


合作单位包括清华、国科大、上海交大、阿里巴巴。本文第一作者为殷东硕,清华大学计算机系「水木学者」博后,中科院博士,曾以一作身份在 Nature Communications、IEEE CVPR、IEEE ICCV、ACM MM、IEEE TITS 等国际期刊/会议发表论文,并任 NeurIPS、CVPR、ICCV、ICLR、IEEE TIP、IEEE TMM 等会议期刊审稿人。曾获「中国科学院院长奖」,并与微软亚洲研究院 MSRA 和阿里巴巴集团进行科研合作。研究方向包括计算机视觉、参数高效微调、视频生成、多模态以及遥感图像解译等。
Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。

-
论文标题:5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks
-
论文地址:https://arxiv.org/pdf/2408.08345
-
代码地址:https://github.com/Leiyi-Hu/mona
Mona 方法通过引入多认知视觉滤波器和优化输入分布,仅调整 5% 的骨干网络参数,就能在实例分割、目标检测、旋转目标检测等多个经典视觉任务中超越全参数微调的效果,显著降低了适配和存储成本,为视觉模型的高效微调提供了新的思路。
论文亮点
随着现代深度学习的发展,训练数据和模型规模的增加成为模型性能的重要增长点,但随之而来的是模型的垂直应用和微调成本和难度的提升。
传统全量微调需要更新模型所有参数(如 GPT-3 的 1750 亿参数),计算成本极高。即使以早期的 BERT 为例,单卡训练 100 万数据也需 5-7 小时,对硬件资源和时间的要求限制了研究复现和实际应用。
同时,随着模型参数从亿级迈向万亿级,直接微调不仅成本高昂,还可能因过拟合导致性能下降。此外,多任务场景下需为每个任务保存完整模型副本,存储成本剧增。
参数高效微调(Parameter Efficient Fine-Tuning,PEFT)通过保持预训练模型参数冻结,仅调整少量参数就可实现大模型在垂直应用领域的高效适配。但目前大多数 PEFT 方法,尤其是视觉领域的 PEFT 方法的性能相较于全量微调而言还存在劣势。
Mona 通过更适合视觉信号处理的设计以及对预训练特征分布的动态优化,在小于 5% 的参数成本下首次突破了全量微调的性能枷锁,为视觉微调提供了新的解决方案。
本文的核心在于强调:(1)PEFT 对于视觉模型性能上限的提升(尤其是参数量较大的模型);(2)视觉模型在全微调(尤其是少样本情况)会存在严重的过拟合问题;(3)1×LVM + n×Adapter 模式在实际业务中潜在的性能和效率优势。
对于具体业务来说,有些用到 LVM 或者多模态大模型(如 OCR 等任务)的任务会对视觉编码器部分进行固定或仅微调 linear 层来适应下游数据。Mona 的存在理论上可以进一步提升 LVM、多模态大模型对视觉特征的理解和重构,尤其是对于一些少样本 post-training 问题。
方法
Mona 包含降维、多认知视觉滤波器、激活函数和升维等模块,并在适配器内部加入了跳跃连接(Skip-Connections),以增强模型的适应能力。这种结构设计使得 Mona 能够在保持高效的同时,显著提升视觉任务的性能。
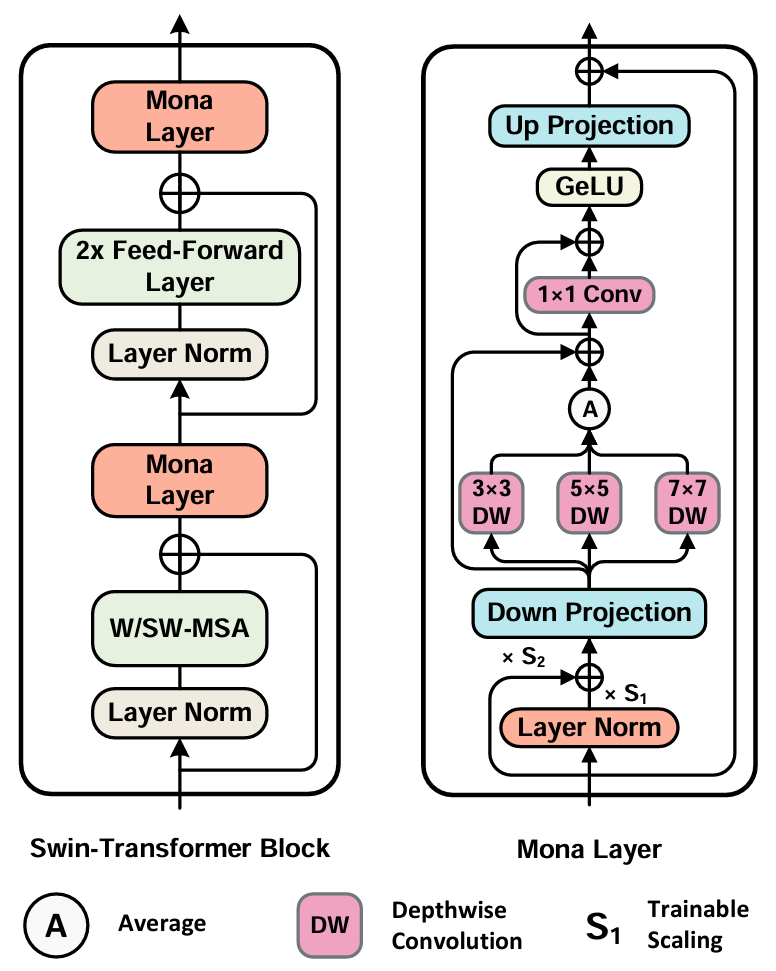
多认知视觉滤波器
Mona 方法的核心在于引入了多认知视觉滤波器,这些滤波器通过深度可分离卷积(Depth-Wise Convolution)和多尺度卷积核(3×3、5×5、7×7)来增强适配器对视觉信号的处理能力。与传统的线性适配器不同,Mona 专门针对视觉任务设计,能够更好地处理二维视觉特征,通过多尺度特征融合提升模型对视觉信息的理解能力。
输入优化
Mona 在适配器的前端加入了分布适配层(Scaled LayerNorm),用于调整输入特征的分布。这种设计能够优化从固定层传递过来的特征分布,使其更适合适配器的处理,从而提高微调效率。
实验结果
实验设置
论文在多个代表性视觉任务上进行了实验,包括:
-
实例分割(COCO)
-
语义分割(ADE20K)
-
目标检测(Pascal VOC)
-
旋转目标检测(DOTA/STAR)
-
图像分类(Flowers102、Oxford-IIIT Pet、VOC2007)
实验使用了 SwinTransformer 系列作为骨干网络,并基于 ImageNet-22k 数据集进行预训练。
性能对比
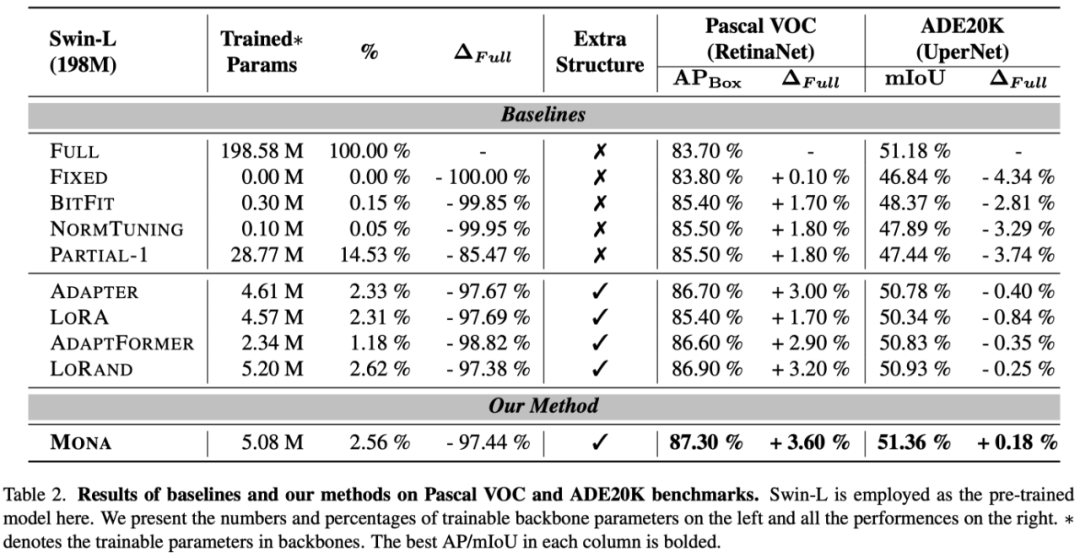
-
在 COCO 数据集上,Mona 方法相比全参数微调提升了 1% 的 mAP,仅调整了不到 5% 的参数。
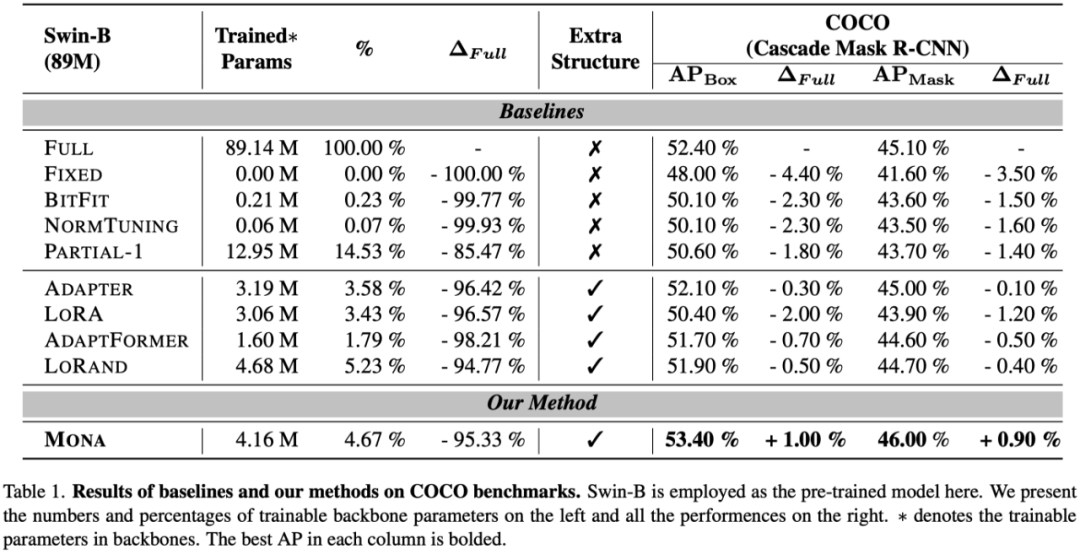
-
在 ADE20K 数据集上,Mona 提升了 0.18% 的 mIoU,表现出色。
-
在 Pascal VOC 数据集上,Mona 提升了 3.6% 的 APbox,显示出显著的性能提升。
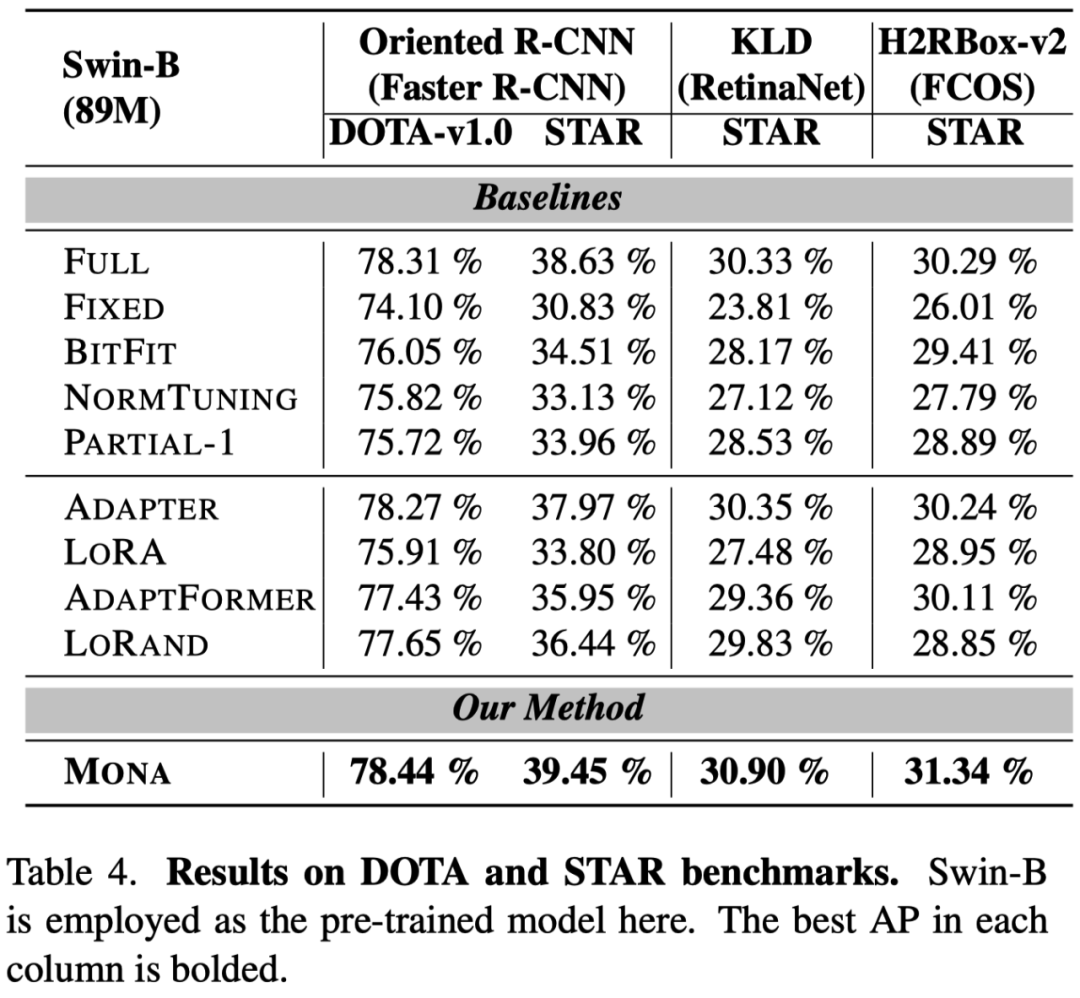
-
在旋转目标检测任务(DOTA/STAR)中,Mona 在多个框架下均优于其他方法。

-
在图像分类任务上,Mona 也有不俗的性能。
收敛性分析

在所有方法中,Mona 收敛速度更快,并且明显超过了全微调。
即插即用模块
import torch.nn as nnimport torch.nn.functional as F# ------------------------------ Mona 模块 ------------------------------INNER_DIM = 64class MonaOp(nn.Module):def __init__(self, in_features):super().__init__()self.conv1 = nn.Conv2d(in_features, in_features, kernel_size=3, padding=3 // 2, groups=in_features)self.conv2 = nn.Conv2d(in_features, in_features, kernel_size=5, padding=5 // 2, groups=in_features)self.conv3 = nn.Conv2d(in_features, in_features, kernel_size=7, padding=7 // 2, groups=in_features)self.projector = nn.Conv2d(in_features, in_features, kernel_size=1, )def forward(self, x):identity = xconv1_x = self.conv1(x)conv2_x = self.conv2(x)conv3_x = self.conv3(x)x = (conv1_x + conv2_x + conv3_x) / 3.0 + identityidentity = xx = self.projector(x)return identity + xclass Mona(BaseModule):def __init__(self,in_dim,factor=4):super().__init__()self.project1 = nn.Linear(in_dim, INNER_DIM)self.nonlinear = F.geluself.project2 = nn.Linear(INNER_DIM, in_dim)self.dropout = nn.Dropout(p=0.1)self.adapter_conv = MonaOp(INNER_DIM)self.norm = nn.LayerNorm(in_dim)self.gamma = nn.Parameter(torch.ones(in_dim) * 1e-6)self.gammax = nn.Parameter(torch.ones(in_dim))def forward(self, x, hw_shapes=None):identity = xx = self.norm(x) * self.gamma + x * self.gammaxproject1 = self.project1(x)b, n, c = project1.shapeh, w = hw_shapesproject1 = project1.reshape(b, h, w, c).permute(0, 3, 1, 2)project1 = self.adapter_conv(project1)project1 = project1.permute(0, 2, 3, 1).reshape(b, n, c)nonlinear = self.nonlinear(project1)nonlinear = self.dropout(nonlinear)project2 = self.project2(nonlinear)return
结论
Mona 方法通过多认知视觉滤波器和输入优化,显著提升了视觉任务的微调性能,同时大幅减少了参数调整量。这一方法不仅在多个视觉任务中超越了传统全参数微调,还为未来视觉模型的高效微调提供了新的方向。
预印版期间,Mona 已被复旦、中科大、南大、武大等多家单位的工作视为 SOTA 方法运用在医学、遥感等领域。Mona 的开源代码将进一步推动这一领域的研究和应用。
©
(文:机器之心)