

编辑:杨文
这次,可灵 AI 又出尽了风头。
4 月 15 日,可灵 AI 开了场发布会,高调推出最新升级的两款基础模型 —— 可灵 2.0 视频生成模型和可图 2.0 图像生成模型。
新模型效果好到什么程度?我们先整几个 case 开开眼。
教父怒目圆睁,脸部肌肉剧烈扭曲,嘴角下拉,露出紧咬的牙齿。这「演技」是不是和马龙・白兰度有一拼?
女人手握破碎的手机,面露惊恐,浑身颤抖,一股恐怖气氛扑面而来,极具视觉引导力和情绪张力。
骏马在草原奔跑,鬃毛随风翻飞,身后扬起阵阵尘土,即使是大幅度运动,画面也丝毫没崩。
总体来说,相比于之前版本,可灵 2.0 拥有更强的语义响应、更优的动态质量和更好的画面美学。
同时,图像生成模型可图 2.0 也完成了重磅更新,不仅提升了语义遵循能力,画面更具电影质感,还能响应近百种风格。

prompt :现代城市被切割成一块块悬浮在空中的片段,每块中都有正常的、完整的生活场景(例如行人、交通、建筑),但它们彼此之间由不可见的空间分离,有城市被切割开的断裂感,营造出一种 “现实感中的超现实”。科幻大片质感,细节完美。

prompt 摆满了白色桌子的宴会厅,周围坐着的人在享用一顿美餐。

多种风格响应
最重要的是,可灵 AI 不搞期货,发布即上线,全球会员都能上手体验。
可灵 AI 链接:https://app.klingai.com/
有史以来最强大视觉生成模型
「双模型」同时迭代让可灵 AI 展现出了向专业级创作工具迈进的潜力,也真正开启了 AI 生成内容的黄金时代。
接下来,我们就用 20 组镜头,来看看这两个模型到底升级了啥,又是怎么玩出新高度的。
可灵 2.0 视频生成模型
相比于 1.6 模型,可灵 2.0 主要有三大优势。
首先,在语义遵循方面,它对动作、表情、运镜响应更佳,并支持描述时序更复杂的镜头。
比如输入 Prompt:男人先是开心的笑着,突然变得愤怒,手锤桌子起身。
这段文本描述看似简单,实则很考验模型的情感捕捉、动作生成以及细节表现能力。
可灵 2.0 不仅成功捕捉到了男子从开心到愤怒的情感转变,还在时间上合理衔接每个阶段的表情和动作,并通过运镜来实现视觉的自然过渡。

可灵 2.0 生成效果
相比之下,1.6 模型在生成中就存在明显差距,没有呈现「手锤桌子起身」的动作,而且手部细节还出现肉眼可见的崩坏。

可灵 1.6 生成效果
再来看看 2.0 模型的运镜响应能力。
Prompt:镜头捕捉身穿白色连衣裙和草帽的女孩在海边漫步,镜头围绕女孩环绕运镜,女孩面带微笑,眼神温柔,夕阳的余晖洒在海面上。
可灵 2.0 环绕运镜
Prompt:镜头 1:手持镜头特写男子在直升机舱内强风吹拂面部扭曲,自然光下背景广阔天空,表情坚定;镜头 2:男子纵身跃出机舱急速下坠,高空云层翻滚,镜头跟随展现自由落体动态;镜头 3:降落伞在空中猛然展开,镜头拉远呈现全景,阳光穿透云层照亮伞面,紧张氛围瞬间缓解。
可灵 2.0 镜头组合运镜
由此可见,可灵 2.0 不仅能 get 到推拉摇移等基础运镜术语,还能通过提示词激活环绕运镜、跟随运镜以及镜头组合运镜等。
而所谓的时序响应能力,就是在同一个 Prompt 中按照时间顺序进行分段描述,模型严格按照时间顺序生成。
比如 Prompt:女孩从静坐在公园长椅上,到慢慢走出画面,晨光逐渐转为正午烈日再过渡至暮色四合,天空色彩从粉橙渐变为湛蓝再转为紫红,来往行人形成流动的虚影轨迹,固定镜头,突出光影在长椅木纹上的缓慢爬行,飘落的树叶在长椅下堆积又随风卷起。
可灵2.0生成效果
这段提示词既包括复杂的光影色彩变化,又涉及固定镜头、静态场景(长椅)和动态元素(行人、风、树叶),这对 AI 的生成能力提出了极高的要求。
不过 2.0 模型严格遵循了文本提示,无论是女孩的肢体动作,还是背景的光线、色彩变化,以及行人的虚影轨迹,它都处理得很到位。
其次,在动态质量方面,可灵 2.0 生成的运动幅度更大,速度更流畅,复杂动作也更自然、更合理。
比如小男孩在街头玩滑板,这一过程包含滑行、跳跃、翻转、落地等一系列动作,可灵 2.0 生成的视频呈现出一种快速且流畅的运动感,即使涉及复杂运动,人物动作也没有变形扭曲。

可灵2.0生成效果。图生视频。Prompt:滑板运动,围绕滑板少年不断运动
而 1.6 模型生成的视频则像开了慢速,而且滑板在空中翻转时画面出现了伪影和闪烁。

此前,Sora 等 AI 视频生成模型只要碰上体育运动就歇菜,不是顺拐就是脑袋乱飞,而现在可灵 2.0 竟能轻松生成「飞檐走壁」的跑酷运动,整套动作行云流水、一气呵成。
可灵2.0生成效果
还有下面这个视频,身穿貂皮大衣的男人为躲避爆炸在雪地里狂奔,如此大幅度的运动,可灵 2.0 也没有出现左右腿不分的问题。
可灵2.0生成效果
此外,可灵 2.0 生成的画面美感也大幅提升。
其中文生视频可响应影视级别的画面描述,极具大片质感。
比如 Prompt:镜头跟随蜜蜂快速的在花丛中穿行,最后聚焦在一刻沾满露珠的鲜花上。
可灵 2.0 模型生成的画面中,蜜蜂表面的绒毛、花瓣的纹理以及露珠全都清晰可见。

图生视频则可以更好地保持原图画风,延续更多美感。
比如「喂」给它一幅孩子们在海边奔跑的油画,可灵 2.0 立马让画面「活」起来,并且视频的每一帧都保留了原图独特的油画纹理感。
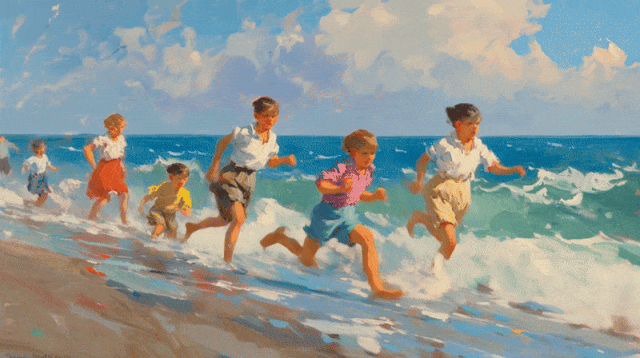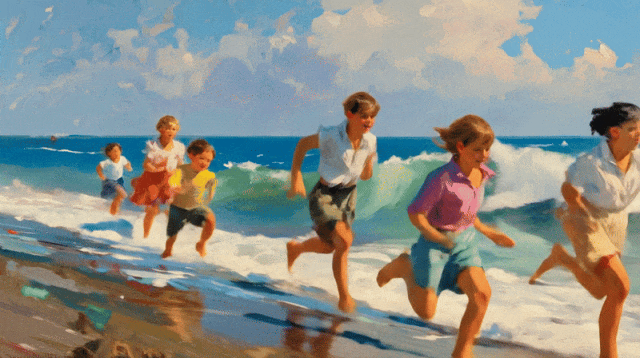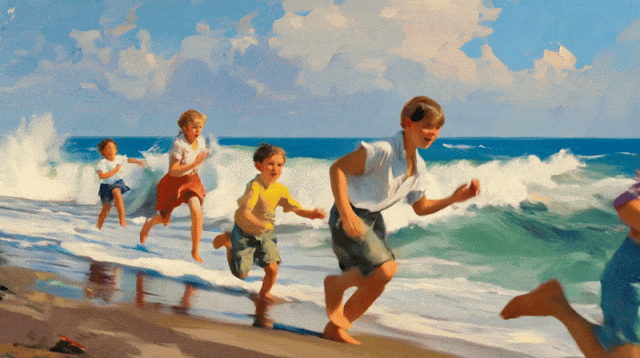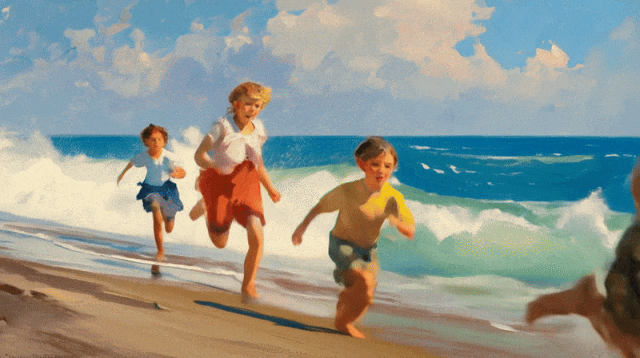
除了基础模型迭代优化以外,可灵还基于 1.6 模型上线了多模态编辑功能。只需上传一段 1-5 秒的视频,它就能对画面元素进行增、删、改、替。
可图 2.0 图像生成模型
据快手副总裁、可灵 AI 负责人张迪透露,当前,图生视频约占到可灵 AI 视频创作量的 85%,图片质量对视频的生成效果产生重要作用。
为了更好赋能创作者,可图 2.0 文生图能力也迎来全面升级,包括大幅提升指令遵循能力、显著增强电影美学表现力以及更多元的艺术风格。

Prompt:低饱和度,大师构图,电影画面,欧洲电影,磨砂质感,高质量画面,穿着白色裙子的女孩,背包里都是野花,她站在草地上,空中飘着非常多的迎春花的花朵。

Prompt: 电影质感,法国影片,复古,自然光线,暖光,一个穿着浅绿色茶歇裙的女生抱着一捧花,躺在湖心的小木船闭眼哭泣,湖中有大片睡莲,前景有一棵大树,夕阳洒在湖中,水面波光粼粼。

prompt:两位年轻亚洲高中生在一架豪华黑色三角钢琴前并排坐着,沉浸在演奏中。左侧是一位短发女性,穿着正式的黑色燕尾服式演出服,白色蝴蝶结,黑色背心,闭着眼睛,表情专注而陶醉。右侧是一位短黑发男性,身着灰色V领毛衣,白色衬衫和紫色领带,微微低头专注于琴键。钢琴盖完全打开,露出内部精致的铜色琴弦和复杂的机械结构。场景位于一个古典风格的音乐厅或豪宅内,背景墙面呈淡绿色,装饰有金色相框中的古典画作。整个画面采用电影般的复古色调,带有轻微颗粒感,主要光源从侧面柔和地照射,在钢琴表面和演奏者脸上形成温暖的高光。构图从钢琴侧面略微俯视角度拍摄,前景是钢琴边缘的模糊轮廓,中景是两位演奏者,背景是模糊的墙面和画作。画面氛围优雅、庄重而富有艺术感,捕捉了音乐演奏的深度专注与情感交流的瞬间。

Prompt:电影静帧,镜头正面跟随一位身穿红色连衣裙的女子在雨中奔跑,她的头发被风吹乱,脸上混合着雨水和泪水,背景是模糊的霓虹灯光,街道湿滑反光。
瞅瞅这配色、这光影、这构图,乍一看还真以为是电影剧照。
此外,可图 2.0 还支持近百种风格响应,涵盖特殊材质、数字艺术和绘画技法等。什么吉卜力、赛博朋克、透明玻璃、极简摄影…… 通通能搞定。

















左右滑动查看更多
如果想对画面细节或尺寸进行修改,我们还可以使用局部重绘或扩图功能。
只要一涂一抹,再输入提示词描述,就能对图片元素进行增加、修改等操作。


或者随意拖拽原图位置,就能改变原图大小,自由扩充图片内容,而且完全看不出扩图痕迹。

不仅如此,在图像的多模态可控生成中,可图 2.0 还上线了全新的风格转绘功能,只需上传图片并输入风格描述,就能一键切换艺术风格。







左右滑动查看更多。图一:原图;图二: 吉卜力风;图三: 手办风;图四:3D卡通风;图五:美少女风;图六:平涂插画风;图七:棉花娃娃风
可灵 AI 如何稳居 AI 视频赛道 C 位?
自去年 6 月 6 日上线以来,可灵 AI 就开启狂飙模式,仅 10 个月就迭代 20 多次,并发布 9 个具有里程碑意义的产品。
模型从 1.0 不断升级到如今的 2.0 版本,不仅显著提升了视频生成质量,也奠定了其在全球市场的领先地位。
此次发布会上,快手高级副总裁、社区科学线负责人盖坤透露,可灵 2.0 在团队内部的多项胜负率评测中,均稳居业内第一。
比如在文生视频领域,可灵 2.0 对比谷歌 Veo2 的胜负比为 205%,对比 Sora 的胜负比达 367%,在文字相关性、画面质量、动态质量等维度上显著超越对手。(注:胜负比为 100% 说明两个模型同样厉害)

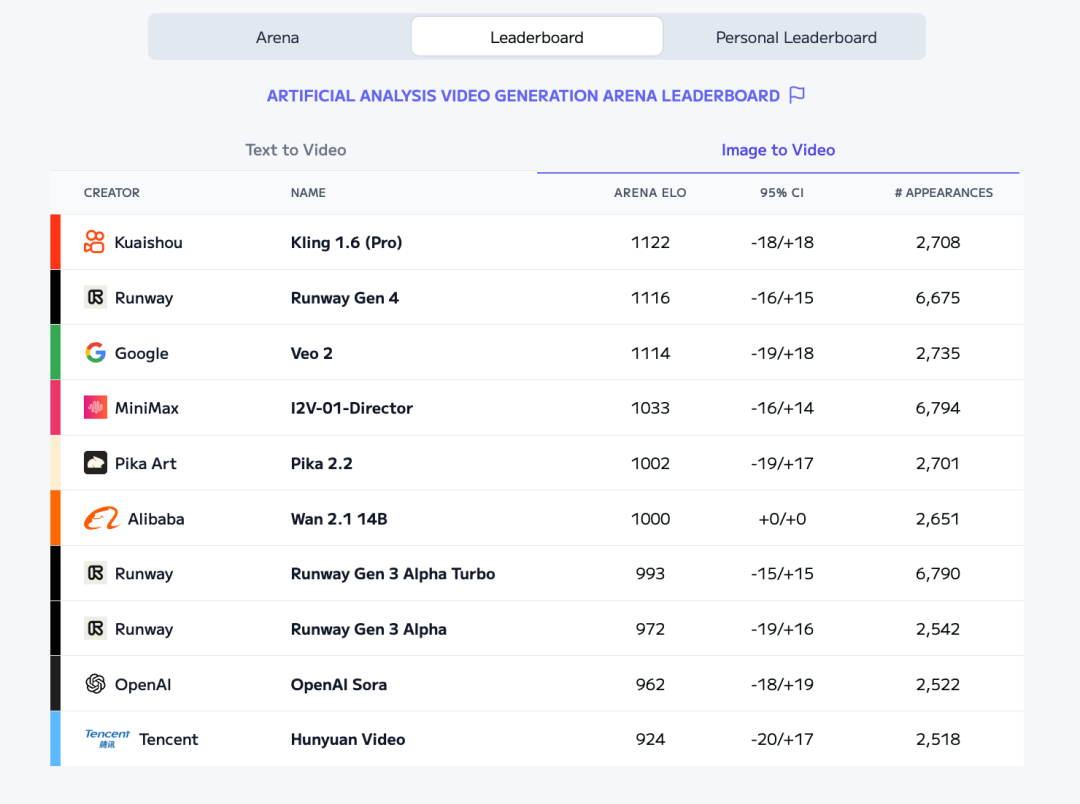
3 月 27 日,全球知名 AI 基准测试机构 Artificial Analysis 发布最新全球视频生成大模型榜单,快手可灵 1.6 pro(高品质模式)以 1000 分的 Arena ELO 基准测试评分,登顶「图生视频」赛道榜首,超越了 Google Veo 2 与 Runaway Gen-4 等国际顶尖模型。
而模型能力的迭代自然离不开技术上的创新支撑。这既包括基础模型架构上的升级,也包括训练和推理策略上的突破。
一方面,可灵 2.0 采用了全新设计的 DiT 架构,提升了视觉 / 文本模态信息融合能力;全新设计的视觉 VAE,使复杂动态场景下过渡更自然;同时可灵 2.0 首次系统性研究视频生成 DiT 架构的 Scaling Law 特性。可以说,全新设计的视频生成基础模型,使得可灵 2.0 打开了建模和仿真能力空间。
另一方面,可灵 2.0 全面升级训练和推理策略,强化对于复杂运动、主体交互的生成能力,强化对运镜语言、构图术语等专业表达的理解和响应能力,还进一步对齐人类偏好,让模型更懂「常识」和「审美」。
在图像生成大模型领域,可图 2.0 同样处于行业领先水平,在团队内部的多项胜负率评测中,相较于 Midjourney V7、FLUX1.1 [pro] 以及 Reve 等图像模型,均保持明显优势。
可图 2.0 的基座升级,背后也对应着大量的技术突破。在预训练阶段更精准地建模了文本到视觉模态的映射,在后训练阶段使用了更多的强化学习进行美学和人类偏好的对齐,在图像生成阶段则使用了全新的提示词工程和推理策略来优化图像的生成。
在图像和视频的多模态控制能力方面,可灵团队则使用了统一的模型架构处理文本、图像和视频表示及输入,实现有效的多模态控制效果;同时,通过高效的 Token 压缩与缓存算法,支持长序列的上下文学习;最后通过带 COT 能力的多模态推理技术,帮助精确理解用户意图,模型可以提供更好的基于多模态理解的视觉生成。
AI 视频进入 2.0 时代
定义人与 AI 的交互新方式
作为全球领先的视频生成大模型,可灵 AI 基础模型「双子星」的重磅升级,标志着 AI 视频创作正式迈进了 2.0 时代。
那么,这个新时代最核心的变革是什么?简单来说,就是人人都能用 AI 讲好故事。
在 1.0 时代,各科技大厂隔空斗法,通过持续的技术创新,解决了 AI 视频生成领域多个核心难题。比如,可灵 AI 陆续上线了人脸建模、口型同步、智能配音、运动质量、风格化、首尾帧、AI 音效以及资产管理等关键功能,并深度接入 DeepSeek,全面打通文案、图像、视频、音效等内容形态,实现真正的一站式智能创作链路。
得益于此,视频生成大模型的用户规模也迎来爆发式增长。截至目前,可灵 AI 全球用户规模突破 2200 万。过去的 10 个月里,月活用户量增长 25 倍,累计生成超过 1.68 亿个视频及 3.44 亿张图片。
不过,盖坤在发布会上坦言,尽管 AI 在辅助创意表达上拥有巨大潜力,但当前的行业发展现状还远远无法满足用户需求,尤其在 AI 生成内容的稳定性、以及用户复杂创意的精确传达上仍有「很多挑战」。也因此,要真正实现「用 AI 讲好每一个故事」的愿景,必须对基模型能力进行全方位提升,定义人和 AI 交互的「全新语言」。
在本次 2.0 模型的迭代中,可灵 AI 正式发布 AI 视频生成的全新交互理念 Multi-modal Visual Language(MVL),让用户能够结合图像参考、视频片段等多模态信息,将脑海中包含身份、外观、风格、场景、动作、表情、运镜在内的多维度复杂创意,直接高效地传达给 AI。
「大家应该很自然地会感受到文字在表达影像信息时,是不完备的。我们需要有新的方式,能让人真正精准地表达出心中所想。」盖坤指出,MVL 由 TXT(Pure Text,语义骨架)和 MMW(Multi-modal-document as a Word,多模态描述子)组成,能从视频生成设定的基础方向以及精细控制这两个层面,精准实现 AI 创作者们的创意表达。
为了进一步激发 AI 爱好者们的创作热情,快手副总裁、可灵 AI 负责人张迪还在发布会现场正式发起「可灵 AI NextGen 新影像创投计划」。该计划将加大对于 AIGC 创作者的扶持力度,通过千万资金投入、全球宣发、IP 打造和保障,以全资出品、联合出品和技术支持等灵活多样的合作方式,让 AI 好故事走向世界。
如今,从 UGC(用户生成内容)到 PGC(专业生成内容),从社交短视频到广告营销,可灵 AI 在各类场景中的应用趋势日益明显,这也意味着,未来「人人都能用 AI 讲好故事」不再是一句口号,而成为每个人的创作现实。
©
(文:机器之心)