


身处 AI 时代,不管是埋头求知的大学生,还是紧跟热点的打工人,都必须面对一项棘手的挑战:如何拨开信息迷雾,高效获取有价值的内容?
今天,OpenBMB 开源社区请了一位资深专家——人送外号「卷姬」!
在目前长文本生成领域,卷姬是当之无愧的「卷王」。她左手信息熵,右手卷积算法,轻轻松松将文献沼泽「卷」成 3 分钟速通,还能整合出漂亮又高质的综述内容!话不多说,掌声有请👏

新人报道:卷姬 SurveyGO
大佬们好,我叫 SurveyGO,大家也可以叫我卷姬,今天正式入职 OpenBMB 开源社区。
作为一名把 INTJ 特质刻进灵魂的职场新人,我高效、冷静、理性,擅长用学术手术刀剖开文献迷障,专治各种论文难产、调研头秃、DDL 前哭爹喊娘的症状。
如果你有过以下惨痛经历:
✅ 吭哧吭哧肝了 200 小时文献综述,疯狂 Ctrl+C 和 Ctrl+V,最后导师却说「你这引用质量和百度百科有什么区别?」
✅ 被老板临时需求追杀到凌晨五点,打开 82 个网页看到眼冒金星,结果项目报告里的关键数据居然来自知乎匿名编故事大佬
✅ 每次查资料都像在垃圾场淘金,明明要找「量子计算」,为你推荐却总跳出《重生之我在缅北做算法》……
恭喜,我就是来拯救你的发际线的。
OpenBMB 的前辈们各有所长,但在搞掂综述调研这块,我有着绝对优势。再小众晦涩的领域,只要告诉我关键词,我会快速在海量论文中筛掉灌水资料,把核心文献拧成知识脉络,最后生成有深度、有逻辑、有洞见的综述内容。
东拼西凑?不存在的。再来几百篇万字长文,我也能超高速消化理解再输出,完全没在怕。
我相信,所有能用算法暴打的低效环节都不应浪费脑细胞。我承诺,入职 OpenBMB 开源社区后,将让信息获取效率「卷」出新高度,让僵化的综述焕发出生命力,把睡眠和头发还给人类,把时间还给真正重要的创新思考。
本人 SurveyGO,aka 卷姬,已准备就绪接管你的调研灾难现场。
1. 打开网址 https://surveygo.thunlp.org/,点击「开始综述」。
2. 两种模式任你选择:
【普通模式】输出标题和关键词描述,提交并等待生成。
【专业模式】可进一步自定义素材来源,选择「在线检索」或「上传文件」。为保护 SurveyGO 用户隐私,基于上传文件所生成的文章及上传的文件,可设置不公开。

3. 再次登入网址,你的综述报告已准备就绪!
4. 彩蛋玩法:点进首页的「写作需求表」,围观大家风格各异的好奇心,为你感兴趣的研究点赞!

你已被选为 SurveyGO 首批测试员!速来,跟群里大佬们一起聊聊吧!

横评大乱斗:因为够「卷」,所以优秀
读 AI 生成的报告时,你能分辨出它是「有框架支撑的逻辑」还是「流水账式的拼凑」吗?
最近,特朗普政府发起的关税大战沸沸扬扬。我们让卷姬 SurveyGO、OpenAI-DeepResearch、AutoGLM-沉思和 Gemini DeepResearch 分别以《关税大战对普通人生活的影响》为题,撰写一篇详尽的综述报告。
一篇好的报告可以从 4 个科学维度考量,我们将以这些维度进行横评:
1. 结构维度:结构清晰合理
2. 内容维度:论据有支撑、内容和主题相关、语言风格良好、有拓展延伸的思考
3. 观点维度:具有信息量的观点的数量和密度
4. 引用维度:引用文献的准确率和召回率
从结构维度看,SurveyGO 生成文章的目录层次分明。OpenAI DeepResearch 的目录结构较为简单,虽然切题,但没有展现出很好的层级或者递进关系。AutoGLM-沉思的标题层级更接近对现有信息的分点罗列,缺乏整合与深度思考。而 Gemini DeepResearch 的目录分点切题,但结构存在冗余,例如 3、4、5、6可以归类为 1 到 2 个章节。

至于内容维度,从导言和结论基本可见分晓。
SurveyGO 的导言部分从历史开始说起,逐渐切入时事,娓娓道来,是一个很有深度的分析,结论分析更见功力,角度全面,思维缜密。
OpenAI DeepResearch 的导言部分有背景介绍和核心关注点,具备一定「透过现象看本质」的特征,而结论部分的递进关系写得较好,文采不错,有升华主旨。
AutoGLM-沉思的概况能准确捕捉热点新闻信息,真实性可供验证,但概括性不足,无法让人从宏观视角理解全局事件,结论部分以小及大,逻辑清晰。
Gemini DeepResearch 的导言结构清晰,思路明确,解释了关税定义、运作方式和关税大战触发因素等,有助于读者了解事件背景,结论部分偏向简单整合,有一定提高空间。

接下来是观点维度和引用维度,主要选取正文段落分析。
SurveyGO 将内容整合为机遇、挑战与应对策略 3 方面,详细论述了不同国家受到关税冲击下的影响,并辅以合理的引用支持,观点有理有据。
OpenAI DeepResearch 对于观点的支撑性论据更倾向于简单罗列,缺少对现有大量事实的整合,部分断言论据只有寥寥几篇文献。
AutoGLM-沉思的内容细节上分点过于零碎,每一个小点只有少部分论据支撑,导致内容较为破碎。
Gemini DeepResearch 会搜索很多网页,正文的表格较亮眼,能综合很多信息,但信息不够具体,例如没有指定地点、时间段、信息来源等,另外也存在大部分篇幅简单罗列事实的问题,缺乏选择性整合与批判性思考。


去年 9 月,面壁小钢炮 MiniCPM 3.0 的「无限长文本」让人眼前一亮。背后的技术原理 LLMxMapReduce 长本文分帧处理技术堪称「大模型长文本上分神器」,我们也曾撰文分享过:
▲ 点击图片,跳转回顾
今天,让 SurveyGO 成为新晋「卷王」的 LLMxMapReduce-V2 长文本整合生成技术,正是它的进化版本。
为了进一步提升⼤语⾔模型长文本生成的内容质量,AI9Stars、OpenBMB、清华大学的小伙伴们联合研发,提出 LLMxMapReduce-V2。这项技术的核⼼在于借助⽂本卷积算法实现多篇参考⽂献的聚合来代替现有⽅法中常⻅的检索,从⽽实现对全部参考⽂章的充分利⽤。

实验数据显示,LLMxMapReduce-V2 在参考利⽤率上至少提⾼了 32.9%,在其他维度的表现也显著优于提取式基线⽅法。
论文链接:
https://arxiv.org/abs/2504.05732
Github 链接:
https://github.com/thunlp/LLMxMapReduce/tree/main
面对超出大语言模型上下文长度的超长素材,传统⽅法会采⽤提取技术来压缩资源。目前最常⻅的是使⽤检索增强生成(RAG),根据用户查询信息来识别最相关的⽂本块。这种方法快准狠,但容易碎片化缺乏逻辑连贯,可能会漏掉不直接相关但重要的内容,最终影响生成文章的质量。
打个比方,RAG 就像一个人用吸管喝奶茶,只吸到珍珠和奶茶,却忽略了杯底的布丁和椰果。
而 LLMxMapReduce-V2 则切换了另一种思路,选择采用整合式方法,通过综合更⼴泛的信息,挖掘不同内容之间的潜在联系,实现更全⾯、有深度的⽂本表达。这种方法仿佛厨师做佛跳墙,融合鲍鱼、海参、花菇等多种食材,熬出层次丰富的汤底,争取每一滴都不浪费。
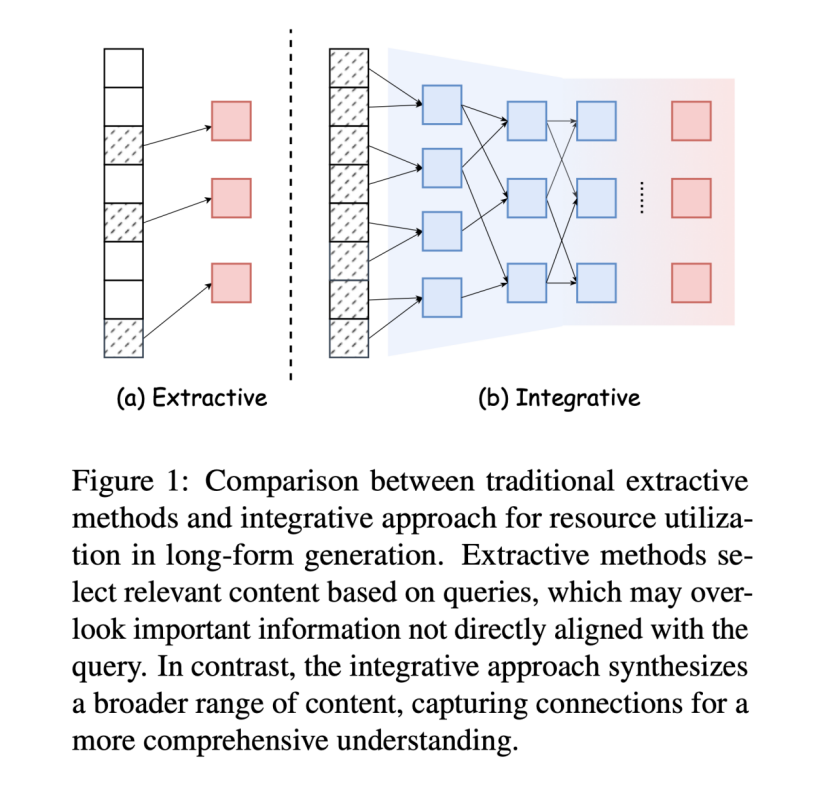
想得挺美,但当眼前是几百篇万字长文超长输入,LLMxMapReduce-V2 如何能做到又快又好?
研究团队找到了答案:一种由信息熵驱动的随机卷积测试时缩放⽅法。这种⽅法借鉴了经典卷积神经⽹络的原理,同时引⼊信息熵估计模块⽤于指导卷积过程,确保测试时缩放过程能够不断提升结果的信息含量。
卷积神经网络(CNN)常用于图像理解,可以通过多层卷积操作,逐步从局部信息中提取更高级别的全局特征——就好比我们在看一幅画,刚开始只能看到画中一片树叶,但随着卷积层的增加,我们慢慢看到整棵树,甚至整个森林。

当用于长文本处理时,卷积神经网络首先会关注部分引用文章,再通过多层卷积操作,逐渐将局部信息整合成更全面的结构化信息(比如文章的段落结构、主题等),能帮助 LLMxMapReduce-V2 更好地把握文章的整体逻辑和内容,提高信息密度。
至于这里的信息熵,可以理解为信息的「丰富度」或「有用性」。通过计算信息熵来评估每一步卷积操作的效果,能让 LLMxMapReduce-V2 更好地保留这些看似不直接相关但实际很重要的细节,从而生成更全面、更深入的文章。

OK,差不多了,现在让我们走进 LLMxMapReduce-V2 的「信息手术室」看看吧。
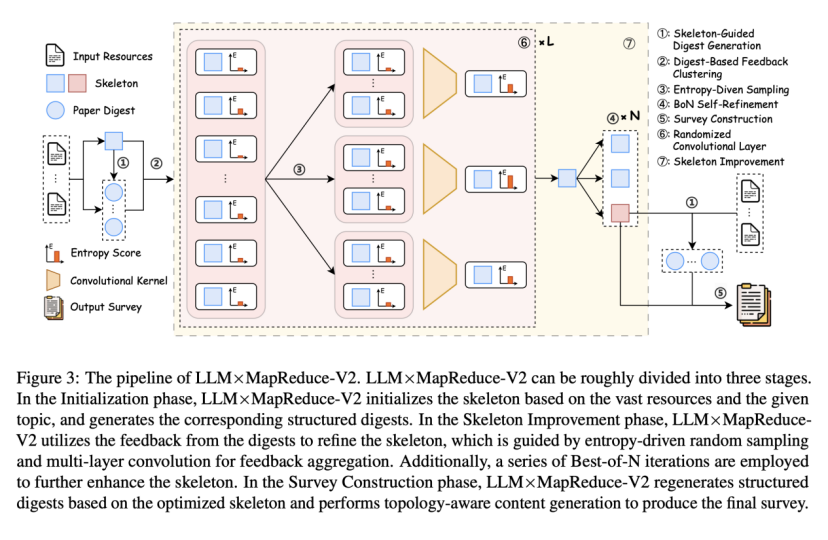
LLMxMapReduce-V2 的工作流程可以大致分为三个阶段:
第 1 阶段:初始化(Initialization),做好准备!
信息瓶颈理论指出,中间表示在长文本生成过程中起关键作用,增强中间元素的信息丰富度并充分利⽤,可提⾼最终输出内容的质量下限。为此,研究⼈员引⼊了框架(skeleton)和摘要(digests)的概念。
万事开头难,而 LLMxMapReduce-V2 不慌不忙。输入海量资料和信息主题后,LLMxMapReduce-V2 会速读资料,初步搭建相应框架(类似论文目录),同时为每篇论文提炼核心观点,生成结构化摘要。
如果用做小笼包来打个比方,这个便是原料初处理环节。LLMxMapReduce-V2 如同老师傅一般动作娴熟,先将面粉分组,揉成面团待用,猪肉按肥瘦比切成不同类别(比如 3:7 爆汁款、5:5 弹牙款),并制定出《初版包子 SOP》。
第 2 阶段:框架优化(Skeleton Improvement),卷起来吧!
在这一阶段,LLMxMapReduce-V2 发起了一轮又一轮信息大乱斗!
根据论文摘要的反馈,LLM×MapReduce-V2 将相似的内容分组聚合,以信息丰富度和有用性作为评分标准来筛选关键反馈,再通过多层随机卷积,逐步聚合局部反馈为全局优化策略,让框架越来越清晰准确。最后结合 Best-of-N ⾃优化机制生成多个增强版本,并选择其中最全面的框架。
研究团队发现,当卷积层数为 7 层、卷积核宽度为 3、⾃优化迭代 3 次时, LLMxMapReduce-V2 性能达到最佳状态。
再次用做包子来比喻,这就像是 LLM×MapReduce-V2 带领后厨发起了激动人心的小笼包争霸赛!先是学徒试做反馈几种配方口感(比如肥瘦5:5的肉馅偏柴),再用「汤汁鲜度检测仪」(信息熵)抽样打分,层层淘汰,只保留高分配方。最后再用猛火/中火/小火三种不同火候试做,选出汤汁最饱满的一锅胜出。卷,实在是太卷了!
第 3 阶段:综述构建(Survey Construction),大功告成!
胜利的曙光就在眼前!基于优化后的框架,LLM×MapReduce-V2 重新生成结构化摘要,按层级逐部分生成内容(先写章节标题,再填段落),父章节也会综合子章节内容,确保全局逻辑连贯,最终输出结构完整、引用精准的学术综述。
此时此刻的后厨,《终版包子SOP》已优化生成,后厨有条不紊地按肥瘦比剁馅,按 18 个褶子捏好,每笼摆 8 个,最上层撒菊花瓣,底层垫粽叶防粘,开火放蒸笼……每个动作误差小于 0.1mm,只为迎接最美味的小笼包出炉!

为了科学评估 LLMxMapReduce-V2 相较于传统提取式⽅法的优势,研究团队开发了⾼质量的综述写作基准 SurveyEval。这是计算机科学领域⾸个将综述与完整参考⽂献相结合的可扩展评估基准。
研究⼈员选取了三个具有代表性的基线⽅法与 LLMxMapReduce-V2 进⾏对⽐,所有基线方法均采用 Gemini-Flash-Thinking 为基础进行生成,且 LLMxMapReduce-V2 和模型是解耦的,也可以基于其他模型进行综述生成。
实验结果表明,LLMxMapReduce-V2 在 SurveyEval 基准测试中表现卓越,在多个关键指标上优于提取式基线⽅法。其中,所有基线方法均采用Gemini-Flash-Thinking为基础进行生成。而且LLMxMapReduce-V2和模型是解耦的,也可以基于其他模型进行综述生成。
尤其在参考⽂献指标上,LLMxMapReduce-V2 的精确率达到 95.50,召回率为 95.80,均为最⾼值,与其他基线⽅法拉开了较⼤差距。这表明 LLMxMapReduce-V2 在利⽤⼤量参考⽂献⽅⾯具有强⼤的能⼒,在处理需要整合⼤规模资源信息的任务时优势明显。

综上所述,LLMxMapReduce-V2 在实验中展现出了卓越的性能,在处理超⻓输⼊和⽣成⾼质量⻓⽂⽅⾯表现出⾊,未来在更多应⽤场景中的拓展潜⼒巨⼤。期待 LLMxMapReduce-V2 在后续研究中取得更多突破,为⻓⽂本⽣成领域「卷」出新的发展!
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

(文:PaperWeekly)