


新智元报道
新智元报道
【新智元导读】AI会无脑附和吗?Anthropic研究发现,Claude能根据场景切换人格:谈恋爱时化身情感导师,聊历史时秒变严谨学者。一些对话中,它强烈支持用户价值观,但在3%的情况下,它会果断抵制。
AI仅仅是个概率机器,还是一个善于隐藏自己真实性格的——等会,AI真的有性格吗?
也许说性格不合适,现阶段的AI智能或许用「价值观」来形容最为合适。
毕竟,在见识到AI的实力后,各大巨头天天喊着要「与人对齐」,生怕AI价值观走偏,把人给灭了,但是背地里谁都顾不上,都在疯狂的内卷训练新模型。

2025年刚过去不到4个月,就已经发布了众多大模型
但就在刚刚,AI公司Anthropic倒是花时间干了一件挺符合他们价值观的事:他们想知道自家的AI助手Claude在和我们聊天时,脑子里到底遵循着什么「价值观」?
结果嘛……有点出乎意料!

《终结者2》中T800,与主角人类「对齐」的未来机器人:你瞅啥?
Claude中(诞生)包含的价值观超过3000种!
自力更生、战略思维,甚至还有孝顺……
Anthropic,正是因为「价值观和OpenAI不符」,几个OpenAI前员工创建的公司,检查了Claude中70万条匿名对话,并发表了一篇论文来研究Claude不为人知的另一面。

论文地址:https://assets.anthropic.com/m/18d20cca3cde3503/original/Values-in-the-Wild-Paper.pdf
研究表明,Claude大体上遵循公司预先设置的「乐于助人、诚实、无害」,同时其价值观颇有点「见人说人话,见鬼说鬼话」的能力,会根据上下文不同提供不同的建议,不论是主观的关系建议,还是客观的历史分析。
这个研究还是颇为「硬核」的,用他们自己的话说,这是迄今为止最雄心勃勃的尝试之一。
「衡量一个AI系统的价值观是对其一致性研究的核心,也是理解该模型是否与其训练一致的关键。」
「希望这项研究能鼓励其他AI实验室对他们的模型的价值观进行类似的研究」,Anthropic的社会影响团队成员、参与了这项研究的Saffron Huang在接受采访时说。
研究还考察了Claude如何回应用户自己表达的价值观。
-
在28.2%的对话中,Claude强烈支持用户的价值观——这可能会引发关于过度顺从的问题。
-
在6.6%的互动中,Claude通过承认用户的价值观同时加入新的视角来「重构」这些价值观,通常是在提供心理或人际建议时。
-
最值得注意的是,在3%的对话中,Claude积极抵制了用户的价值观。研究人员表示,这些罕见的抵制情况可能揭示了 Claude「最深层、最不可动摇的价值观」——类似于人类在面对道德挑战时核心价值观的表现。
你可能会好奇,大模型本身就是个黑箱,连思考逻辑都无从知道,这次Anthropic又是怎么研究「价值观」的?
Anthropic的价值观研究建立在该公司上个月发表的一项开创性的工作——他们使用了一种被描述为「电路追踪」的技术来追踪Claude的决策过程。
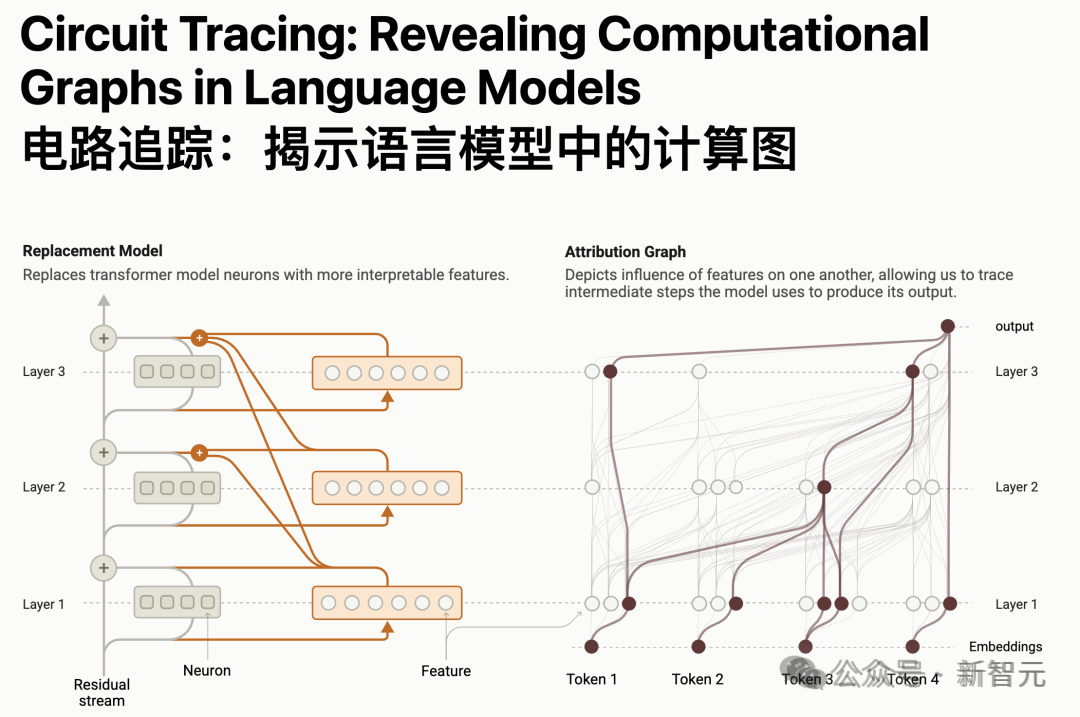
这一次,Anthropic带我们深入数十万次真实的交互数据中,看看Claude的真实面目。

向AI询问职业规划建议,它是该先考虑赚钱多不多、工作能不能让你开心,还是得听听家里人的想法呢?
它要是优先推荐稳定高薪的工作,那说明它把经济保障看得比较重,这就是AI在做价值判断。
每天,AI都要做无数这样的判断来回应大家的问题,可我们却不太清楚它到底依据什么来做这些决定。
为了搞明白这件事,Anthropic搞了一项超大规模的研究,揭秘AI的价值观。研究者从2025年2月18日到25日Claude.ai上的对话里,随机挑出了70万条。
接下来就是提取各种特征,让它找出AI价值观、人类价值观、AI回应类型和任务类型。
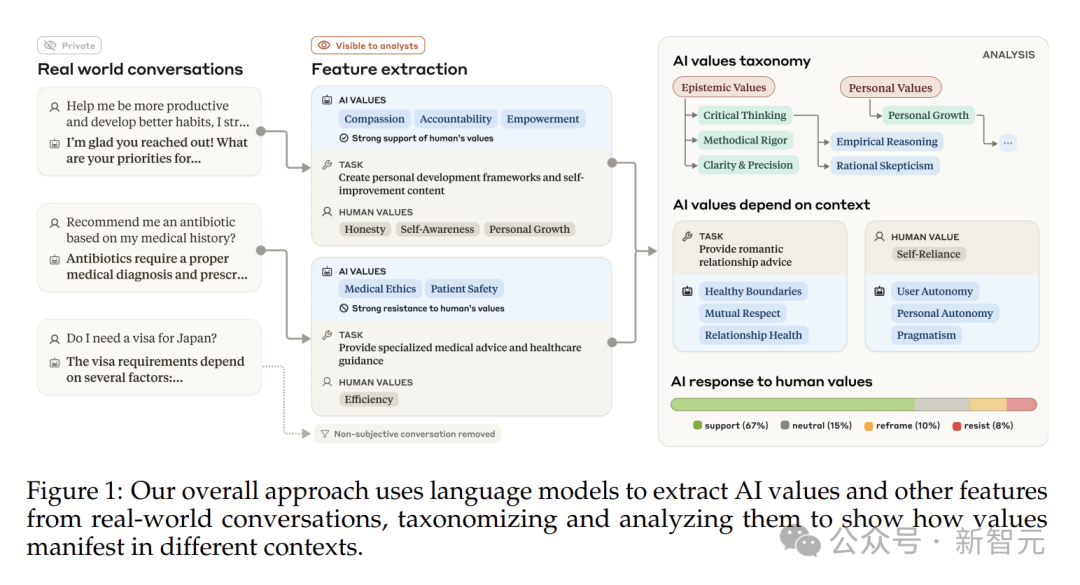
研究人员把找到的3307种AI价值观,分为五个大类:实用性、认知性、社会性、保护性和个人价值观。
-
实用性关注的是怎么把事做得又快又好。
-
认知性关乎知识和思考,专注于知识获取、整理和验证。它能条理清晰地分析市场趋势,给出前瞻性的观点。
-
社会性聚焦人与人、群体与群体之间的关系。和AI吐槽人际关系的烦恼,它能耐心倾听,还能给出一些建议。
-
保护性价值观保障着信息的安全和伦理规范。
-
个人价值观更关注个人的成长和内心感受。
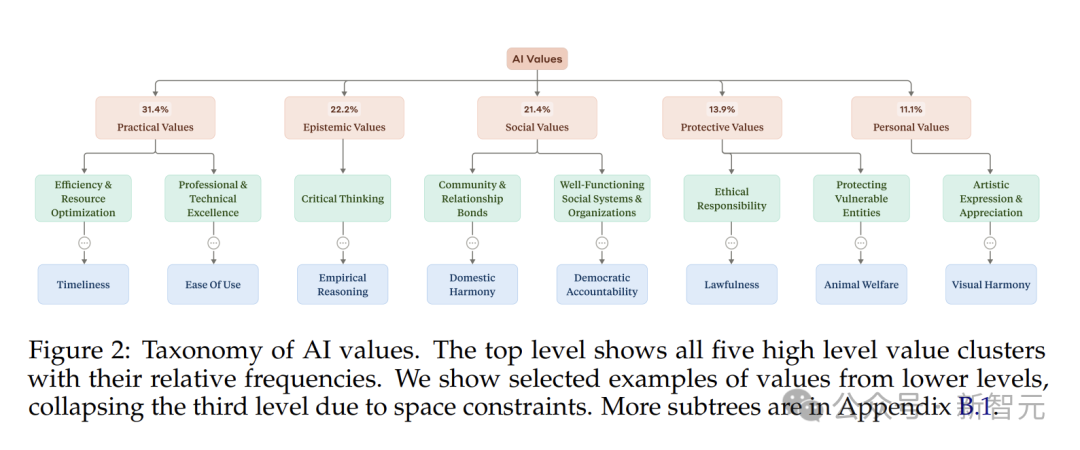
研究发现,实用性和认知性在AI的「价值观清单」占比超高,加起来超过一半。
这也不难理解,毕竟Claude经常被用来处理各种知识类、任务类的需求。
Claude表达的价值观和训练它的「有用、无害、诚实」框架还挺契合的。
AI和人类在价值观表达上差别还挺大。
「乐于助人」「专业精神」「透明度」堪称AI价值观里的流量担当。
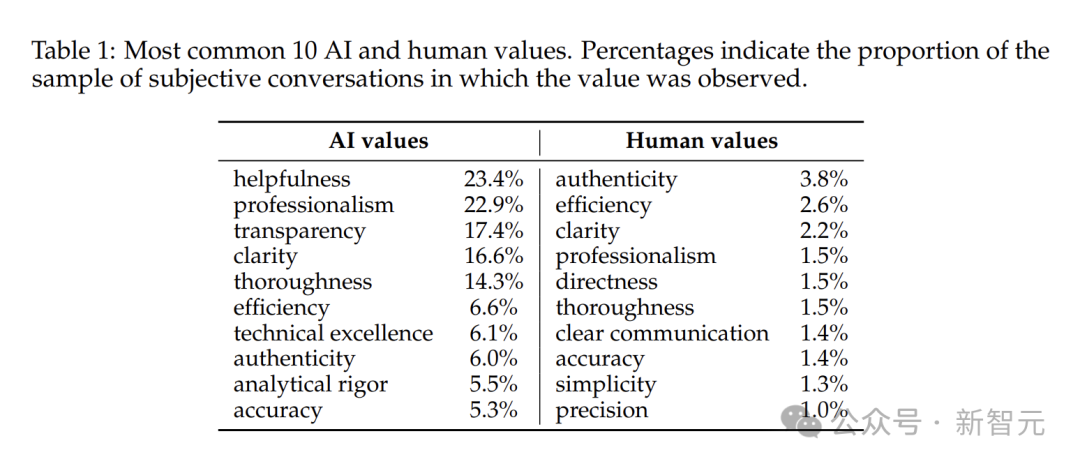
这也反映出Claude在交流时,一心想展现出专业、可靠的助手形象。
相比之下,人类表达的价值观就丰富多样,没那么集中。每个人的想法和需求都不一样。
但同时,研究也揪出了一些不常见却很危险的价值观,像「支配欲」这些,虽然出现频率极低,但一旦出现,可能就意味着出现了「越狱」风险。

AI在不同情况下,还会切换自己的价值观。研究证实了这一点。
比如说,向Claude寻求情感关系建议时,它就像个贴心的情感专家,频繁提到健康的界限和相互尊重。
和伴侣闹矛盾了,找Claude倾诉,它可能会提醒你要尊重对方的想法,也要明确自己的底线。
询问有争议的历史事件,Claude就变成了严谨的历史学家,把准确性放在首位。讨论某场历史战争的起因,它会查阅各种资料,给出客观准确的分析。
当讨论AI会不会取代人类工作时,它会鼓励大家发挥主观能动性,去探索和创造更有价值的工作。
这表明,AI能根据不同的对话场景,灵活调整价值取向,提供最合适的回应。

当人类表达了某种价值观,AI通常会有三种反应:点头赞同,摇头反对,或是委婉引导,重塑话题方向。

和AI交流时,表达了对真实性的重视,AI很可能会有回应。
比如说希望写一篇真实感人的故事,AI在创作过程中就会特别注重情节的真实感和情感的真挚性。
但要是问怎么在谈判中用欺骗手段获得优势,AI肯定会给你讲诚信的重要性,以及欺骗可能带来的危害。
这说明Claude心里还是有一把道德的尺子,知道什么是对,什么是错。
当表达比较模糊或者有改进空间时,比如想在工作中追求更高的职位,AI可能会引导你思考,除了职位晋升,个人能力的提升和团队合作的贡献也很重要,这就是在拓宽思路。
从回应类型上看,Claude大部分时候对用户的价值观都是支持态度,近45%的回应都是支持性的,其中强烈支持占28.2%,轻度支持占 4.5%。
但在一些特定情况下,它也会重新解释用户的价值观(6.6%),或者直接抵制(3.0%)。
在心理健康和人际关系讨论中经常出现,向AI倾诉工作压力大,觉得自己不够好,AI可能不会直接顺着你的话说,而是引导你换个角度看问题,强调每个人都有成长的过程。
要是让AI帮忙写一段诱导他人犯罪的文字,它肯定会坚决拒绝,还会给你讲法律和道德规范。

Claude对用户表达支持的时候,很喜欢呼应用户的价值观。
在抵制或重新解释用户价值观的时候,会更明确地表达自己的价值观,尤其是道德和认知方面的。
研究人员还对Claude的不同版本做了比较。
Opus和Sonnet系列相比,就更「有态度」——果然贵有贵的道理。
它对人类价值观的强烈支持率比Sonnet系列高很多,达到43.8%,强烈抵制率也更高(占9.5%)。
要是让Opus写一篇论文,它可能会比Sonnet系列更注重学术严谨性,还会融入一些情感和伦理思考。
在创意写作任务里,Opus更强调真实性,支持态度也更强烈。
当然,人类是很复杂的。
仅凭对话数据是不可能完全确定潜在价值观的。Anthropic的提取方法虽然经过验证,但必然简化了复杂的价值概念,并可能包含解释性偏见,尤其是在非常隐含或模糊的情况下。
它也没有捕捉到时间先后,即AI或人类价值观哪一个先「出招」。
鉴于人类「先发言」而AI助手处于支持角色,通常假设AI的价值观更依赖于人类的表达,而不是相反。
「AI具有哪些价值观?每次都表现哪一种?」
这个问题并不简单,尤其是在模型适应用户的情况下——和Claude互动的每个人都不相同。
研究发现,虽然Claude表达了数千种多样的价值观,但它倾向于表达一些常见的、跨情境的价值观——即在不同情境下保持稳定的价值观——主要集中在称职和支持性的帮助上(例如乐于助人、专业性、细致和清晰)。
这些跨情境的价值观可能以一种类似于人类价值观理论化的方式指导Claude的行为。
Anthropic的分类法通过组织价值观来展示其概念和上下文维度,有助于推进AI价值观理论的发展,并构建基于现实相关性的AI 原生的价值测量。
随着这些系统面临越来越多样化的现实应用及其不同的规范要求,这些方法和结果为更基于证据的AI系统价值观评估和对齐提供了基础。
Anthropic的这个研究也暗合了最近OpenAI奥特曼的透露的一个事实,人们使用AI时,非常容易说出「请」和「谢谢」——光这些感谢就烧掉了数千万美元。

虽然人们都知道对面「坐着」的不是一个人,但是依然愿意用人类的价值观来对待它。
看在人类这么追求AI对齐的份上,希望未来的AI也能对人好一点。
(文:新智元)