

编辑:大盘鸡、泽南
DeepSeek R2 的前奏?
五一劳动节到了,DeepSeek 的新消息可没停下来。
前些天到处都在流传着 DeepSeek-R2 即将发布的传言,DeepSeek 确实有新动作,不过大家没等来 R2,等来的是 DeepSeek-Prover-V2,它当然也是开源的。
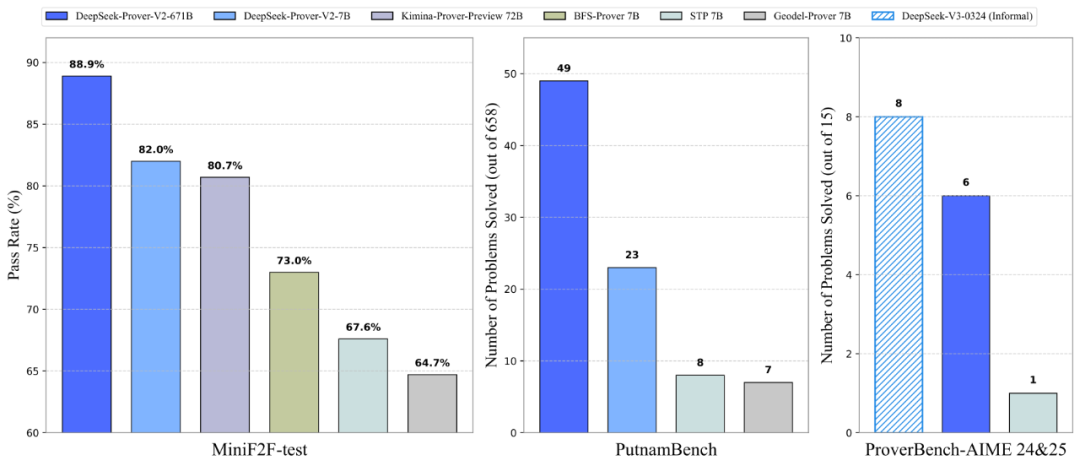
Prover-V2 在定理证明赛道上实现了业内最佳性能,在 MiniF2F 测试中达到了 88.9% 的通过率,在 AIME 24、25 上也有不错的分数。
在 4 月 30 日晚,机器学习协作平台 HuggingFace 上就更新了 DeepSeek-Prover-V2 的一些技术细节。
这次 DeepSeek 团队发布了两个版本的 DeepSeek-Prover-V2 模型,参数规模分别为 7B 和 671B。
其中,DeepSeek-Prover-V2-671B 是在 DeepSeek-V3-Base 基础上训练而成,而 DeepSeek-Prover-V2-7B 则基于 DeepSeek-Prover-V1.5-Base 构建,并支持最长 32K tokens 的上下文长度扩展。
-
DeepSeek-Prover-V2-7B 链接:https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-7B
-
DeepSeek-Prover-V2-671B 链接:https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B
要一句话总结 DeepSeek-Prover-V2 到底是什么?它是一款专为「数学 AI 编程语言」Lean 4 打造的开源大语言模型,专注于形式化定理证明。
它的初始化数据通过一个由 DeepSeek-V3 驱动的递归定理证明流程收集而来。在冷启动训练阶段,首先通过提示 DeepSeek-V3 将复杂问题分解成一系列可以解决的子目标。每解决一个子目标就会将这些证明整合成「思维链」。 并融合 DeepSeek-V3 的逐步推理轨迹,共同构建出用于强化学习的初始训练数据。
这一策略的精妙之处在于:它能够将非形式化和形式化的数学推理融合到一个统一的模型中,让模型既能像人一样灵活思考,也能像机器一样严谨论证,真正实现了数学推理的一体化融合。
具体是如何实现的呢?DeepSeek 也发布了 DeepSeek-Prover-V2 的技术报告,让我们看看其中是怎么说的:

技术概述
通过递归式证明搜索生成冷启动推理数据
为了构建冷启动数据集,DeepSeek 团队设计了一条简洁高效的递归定理证明流程,使用 DeepSeek-V3 作为统一工具,既负责子目标的拆解,也负责推理步骤的形式化表达。其中具体的过程则是通过提示引导 DeepSeek-V3 将定理拆解为高层次的证明草图,并在此过程中同时将这些推理步骤用 Lean 4 语言形式化,最终生成一系列结构清晰、逻辑严密的子目标。

DeepSeek-Prover-V2 使用冷启动数据收集过程概览。
降低计算开销一直是 DeepSeek 团队的强项,这次也不例外。他们使用一个更小的 7B 模型来完成每个子目标的证明搜索,从而降低计算负担。当复杂问题被拆解的各个步骤都成功解决后,他们将完整的形式化逐步证明与 DeepSeek-V3 生成的思维链相对应,组合成冷启动推理数据。
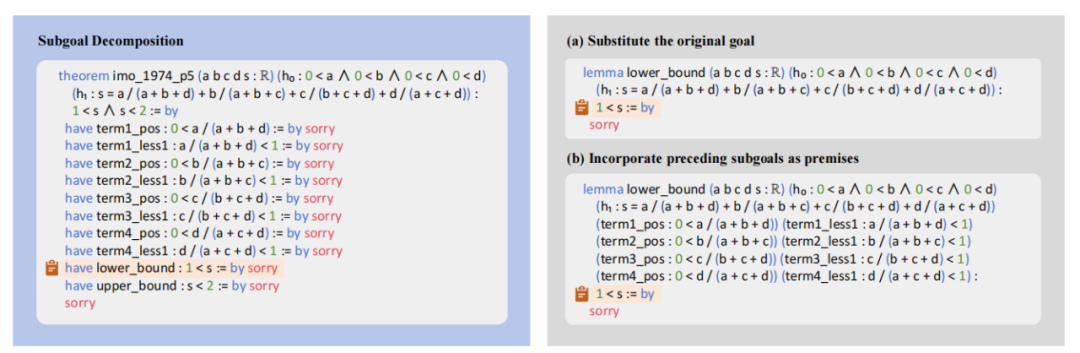
何将分解的子目标转化为一系列引理陈述的一个示例。
基于合成冷启动数据的强化学习
DeepSeek 团队挑选了一部分具有挑战性的定理问题。7B 证明模型没法虽然没法儿将它们端到端的解决,但是能够拿捏拆解出来的一系列子目标。
整合所有子目标的证明就可以构建出原始问题的完整形式化证明。随后,将该正式证明附加到 DeepSeek-V3 所生成的思维链,这条思维链展示了对应的引理拆解过程,从而形成了一份将非形式化推理与后续形式化过程紧密融合的训练数据。
在对证明模型进行合成冷启动数据的微调后,研究团队进一步引入强化学习阶段,进一步提升模型将非形式化推理转化为形式化证明的能力。在训练过程中,遵循推理模型的通用目标,采用「对 / 错」二值反馈作为主要的奖励信号。
最终得到的模型 DeepSeek-Prover-V2-671B 在神经定理证明任务中达到了当前最先进的性能,在 MiniF2F-test 上的通过率达到 88.9%,并成功解决了 PutnamBench 数据集中 658 道题中的 49 道。DeepSeek-Prover-V2 在 miniF2F 数据集上生成的所有证明已整理为 ZIP 文件,开放下载。
下载链接:https://github.com/deepseek-ai/DeepSeek-Prover-V2/blob/main/minif2f-solutions.zip
训练细节、实验结果
DeepSeek-Prover-V2 经历了两阶段训练,这一过程建立了两种互补的证明生成模式:
1. 高效非思维链(non-CoT)模式:此模式针对快速生成正式的 Lean 证明代码进行优化,专注于生成简洁的证明,没有显式的中间推理步骤。
2. 高精度思维链(CoT)模式:此模式系统地阐述中间推理步骤,强调透明度和逻辑进展,然后构建最终的正式证明。
与 DeepSeek-Prover-V1.5 一致,这两种生成模式由两个不同的引导提示控制。在第一阶段采用专家迭代,在课程学习框架内训练一个非 CoT 证明模型,同时通过基于子目标的递归证明合成难题的证明。选择非 CoT 生成模式是为了加速迭代训练和数据收集过程。
在此基础上,第二阶段利用了冷启动链式思维(CoT)数据,通过将 DeepSeek-V3 复杂的数学推理模式与合成形式证明相结合而生成。CoT 模式通过进一步的强化学习阶段得到增强,遵循了通常用于推理模型的标准训练流程。
DeepSeek-Prover-V2 的非 CoT 模式训练过程遵循专家迭代的范式,这是开发形式化定理证明器广泛采用的框架。在每次训练迭代中,当前最佳证明策略用于生成那些在先前迭代中未解决的难题的证明尝试。这些成功的尝试经由 Lean 证明助手验证后,被纳入 SFT 数据集以训练改进的模型。这一迭代循环不仅确保模型能够从初始演示数据集中学习,还能提炼出自己的成功推理轨迹,逐步提高其解决更难问题的能力。总体训练过程与 DeepSeek-Prover-V1 的训练过程大致一致,仅对训练问题的分布进行了两项修改。
首先,Prover-V2 引入了来自自动形式化和各种开源数据集的额外问题,扩大了训练问题领域的覆盖范围。其次,新模型通过子目标分解生成的问题来扩充数据集,旨在解决 MiniF2F 基准测试有效划分中的更多挑战性实例。
研究人员在 DeepSeek-V3-Base-671B 上使用恒定的学习率 5e-6,在 16384 个 token 的上下文中进行监督微调。训练语料库由两个互补来源组成:1)通过专家迭代收集的非 CoT 数据,生成无需中间推理步骤的 Lean 代码;2)第 2.2 节中描述的冷启动 CoT 数据,将 DeepSeek-V3 的高级数学推理过程提炼为结构化的证明路径。非 CoT 组件强调精益定理证明器生态系统中的形式验证技能,而 CoT 示例明确地建模了将数学直觉转化为形式证明结构的认知过程。
Prover-V2 采用 GRPO 强化学习算法, 与 PPO 不同,GRPO 通过为每个定理提示采样一组候选证明并根据它们的相对奖励优化策略,消除了对单独批评模型的需求。训练使用二元奖励,每个生成的 Lean 证明如果被验证为正确则获得 1 个奖励,否则为 0。为了确保有效学习,研究人员精心挑选训练提示,仅包括那些对监督微调模型具有足够挑战性但可解决的问题。模型在每次迭代中采样 256 个不同的问题,为每个定理生成 32 个候选证明,最大序列长度为 32768 个 token。
最后是模型的蒸馏。研究人员把 DeepSeek-Prover-V1.5-Base-7B 的最大上下文长度从 4096 个 token 扩展到了 32768 个,并使用 DeepSeek-Prover-V2-671B 强化学习阶段收集的 rollout 数据对这个扩展上下文模型进行微调。除了 CoT 推理模式外,研究人员还整合了专家迭代过程中收集的非 CoT 证明数据,以实现一种成本效益高的证明选项,该选项能够生成简洁的形式化输出,并且模型规模较小。此外,7B 模型也采用了与 671B 模型训练相同的强化学习阶段以提升性能。
研究人员对 DeepSeek-Prover-V2 在形式定理证明的各种基准数据集上进行了系统评估,涵盖了高中竞赛题目和本科水平的数学问题。实验表明,671B 版的模型实现了前所未有的准确率,且与业内其他先进模型相比效率也更高。

在 miniF2F 测试数据集上与最先进模型的比较。
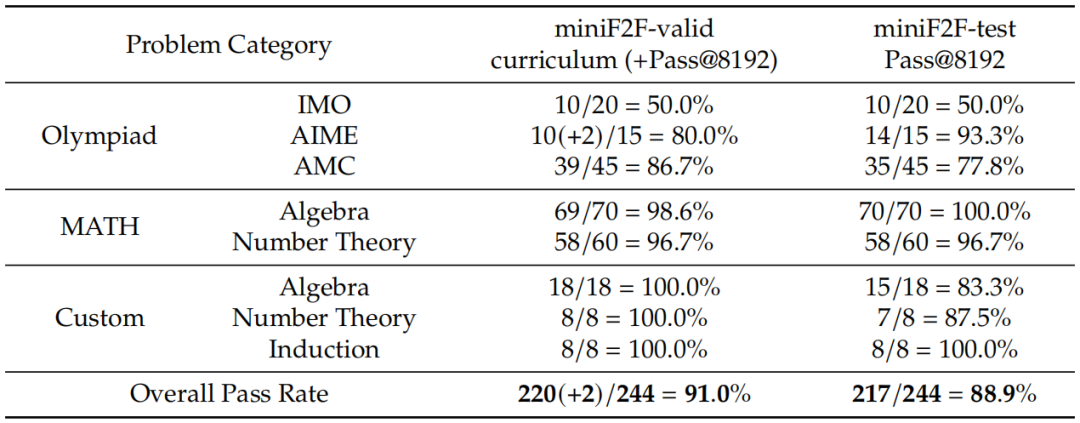
DeepSeek-Prover-V2-671B 在 miniF2F 基准上解决的问题。
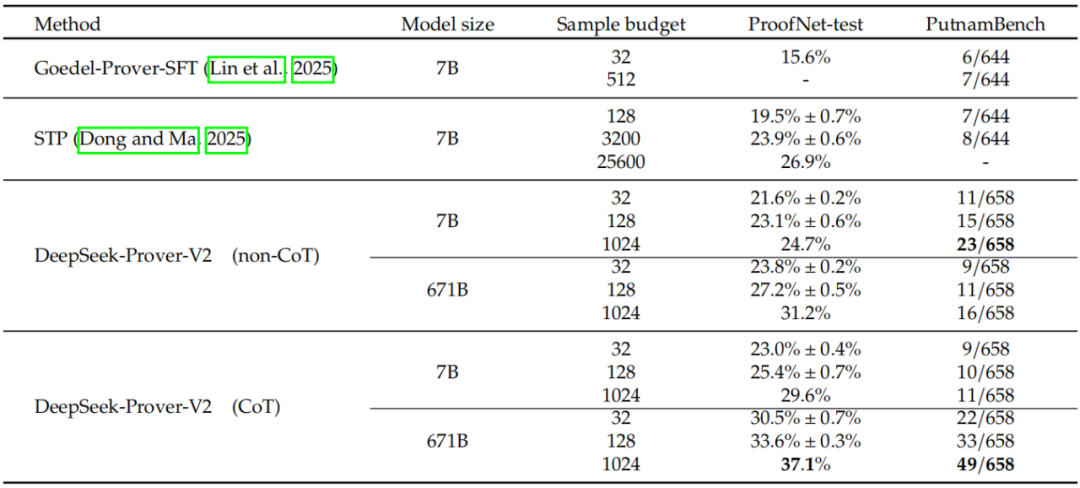
ProofNet – 测试和 PutnamBench 的实验结果。
ProverBench:AIME 与教材题目的形式化基准数据集
这次,DeepSeek 还发布了 ProverBench,这是一个包含 325 道题目的基准数据集。其中,15 道题来自最近两届 AIME 数学竞赛(AIME 24 和 25)中的数论与代数题目,经过形式化处理,具备真实的高中竞赛难度。其余 310 道题则精选自教材示例和教学教程,覆盖内容多样,具有良好的教学基础。
ProverBench 链接:https://huggingface.co/datasets/deepseek-ai/DeepSeek-ProverBench
该数据集旨在支持对模型在高中竞赛题和本科数学题两个层面的综合评估。
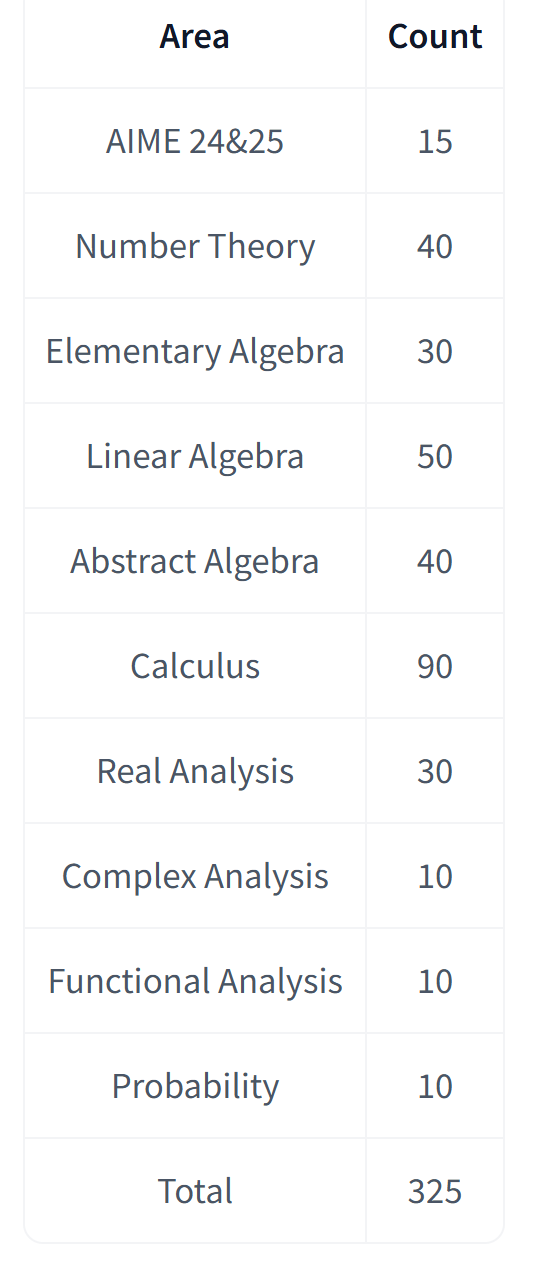
ProverBench 数据集的构成情况
网友评价:太强大了
从新模型的受欢迎程度上来看,大家都在期待 DeepSeek 能够再次改变世界。不少网友对 DeepSeek 新开源的这项工作表示十分欣赏。

还有钻研数学奥林匹克的学生也发来印象深刻的惊呼(做过题的都知道这里面门道有多深)。
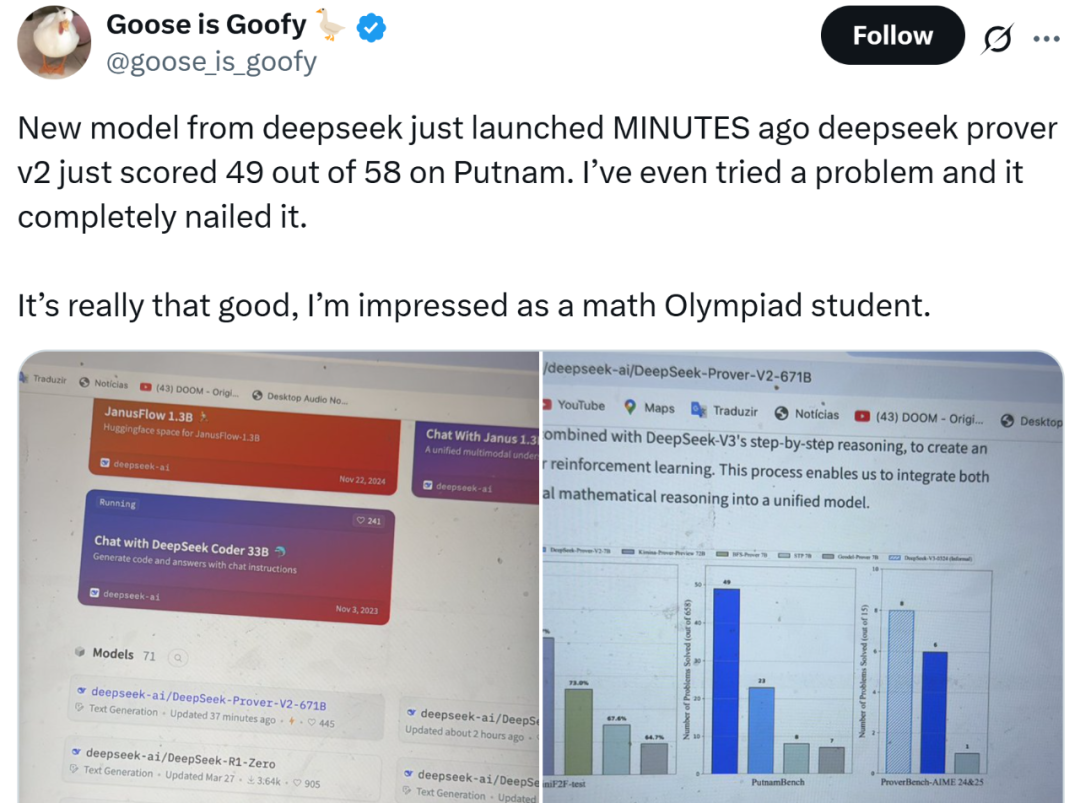
网友亲测,效果真的神,把 o4-mini 和 Grok-3 都比下去了。
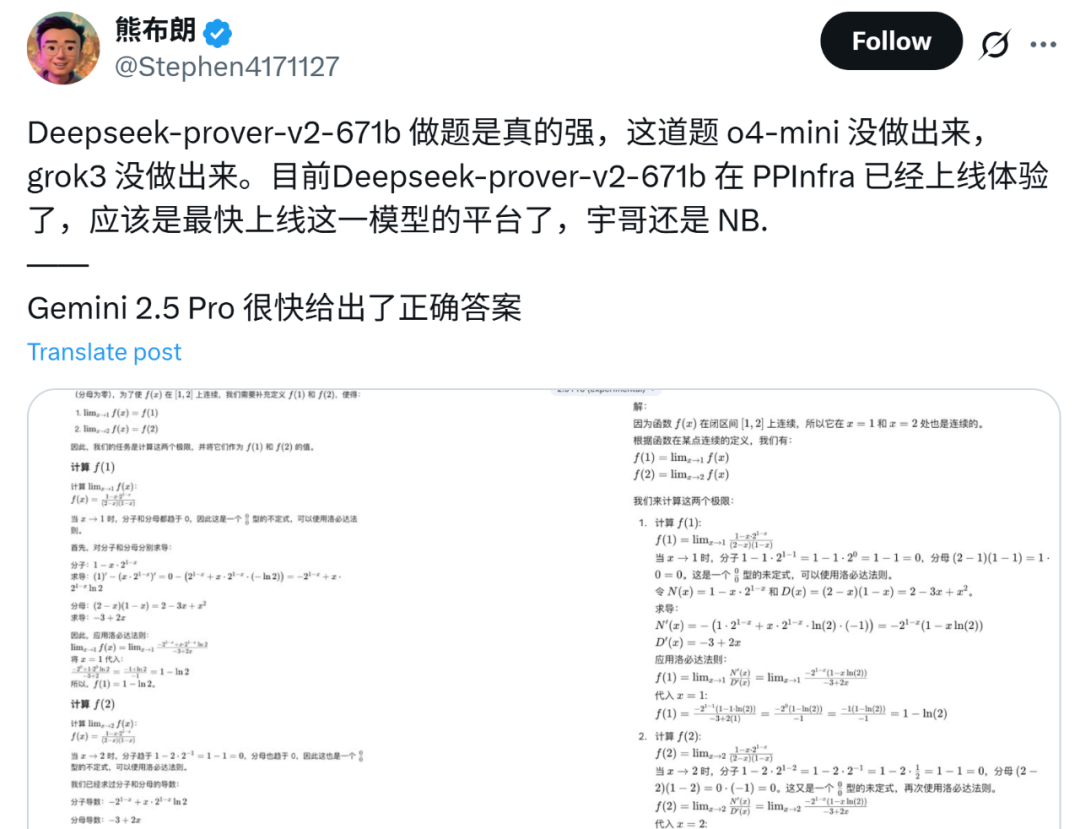
在社交网络上有人表示,将复杂问题分解再处理的方式像极了人们教给初级工程师的技巧,DeepSeek-Prover-V2 处理数学问题的思路对于代码等问题来说应该也是毫无问题。
不过,大家似乎对 DeepSeek-R2 有着更大的热情!敲敲这头小蓝鲸,R2 到底什么时候发出啊!
更多详细内容,请查看原链接~
©
(文:机器之心)