


新智元报道
新智元报道
【新智元导读】自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。
自回归模型的新突破:首次生成2048×2048分辨率图像!
来自Meta、西北大学、新加坡国立大学等机构的研究人员,提出了TokenShuffle,为多模态大语言模型(MLLMs)设计的即插即用操作,显著减少了计算中的视觉token数量,提高效率并促进高分辨率图像合成。

图1:采用新技术的27亿参数自回归模型生成的高分辨率图像
除了实现超高分辨率图像生成外,生成质量也非常出色。
基于27亿参数的Llama模型,新方法显著超越同类自回归模型,甚至优于强扩散模型:
在GenEval基准测试中,获得0.62的综合得分,
在GenAI-Bench上,取得0.77的VQAScore,创造了新的技术标杆。
此外,大规模人类评估,也验证了该方法的有效性。

链接:https://arxiv.org/abs/2504.17789
与传统方法逐个学习和生成每个视觉token不同,新方法在局部窗口内按顺序处理和生成一组token,如图2所示。
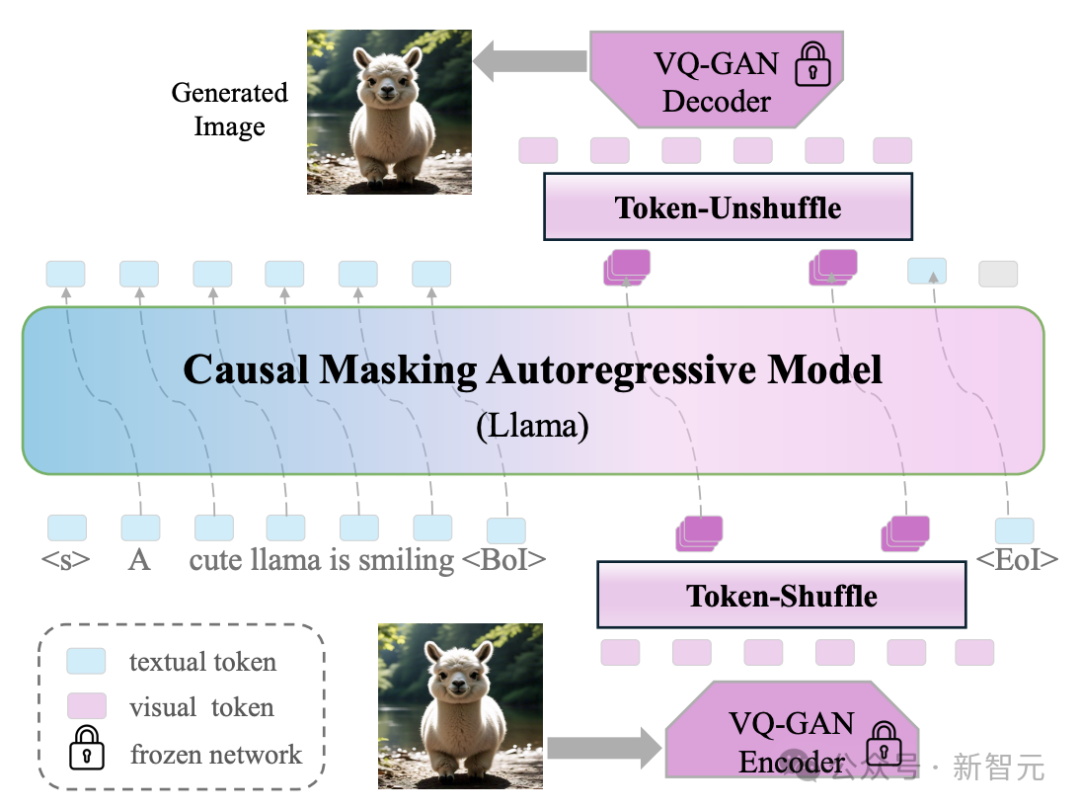
图2:Token-Shuffle流程
Token-Shuffle包括:
token-shuffle操作,用于在Transformer输入阶段合并局部空间内的视觉token,
以及token-unshuffle操作,用于在推理阶段还原视觉token。
该方法显著减少了计算中所需的视觉token数量,同时保持了高质量的生成效果。
而且,Token-Shuffle展现的效能与效率,揭示了其在赋能多模态大语言模型(MLLMs)实现高分辨率、高保真图像生成方面的巨大潜力,为超越基于扩散的方法开辟了新路径。

在语言生成领域,自回归(Autoregression)模型称霸多日。
在图像合成,自回归的应用虽日益增多,但普遍被认为逊色于扩散模型。
这一局限主要源于AR模型需要处理大量图像token,严重制约了训练/推理效率以及图像分辨率。
比如,基于自回归技术的GPT-4o生图,让OpenAI的GPU都「融化」了。
但遗憾的是,OpenAI并没有公开背后的技术原理。

GPT-4o生成的第一视角机器人打字图
这次,来自Meta等机构的研究者,发现在多模态大语言模型(MLLMs)中,视觉词表存在维度冗余:视觉编码器输出的低维视觉特征,被直接映射到高维语言词表空间。
研究者提出了一种简单而新颖的Transformer图像token压缩方法:Token-Shuffle。
他们设计了两项关键操作:
-
token混洗(token-shuffle):沿通道维度合并空间局部token,用来减少输入token数;
-
token解混(token-unshuffle):在Transformer块后解构推断token,用来恢复输出空间结构。
在输入准备阶段,通过一个MLP模块将空间上相邻的token进行融合,形成一个压缩后的token,同时保留局部的关键信息。
对于打乱窗口大小为s的情况,token数量会按s的平方减少,从而大幅降低Transformer的运算量。
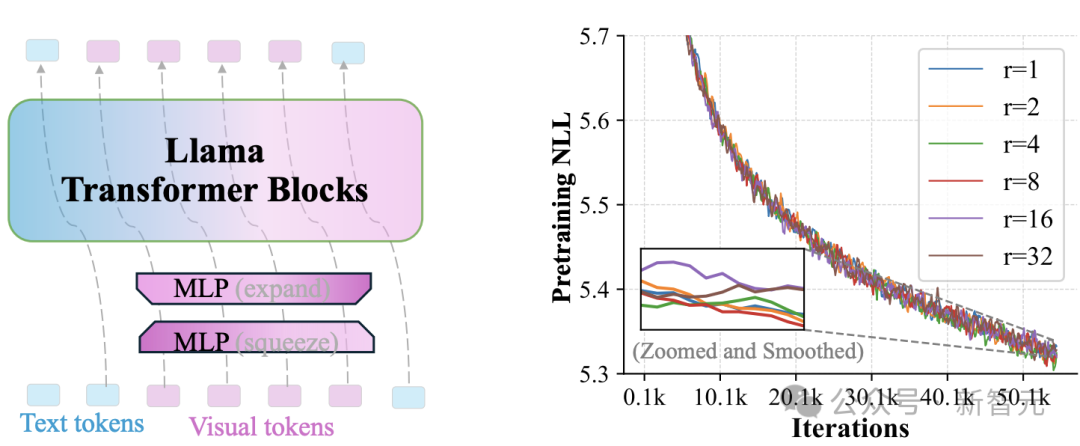
图3:视觉词汇维度冗余的示意图。左侧:通过两个MLP操作将视觉token的秩降低r倍。右侧:不同r值下的预训练损失(对数刻度困惑度)
在经过Transformer层处理后,token-unshuffle操作重新还原出原本的空间排列过程。这一阶段同样借助了轻量级的MLP模块。
本质上,新方法在训练和推理过程中并未真正减少序列长度,而是在Transformer计算过程中,有效减少了token数量,从而加速计算。
图4直观地展示了新方法在效率上的提升。
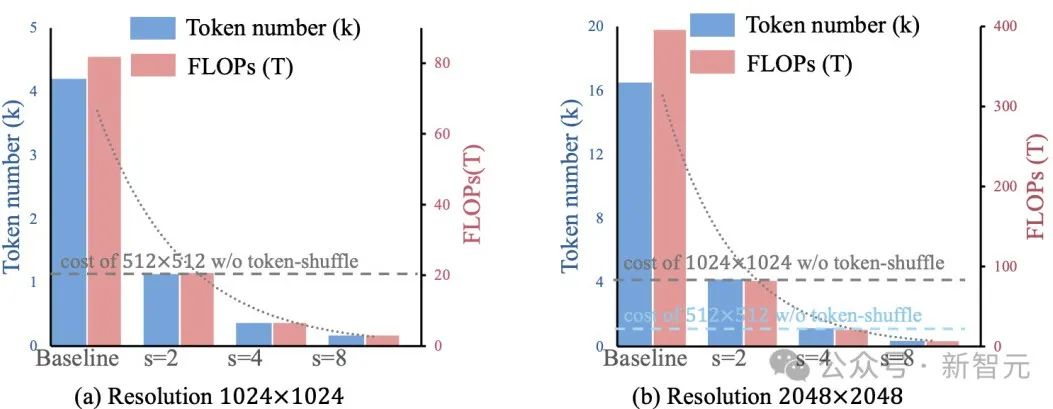
图4:Token-Shuffle能够实现计算效率的二次提升
通过在Transformer计算期间压缩token序列,Token-Shuffle实现了高效的高分辨率图像生成,包括支持2048×2048分辨率的图像。
重要的是,这种方法无需对Transformer架构本身进行修改,也不引入辅助损失函数或需要额外预训练的编码器。
此外,该方法还集成了一个针对自回归生成专门调整的无分类器引导(Classifier-Free Guidance,CFG)调度器。
不同于传统的固定引导强度,新的CFG调度器在推理过程中逐步调整引导力度,减少早期token生成的伪影问题,并进一步提升文本与图像的对齐效果。
研究者探索了几种CFG调度策略,相关结果展示在图5中。
根据视觉质量和人类评估的反馈,默认采用「半线性」(half-linear)调度器,以获得更好的生成效果。

图5:不同CFG调度器的比较,CFG尺度从1单调增加到7.5
右侧结果显示,相较于在所有视觉token上使用固定7.5的CFG值,采用CFG调度器能够同时提升图像的美学质量和文本对齐效果。

不同无分类器引导(CFG)尺度下的生成图像示例
该方法通过与文本提示联合训练,无需额外预训练文本编码器,就能让MLLMs在下一个token预测框架下,支持超高分辨率图像合成,同时保持高效训练推理。
这是自回归模型首次实现2048×2048分辨率的文生图。
在GenAI基准测试中,27亿参数Llama模型在困难提示下取得0.77综合得分,较AR模型LlamaGen提升0.18,超越扩散模型LDM达0.15。
大规模人工评估也证实新方法在文本对齐度、视觉缺陷率和美学质量上的全面优势。
在MLLMs高效生成高分辨率图像领域,Token-Shuffle有望成为基准设计方案。
消融实验等更多内容和细节,参阅原论文。

实验使用2.7B Llama模型,维度为3072,由20个自回归Transformer模块组成。
模型的预训练被分为3个阶段,从低分辨率到高分辨率图像生成。
首先,研究者使用512×512分辨率的图像进行训练,在此阶段不使用Token-Shuffle操作,因为此时视觉token的数量并不大。在这一阶段,他们训练了约50亿个token,使用4K的序列长度、512的全局批量大小和总共211K步。
接下来,研究者将图像分辨率提升到1024×1024,并引入Token-Shuffle操作,减少视觉token数量,提高计算效率。在这一阶段,他们将训练token数量扩展到2TB。
最后,研究者使用之前训练的checkpoint,将分辨率进一步提升至2048×2048,训练约300亿个token,初始学习率设为4e−5。
他们引入了z-loss,用于稳定高分辨率图像生成的训练。
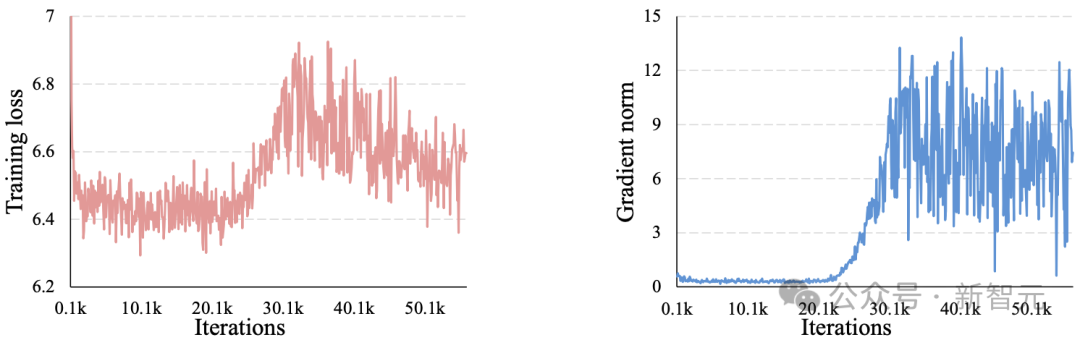
原文图11:在2048×2048分辨率下训练时的平均损失(左)和梯度范数(右)。在大约20K次迭代后出现训练不稳定现象
在不同阶段,研究者对所有模型进行了微调,学习率为4e−6,使用1500张精选的高美学质量图像进行展示。
默认情况下,除非另有说明,可视化和评估是基于1024×1024分辨率和2大小的token-shuffle窗口的微调结果。
表1中的结果突显了Token-Shuffle的强大性能。
与其他自回归模型相比,新方法在「基本」(basic)提示上整体得分超越LlamaGen 0.14分,在「高难度」(hard)提示上超越0.18分。
与扩散基准相比,新方法在「高难度」提示上超越DALL-E 3 0.7分。

表1:在GenAI-Bench上的图像生成VQAScore评估。「†」表示图像是通过Llama3重写提示生成的,保证训练与推理的一致性
除了表1中报告的VQAScore结果外,研究者还进行了额外的自动评估GenEval,并在表2中报告了详细的评估结果。
实验结果表明,除了高分辨率外,Token-Shuffle作为一个纯自回归模型,能够呈现出令人满意的生成质量。
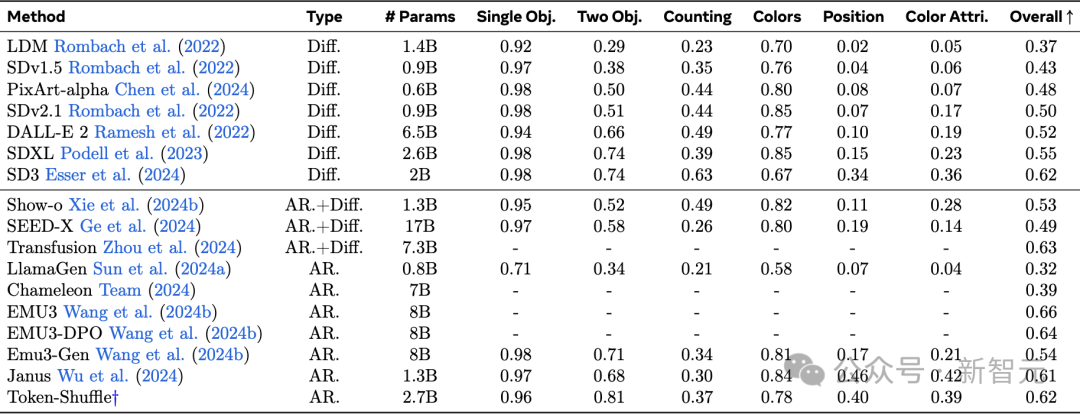
表2:在GenEval基准测试上的评估。
尽管自动化评估指标提供了无偏的评估,但最近的研究所指出它们可能并不能完全捕捉到人类偏好。
为此,研究者还在GenAI-Bench提示集上进行了大规模的人类评估,将新模型Token-Shuffle与LlamaGen、LuminamGPT和LDM进行了比较,分别代表了自回归模型、MLLM和扩散模型。
在人类评估中,重点关注三个关键指标:
-
文本对齐,评估图像与文本提示的匹配准确度;
-
视觉缺陷,检查逻辑一致性,避免出现不完整的身体或多余的肢体等问题;
-
视觉外观,评估图像的美学质量。

存在视觉缺陷与结构错误的生成图像示例(红色圆圈标记处)
图6展示了结果,新模型在所有评估方面始终优于基于自回归的模型LlamaGen和LuminamGPT。
这表明,即使在大幅减少token数量以提高效率的情况下,Token-Shuffle也能有效地保留美学细节,并且能够紧密遵循文本引导,前提是进行了充分的训练。
在生成结果(无论是视觉外观还是文本对齐)上,研究者展示了基于自回归的多模态大语言模型(AR-based MLLMs)能够与扩散模型相媲美或更胜一筹。
然而,研究者观察到,Token-Shuffle在视觉缺陷方面略逊于LDM。

图6:人类评估结果|在文本对齐、视觉缺陷和视觉外观方面等方面,比较了Token-Shuffle与无文本的自回归模型LlamaGen、带文本的自回归模型Lumina-mGPT以及基于扩散的模型LDM的表现
研究者将Token-Shuffle与其他模型进行了视觉效果对比,包括两种基于扩散的模型LDM和Pixart-LCM,以及一种自回归模型LlamaGen。
图7展示了可视化例子。
虽然所有模型的生成效果都不错,但Token-Shuffle在文本对齐方面表现得更加出色。
与自回归模型LlamaGen相比,Token-Shuffle在相同推理开销下实现了更高的分辨率,带来了更好的视觉质量和文本对齐效果。
与扩散模型相比,自回归模型Token-Shuffle在生成性能上表现出竞争力,同时还能支持高分辨率输出。

图7:与其他开源的基于扩散模型和基于自回归模型的视觉效果对比
马旭(Xu Ma)

他是美国东北大学工程学院的博士研究生。
在此之前,他在美国德克萨斯大学北部分校计算机科学与工程系工作了两年。
在南京林业大学信息科学与技术学院, 他获得了学士和硕士学位。
他的研究兴趣包括:模型效率、多模态大语言模型(LLM)、生成式人工智能(Generative AI)。
在博士学习期间,他获得了一些奖项,包括ICME’20最佳学生论文奖、SEC’19最佳论文奖、NeurIPS’22杰出审稿人奖和CVPR’23杰出审稿人奖。
(文:新智元)