
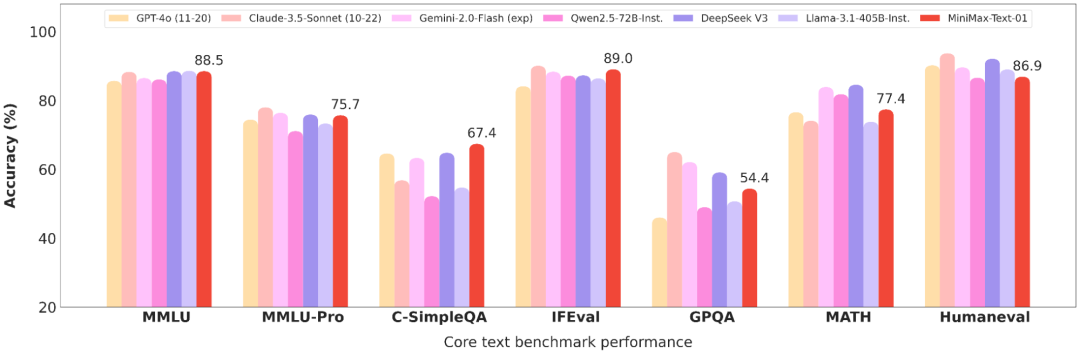
在Transformer几乎一统天下的今天,MiniMax-01选择了另一条路:放弃“主流”Transformer,押注更小众但计算更高效的线性注意力(linear attention),并将其规模推进到惊人的4560亿参数,搅动开源圈。
线性注意力是什么?一句话解释,它是一种能将原本计算量为 O(n²) 的attention结构压缩为 O(n) 的优化方法。
但它很早期时效果并不好,也少有人关注。直到MiniMax团队将其持续打磨,并在2023年内推出了多个关键技术,包括:
-
用cos函数替代softmax的Cosformer;
-
分析性能瓶颈的The Devil in Linear Transformer;
-
更快的Lightning Attention,通过分块算法提升速度、降低延迟;
-
与Transformer结合的Hybrid架构,既保证性能也保留一定retrieval能力(即上下文记忆);
这些研究逐步把线性注意力从“理论好看、实际不行”的尴尬地带,推到了足以工业部署的成熟阶段。
架构负责人钟怡然说,当大家还在担心线性注意力放大之后会不会失效时,MiniMax已经用400多B规模的模型验证了它“能跑、能快、能长记性”。
他提到,这种架构的本质优势是随着序列变长,成本优势会越来越大:在1M长度输入下,softmax attention的延迟是lightning attention的2700倍。而这也让lightning架构在长文本生成、长链推理等方向上具备独特优势。
不过,线性注意力也不是完美。retrieval能力弱是当前难解的瓶颈,这也是目前行业仍偏好hybrid架构的主要原因。未来可能会通过更极致地稀疏化softmax attention,进一步降低成本但保留核心能力。
钟怡然还透露,下一步他们可能探索的方向是统一理解与生成的大模型架构,即多模态原生模型。他也认为,面向AGI终局,O(n)复杂度的架构才更符合人类智能的认知模式。

参考文献:
[1] 开源地址:https://github.com/MiniMax-AI/MiniMax-01
[2] 模型下载:https://huggingface.co/MiniMaxAI/MiniMax-Text-01
[3] MiniMax押注线性注意力,让百万级长文本只用1/2700算力|对话MiniMax-01架构负责人钟怡然:https://mp.weixin.qq.com/s/NigAnui9fXbfresW8KIX-Q
[4] https://www.minimax.io/
(文:NLP工程化)