人预估,这款模型绝对能进数学领域的世界前三水平。
这款模型才刚刚发布,在huggingface上很快就飙升到了热门模型第五。
对于大模型来说,数学一直是一大难题,聪明如o3也才勉强达到博士级水平,而且在一些复杂问题上依旧会犯错。那是OAI能够拿得出的最强模型,还是推理模型。
而DeepSeek-Prover-V2只是基于V3底模的微调,就做到了接近o3的水平,“索哥”确实有点东西。

数学,是AGI的基础。
没有数学,AGI就缺乏Rigorous(严格)的理论支撑和实现路径。
只有攻克了数学问题,AI才能向前突破,向AGI迈进。
从这个角度来说,DeepSeek-Prover-V2-671B模型有着重大的意义。
欣喜,五一节前。
我们相继看到,中国源神Qwen和DeepSeek,陆续闪亮登场。

(文:沃垠AI)