

沉浸式翻译我相信只要是 AI 圈子的人基本上人手一个,甚至你如果经常看海外内容不可能没有。
他可以用 AI 或者常规翻译生成整个网页的多语言对照翻译,还有连按三下空格将输入框的中文翻译为英文这个神级技能。

除了体验很好之外还非常良心,免费提供几乎无限量的谷歌翻译额度,而且几乎适配了所有的模型 API,你可以随意填写自己的。
然后前几天我发现他们发了个新功能:Babeldoc,支持在翻译 PDF 的时候保持文件的原始排版,而且还能完整提取 PDF 内嵌的图表、脚注、公式等⾮⽂本元素。
刚开始我是不信的,过去这一两年相信大家都用过很多类似 PDF 翻译工具了,都知道这玩意想要翻译的同时保持排版有多难。
我随手拿一个论文 PDF 试了一下,我去这玩意真的🐂🍺,整个 PDF 的排版真的一点都不带差的。
之后就用我们最近比较热的几个 PDF 试了试,真的很猛,各位可以看一下详细的测试。
另外翻译好的谷歌提示词 PDF 和 HAI 2025 年人工智能报告的文件我也会放在文章后面,感兴趣的可以领取。
先来点低难度的常见的论文,一般都不会有非常复杂的排版,难点主要在图表和表格以及公式上。
比如常见的论文开头部分,像字节和 Meta 的论文都是这样,从标题到摘要部分到下面的图表都能对得上。
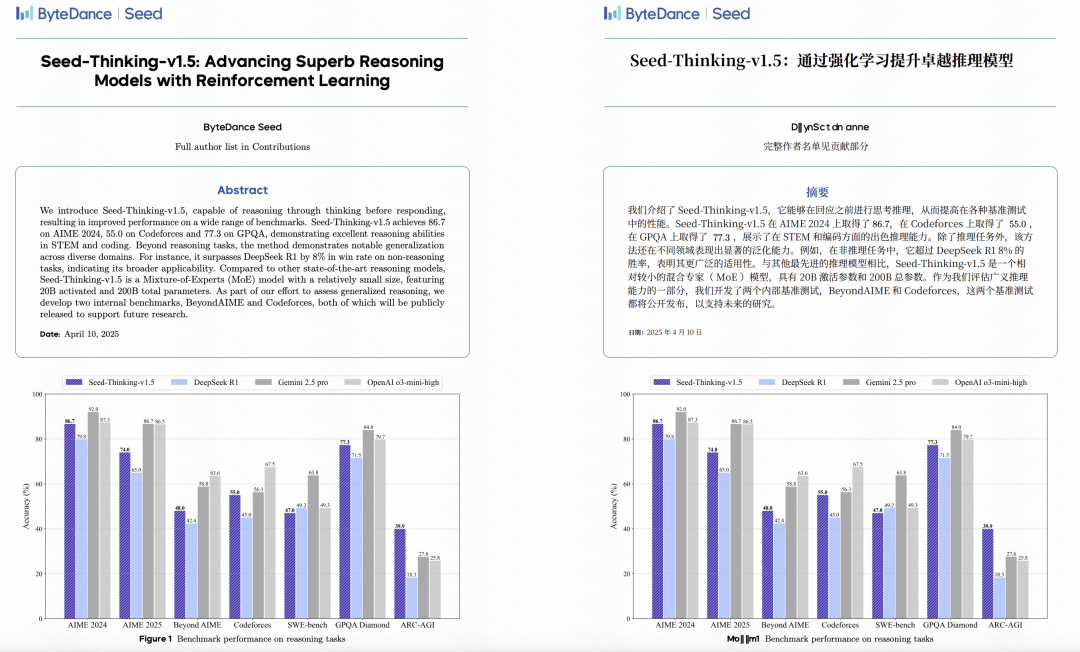
学术论文中很多数学公式、化学公式的排版非常复杂,以前如果周围有公式,那文字的排版就不太好保持了。
Babeldoc 这个就很厉害中英文的字数和单词长度肯定是不一样的,但是他们就是能保证两者都在差不多的位置。

然后就是表格了虽然 Babeldoc 横线没了,但是不影响阅读,整体的格式已经保持的很好了。
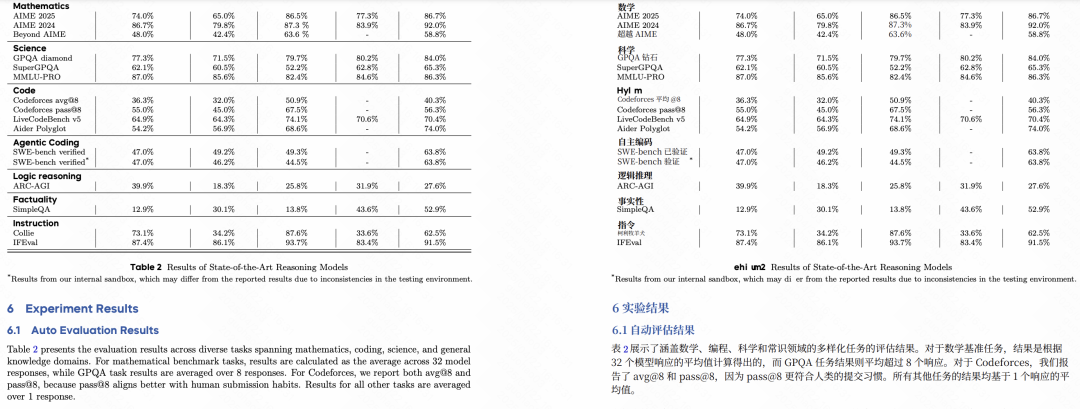
然后我们来一个稍微复杂点的,前段时间比较火的谷歌提示词写作教程的 PDF。
这个 PDF 明显会专门做了一些排版,重新定义了不同的字号和间距,还有不同的字体,这种一般挺麻烦的,虽然看起来还是白底黑字。
Babeldoc 依然没有问题,整个字号和段间距、行间距都跟原始 PDF 是一致的。

当然这里也有点小问题,由于谷歌这个 PDF 在代码和提示词的部分用了一个别的字体,Babeldoc没有读取到,所以没有翻译。
但其实也还好本来代码也不需要翻译,同时为了兜底,沉浸式翻译的文档翻译还支持导出中英双语对照的 PDF,这个功能完美解决了问题,而且这个问题我也反馈给他们了。
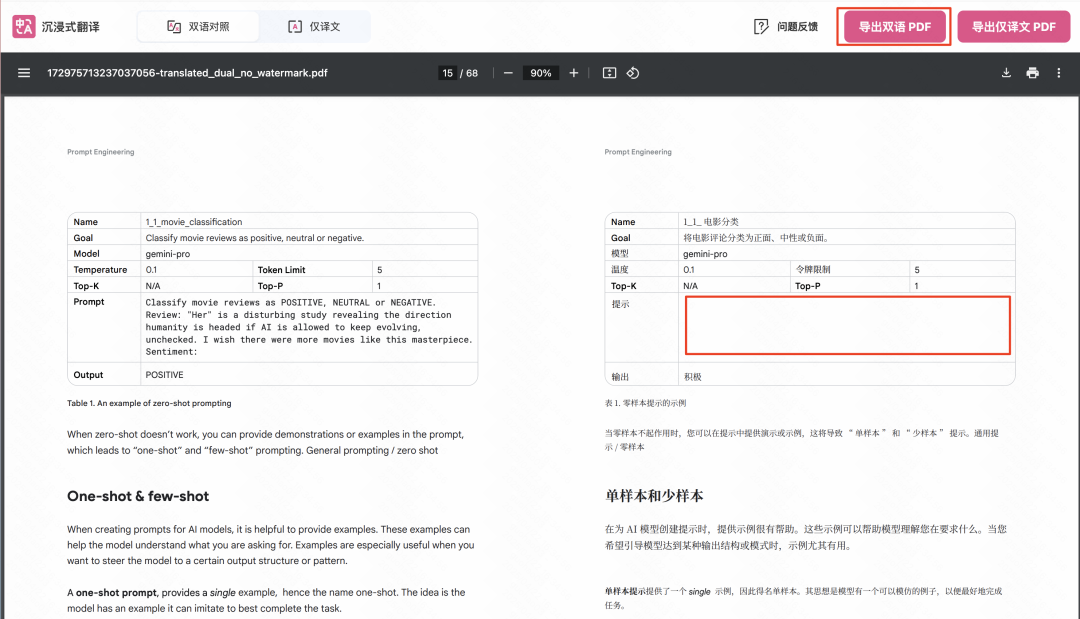
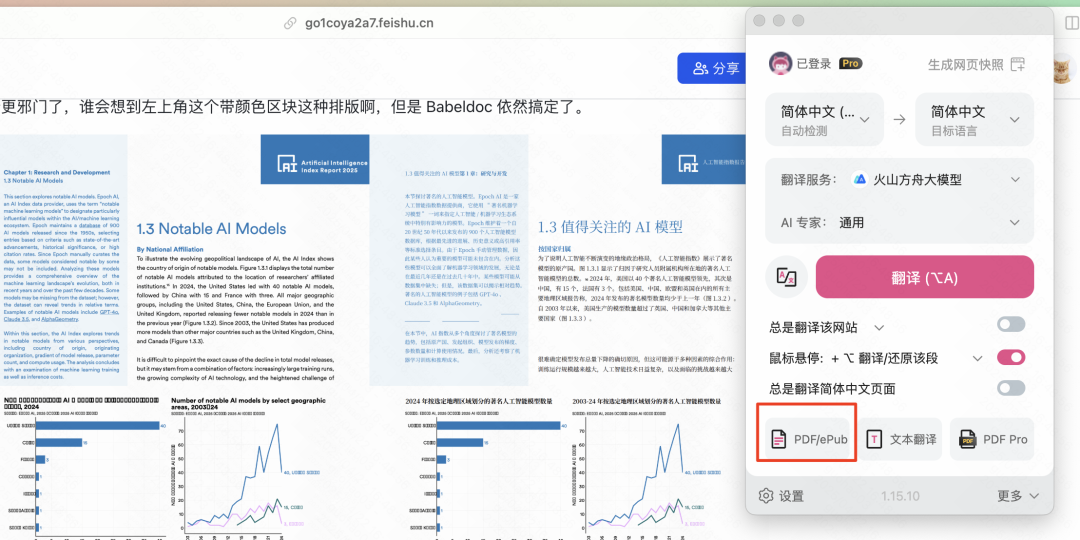
最后的终极考验是斯坦福 HAI 的 2025 年人工智能研究报告,这个 PDF 有456 页,而且内容极其复杂,各种图表、图片、标志、角标、多列排版,疑难杂症它全占了。
没想到这个转的非常完美,先看一下这一页,分割线、下划线加上标志,没啥问题,角标都给你翻译了。

这一页更是重量级,多列排版、图表、大段注释,整体依然翻译的很好,而且图表的主副标题都翻译了。
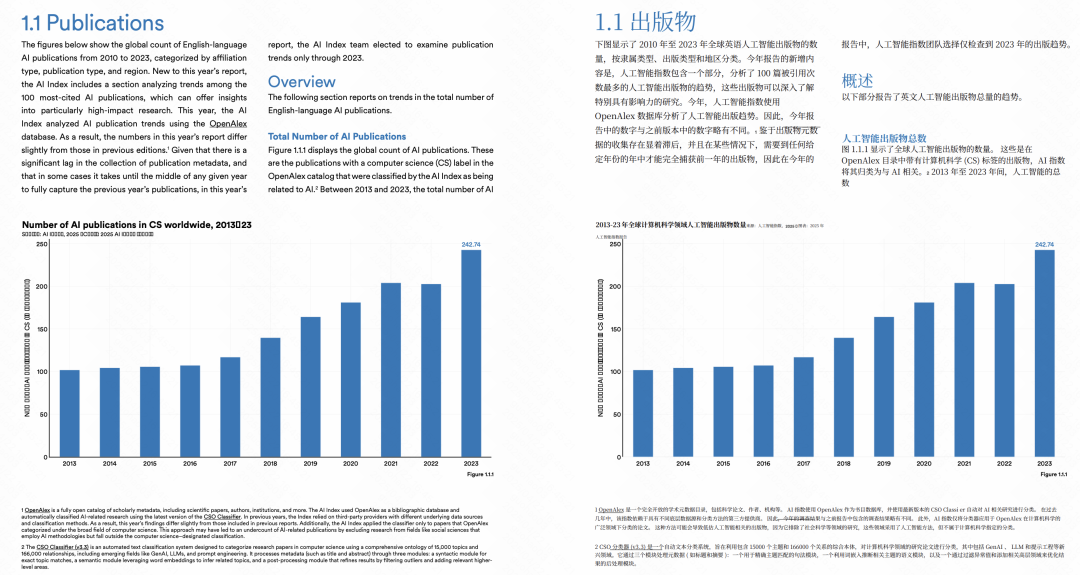
这个更邪门了,谁会想到左上角这个带颜色区块这种排版啊,但是 Babeldoc 依然搞定了。

那说了这么多如何使用呢,如果你有安装沉浸式翻译的话可以点击插件,然后点击图片里的 PDF/ePub 就可以进入文档翻译界面,进去以后选择 BabelDOC 就行,也可以直接访问:https://app.immersivetranslate.com/babel-doc/
看了一下介绍BabelDOC PDF 之所以能做到「翻译精准 + 版式还原」主要是有两步跟传统翻译不同的操作:
-
1. BabelDOC PDF 会先完整解析PDF结构,像“剥洋葱”一样识别出文字、图片、图表、公式等元素的布局关系,并将这些版面信息“记忆”下来,作为后续还原的参考。 -
2. 在完成结构识别之后在交给 AI 翻译时,BabelDOC PDF 会根据刚才“记忆”的布局信息智能匹配字体、字号、行距,确保翻译后的内容能「无缝替换」原文内容。 -
3. 最终,这一系列内容会通过 AI 排版引擎再次渲染生成一份新文档,格式与原始文档高度一致。
也就是说 BabelDOC 不是在简单的翻译文档,他是把所有内容解析出来以后重新为你参照原来的排版创建了一份新的文档。
当然延续沉浸式翻译的传统,这个产品依然是开源的(https://github.com/funstory-ai/BabelDOC),还登上了4 月 5 日Github Python 语言的第一。

BabelDOC 的套餐依然延续了沉浸式翻译的良心操作:
免费版⽤⼾每⽉享有 1000 ⻚ 的PDF解析翻译额度,并使⽤ GLM-4-FLASH ⼤模型进⾏翻译,我一个月都没这么多文档需要翻译的。
Pro 会员 则享有每⽉ 10000 ⻚ 额度,并接⼊ DeepSeek ⾼级翻译模型,带来更强⼤的翻译效果。
另外翻译好的谷歌提示词文档和斯坦福的人工智能指数报告可以在这里领取:https://pan.quark.cn/s/e5f5b4ac8147
(文:归藏的AI工具箱)
依然良心笑哭😂