

极市导读
面对从未见过的物体,也能精准完成抓取、开启等精细操作!让机器人学会“触类旁通” >>加入极市CV技术交流群,走在计算机视觉的最前沿
当人类第一次学会开启柜子后,即使面对构造迥异的微波炉门、冰箱门也能快速适应。这种与生俱来的”触类旁通”能力,如今在机器人领域取得突破。研究团队发现,人类与生俱来的”Affordance”认知(即理解物体的交互可能性)正是破解该难题的钥匙。由上海科技大学研究团队提出的AffordDP创新框架,让机器人首次展现出类似人类的环境适应能力——即使面对从未见过的物体,也能精准完成抓取、开启等精细操作。这项研究已被计算机视觉顶会CVPR 2025接收。

论文标题:AffordDP: Generalizable Diffusion Policy with Transferable Affordance
论文地址:arxiv.org/pdf/2412.03142
项目链接:afforddp.github.io
背景
基于扩散的策略在机器人操作任务中表现优异,但在处理域外分布时存在局限。近期研究通过改进视觉特征编码提升泛化能力,但通常仅限于相似外观的同一类别。为此,我们提出了AffordDP,利用可供性(affordances)增强对未见对象的泛化能力。通过3D接触点和轨迹建模可供性,结合视觉模型和点云配准实现跨类别泛化,并在扩散采样中引入可供性引导优化动作生成。仿真和真实环境中的实验结果表明,AffordDP在性能上持续优于以往的基于扩散的方法,并成功泛化到其他方法无法处理的未见实例和类别。
研究动机
近年来,基于扩散模型(diffusion-based)的模仿学习在灵活性和多样性上展现了巨大潜力,但在面对域外分布场景时,仍普遍缺乏足够的泛化能力,难以适应未知物体的不同形态或类别。相比之下,人类能轻松将所学技能迁移到外观和类别不同的目标上,其关键在于对“在哪里”以及“如何”与物体交互的先验认知,即可概括为“Affordance”。然而,现有研究大多只在带轨迹的二维接触点、关键帧或价值图等较为局限的层面利用了Affordance,难以涵盖交互中的动态变化。为克服现有扩散模型在泛化方面的不足,引入包含静态和动态信息的通用Affordance表征至扩散策略,并在采样过程中对其进行精细化指导,不仅能有效迁移交互先验知识,也可进一步拓展扩散模型在未知物体及新类别场景下的机器人模仿学习应用。
方法介绍
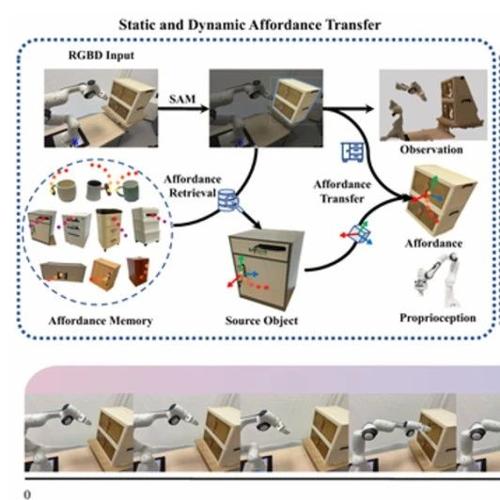
静态与动态affordance迁移
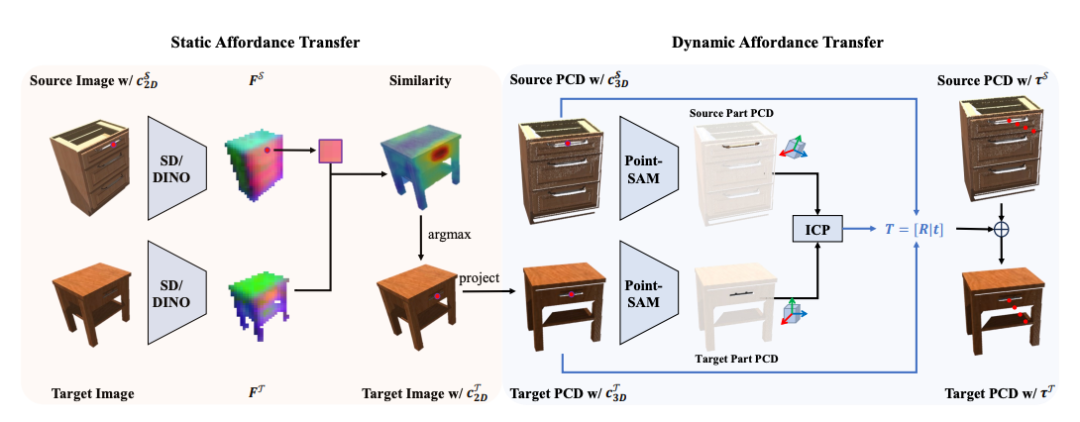
我们的方法核心在于利用静态和动态Affordance(接触点与接触后的三维轨迹)来实现对未知物体的迁移操作。为此,我们首先构建了一个“Affordance记忆库”,存储每个示例的外观特征、三维点云以及对应的Affordance。在推理时,我们从记忆库中检索出与目标任务最相似的“源物体”,并将其静态和动态Affordance分别转移到“目标物体”上:
-
静态Affordance转移:通过像素级语义匹配,将源物体的接触点从图像空间映射到目标物体图像中对应的区域,再投影回三维世界坐标系,得到目标物体上的三维接触点(静态Affordance)。
-
动态Affordance转移:利用源、目标物体的三维点云,通过对可交互部分的分割与ICP算法获取两者间的旋转矩阵,并结合前一步计算的平移向量,构造6D变换矩阵,最终将源物体的后接触轨迹(动态Affordance)精确地转移到目标物体上。
通过静态和动态Affordance的联合转移,我们能够在不同外观、形状乃至类别的物体之间完成精准的操作知识迁移,为后续的扩散式模仿学习提供可行且通用的先验。
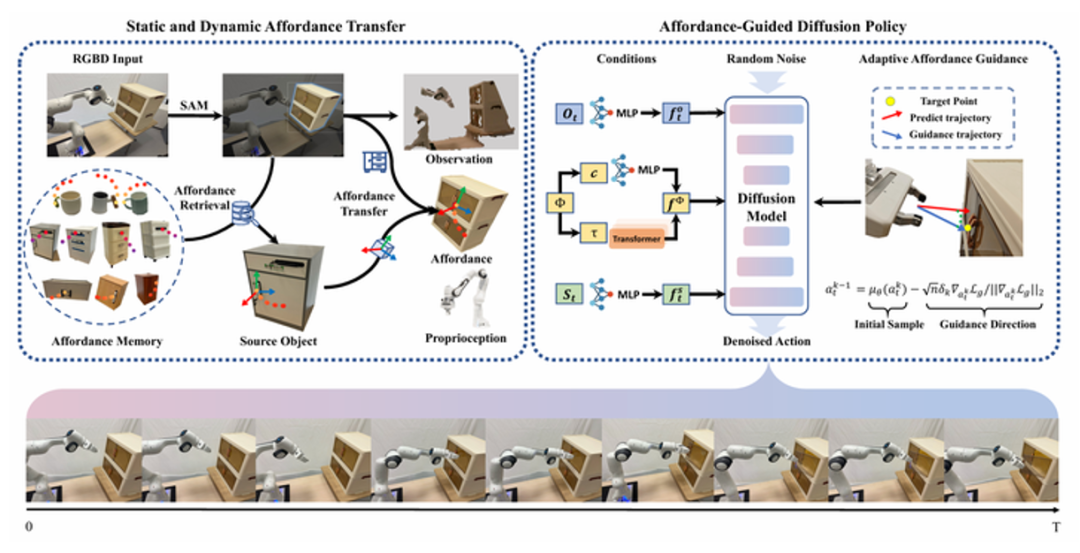
基于affordance的扩散策略
我们的方法在标准扩散式策略网络的基础上,显式地融入静态和动态Affordance信息,并在采样阶段施加自适应引导,实现对未知物体高精度的交互控制。具体地说:
1.多模态条件输入:网络将场景点云 (仅保留与目标物体和机械臂附近的区域),机械臂自身的关节状态 以及静态与动态 Affordance (接触点与后接触轨迹)共同作为条件,经过 MLP 或 Transformer 等编码器提取特征,合并为一个综合条件向量
2.扩散模型训练:利用DDIM进行条件扩散,逐步对初始高斯噪声向量去噪。网络核心是一个噪声预测子,通过最小化预测噪声与真实噪声的均方误差,实现对条件分布下的动作空间建模。
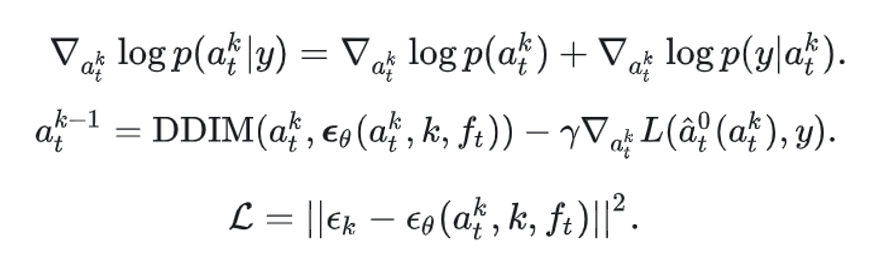
3.自适应Affordance引导:在推理(采样)时,为了让生成的动作序列既遵循全局的可行分布,又能快速收敛到目标接触点,我们在扩散的每次去噪迭代后,计算机械臂末端与静态Affordance接触点的距离,并在距离阈值内才施加基于梯度下降的引导修正,从而保证在关键阶段对末端进行精细控制,且能保持在可行动作流形之内。
-
从Bayes视角看,若我们希望在采样时“额外”满足某种约束或条件,例如“末端执行器应靠近指定的接触点”,那么可以在标准扩散目标中引入新的似然项,其中表示该额外条件。可以表示为如下对数形式:
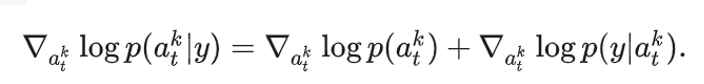 这意味着我们要在原本的扩散采样(对应log〖p(a_t^k)〗)基础上,增加对额外条件log〖p(y|a_t^k)〗的梯度引导,从而让生成的动作序列满足特定的要求。
这意味着我们要在原本的扩散采样(对应log〖p(a_t^k)〗)基础上,增加对额外条件log〖p(y|a_t^k)〗的梯度引导,从而让生成的动作序列满足特定的要求。 -
为了不再额外训练一个"鉴别器"或"分类器"来估计 的对数似然,我们将其替换为一个可微的损失函数 。这样在采样时,只需对该损失函数做梯度下降即可引导动作生成。于是,可写为:

-
具体地,我们设计了如下的损失函数
-
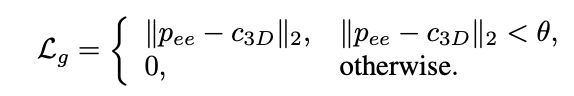
只有当夹爪末端到目标接触点的距离小于一个预先定义的阈值时才激活损失,避免在无意义的位置过度修正或打破合理的动作流形。
-
在实现上,我们参考DSG[39]方法中的做法,将梯度引导融合到DDIM的去噪更新中去:
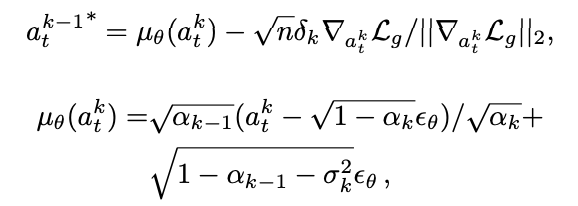
综上,我们在DDIM采样各步引入“末端–接触点距离”的梯度,引导生成的动作序列更严格地对齐关键接触点,从而在可能的动作分布中,倾向产生更高精度的操作动作。通过这种自适应的Affordance引导机制,模型不仅能保证对大规模行为分布的有效建模,还能在需要精细操控的场景(如未知物体的抓取或开关等)中更好地对齐关键接触点,提升泛化性与成功率。
实验
在这一部分我们将介绍我们的实验结果,在项目主页展示有仿真和真机实验的视频。
仿真实验
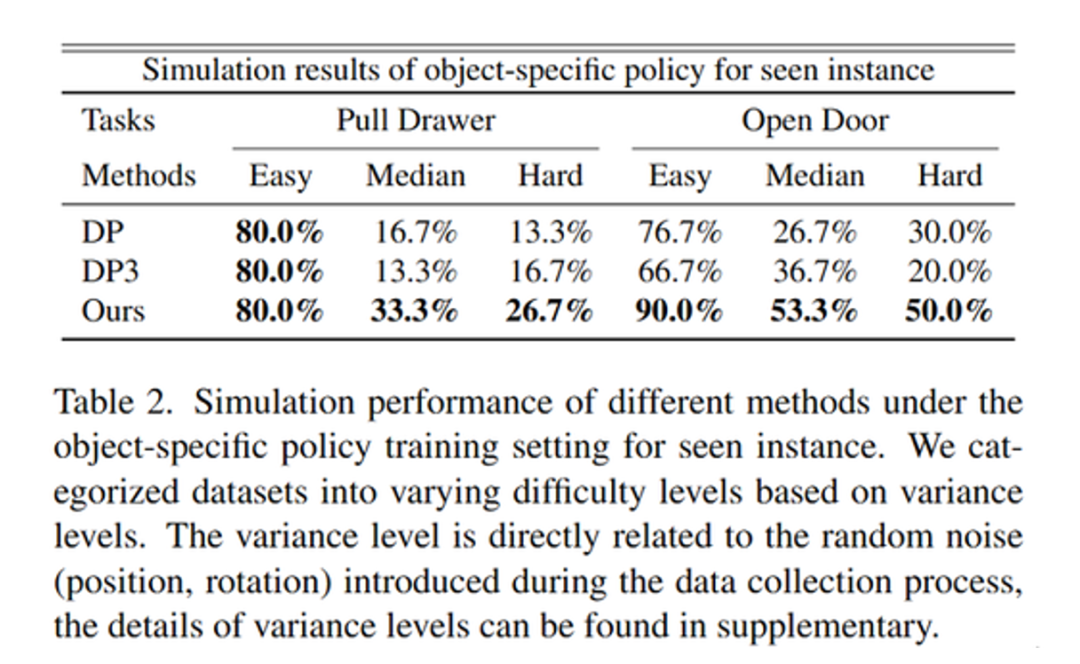
在仿真实验中,我们选取了OpenDoor和PullDrawer两个任务,并在IsaacGym中开展了实验。
现有的扩散式策略如 DP[6] 和 DP3[41]均采用针对单一物体的训练方式,只在训练阶段引入一个目标物体。虽然这种设置能让模型充分学习该物体的特定特征,但往往难以泛化到具有差异化外观或形状的未知物体上。为提升在多种场景中的适用性,我们设计了两种训练方式:(1)单物体策略训练,保持 DP、DP3 等方法的单一物体训练模式;(2)统一策略训练,在同一网络中引入多物体数据进行联合训练,从而迫使策略学习更具有普适性的任务相关特征,获得更强的跨物体泛化能力。
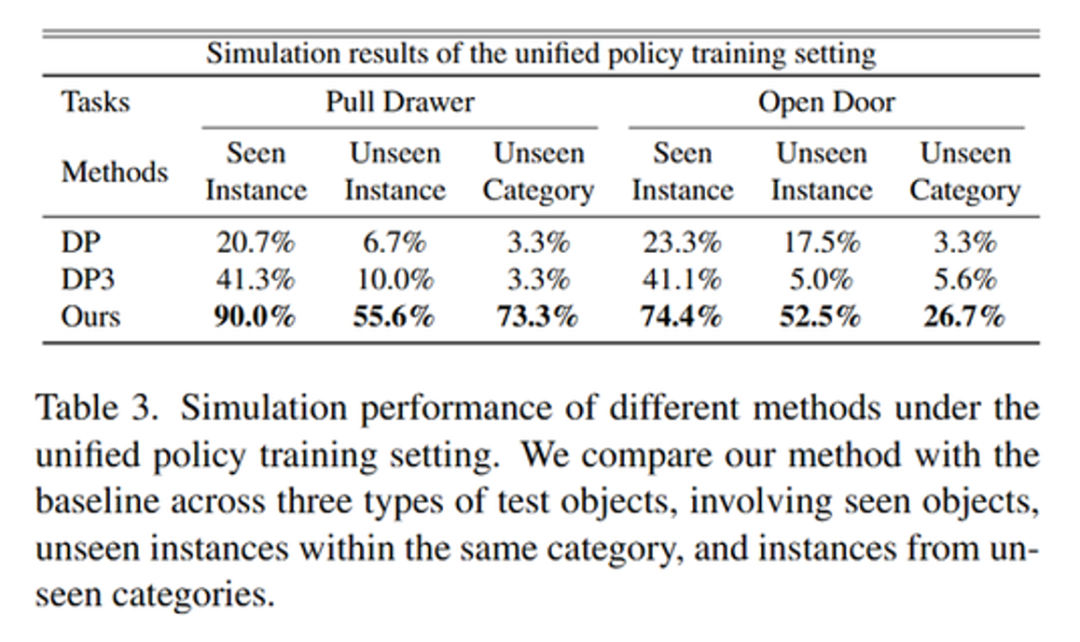
真机实验
真机实验包含三个任务:OpenDoor,PullDrawer和Pick&Place,并使用了统一策略训练的设置进行测试。
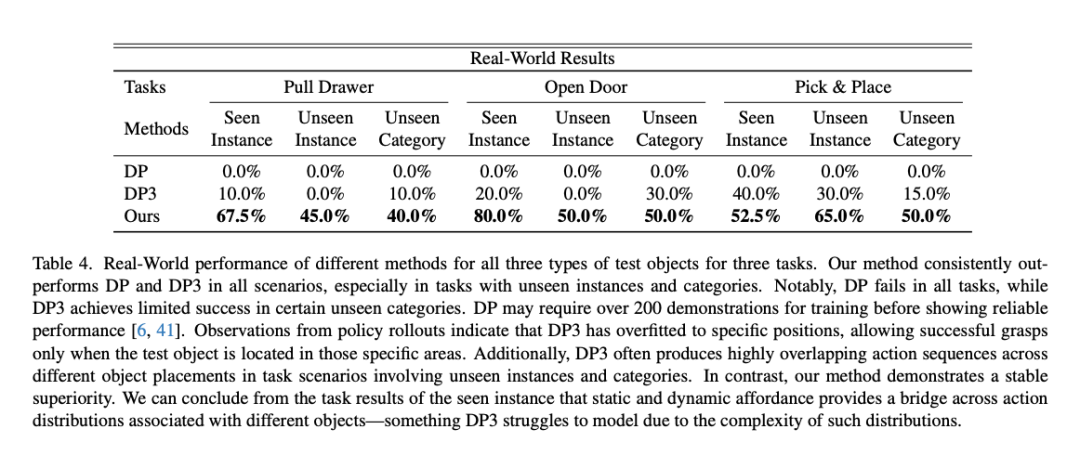
由于DP缺少对空间的感知和对大量数据的依赖,它在我们的实验中基本无法有效完成任务,而DP3由于缺乏Affordance的信息,无法准确地抓住目标物体(如细小把手)。与它们相比,我们的方法可以有效地抓住目标物体并完成任务,并成功泛化到其他方法无法处理的未见实例和类别。

消融实验
为了更进一步验证文中所提方法的有效性,我们进行了多项消融实验。
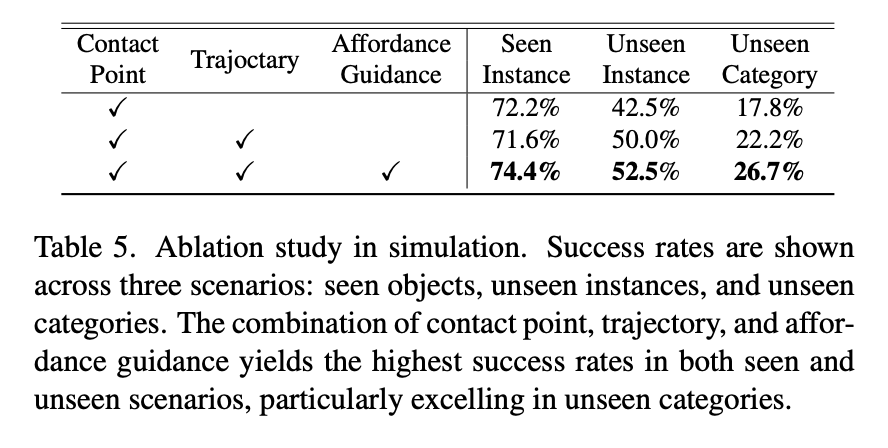
结论
我们创新性地将可供性概念与扩散策略相结合,通过视觉基础模型强大的语义理解能力,实现了对未知物体的操作知识迁移。实验表明,AffordDP方法在仿真和真实环境测试中都展现出优异的性能表现,特别是在面对新物体时的适应能力显著优于现有方法。展望未来,我们将持续优化算法,致力于开发更具普适性的模仿学习框架,让机器人能够更好地应对现实世界中复杂多变的任务需求。

(文:极市干货)