

刚出道的 HiDream-I1,拿下了 Hugging Face 趋势榜第二(图像榜第一),Artificial Analysis 文生图第二,排在Midjourney、Google Imagen、FLUX、SDXL 之前,仅次于 GPT-4o 。
老实讲,看多了龙争虎斗,本应对此免疫。
但被提醒道:这是个创业团队搞的,来自合肥
打了个猛子…牛逼牛逼,真尼玛牛逼
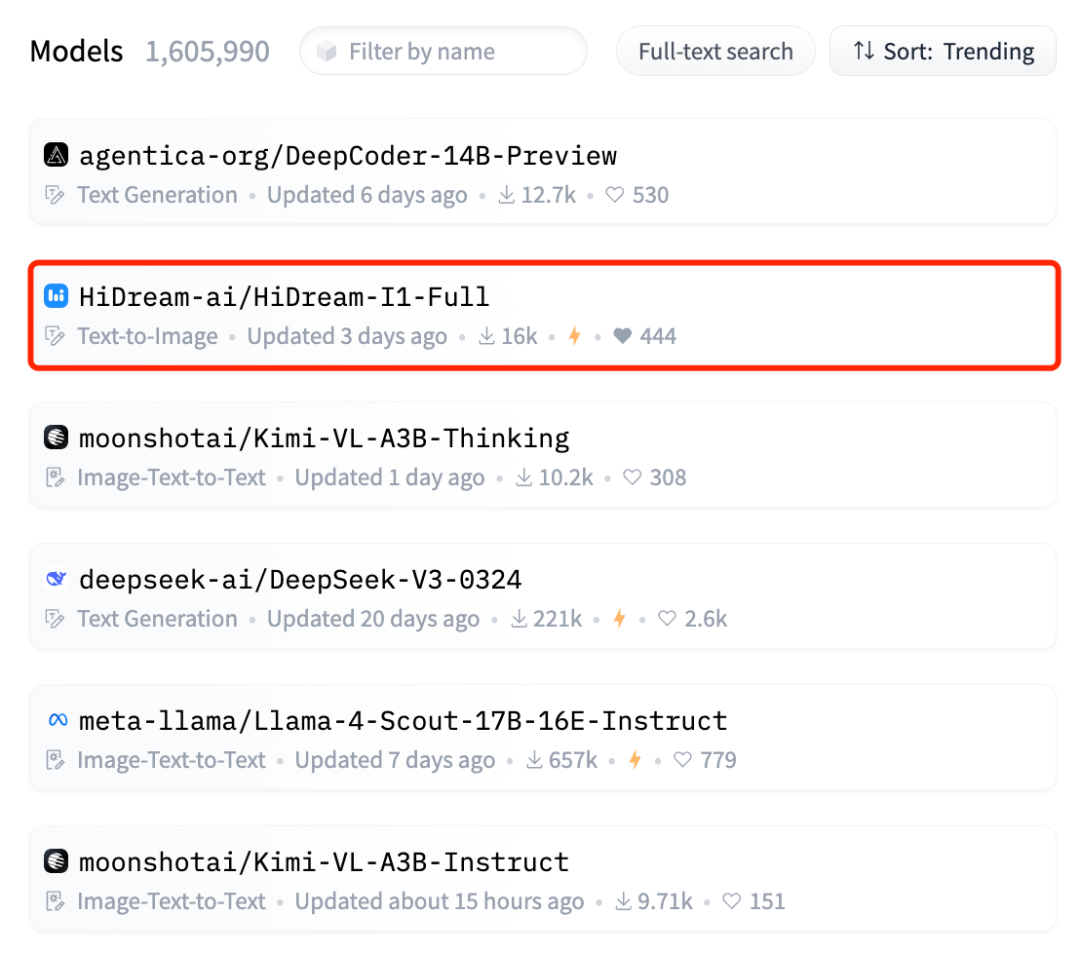
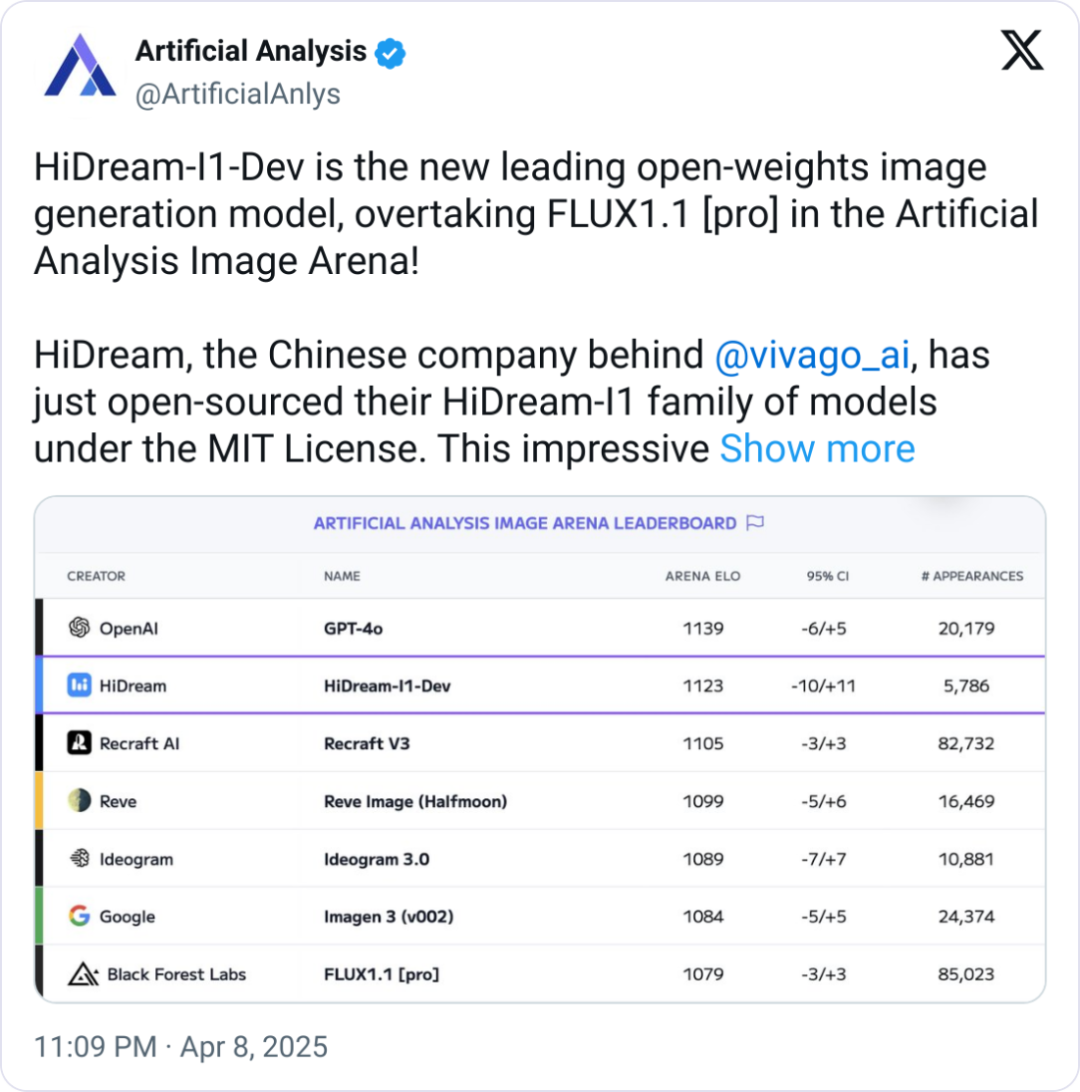
不得不仔细看了几眼:
-
• 它是MIT 协议,开源的可商用 -
• 它是中国团队做的,也没拿自己和谁对标 -
• 它是可部署的,权重、脚本、demo、量化全部已放出 -
• 这不是大厂项目,这不是!这不是!
真的,这东西,是我们“默认国内早就该有”,但直到现在才出来的东西。
甚是好奇,随即我联系上了背后团队,问了大量私货,有了这篇文章。
真实可用,不是PPT
HiDream-I1 分三个版本:Full / Dev / Fast,分别对应不同的推理场景。
这里有几个官方 Case,来自官方自己的报道




我去跑了几个任务:



生成质量稳定,理解力准确,出图速度在 Full 版下约 30 秒/张,Dev 版下 10 秒/张,Fast 则为 5 秒/张,可以直接挂进内容生产链路中使用。
这些速度不是靠粗暴剪枝换来的:Dev 和 Fast 模型是在原版基础上,通过 GAN 辅助的扩散蒸馏方式做出的结构级压缩:保留了大模型的细节能力,同时显著降低了推理成本。Fast 版本则进一步压缩采样步数,有了更快的速度
直接能用
HiDream-I1 优化了整套部署支撑,所以无论是做项目原型,还是打包进服务,这套模型的部署链路都非常顺畅:
-
• 15GB 显存起步就能跑 Dev 版本,推理速度约 10 秒一张图 -
• Hugging Face 上权重齐全,配套的推理脚本和配置文件全部开源 -
• Diffusers 接口支持完整,可以一键加载到现有 pipeline 里使用 -
• 可接入 ComfyUI / Gradio,可直接嵌入原本工作流 -
• 支持 4bit 量化与 LoRA 微调,适合本地部署和行业定制任务

可以在 Hugging Face 上先玩(也有对应的 Space)
https://huggingface.co/HiDream-ai/HiDream-I1-Full
他们也有更加产品化的网站(面向海外的)
https://vivago.ai/studio
一些数据
在几项主流评测里,会发现它的表现也都在第一梯队:
-
• DPG-Bench:评估模型对复杂提示的理解与还原能力,得分 85.89,总分第一 -
• GenEval:评估模型对提示中对象的理解与执行能力,得分 0.83,开源模型中最高 -
• HPS v2.1:评估图像的主观美感和语义一致性,HiDream-I1 得分 33.82,高于 Midjourney V5、SDXL、DALL·E 3
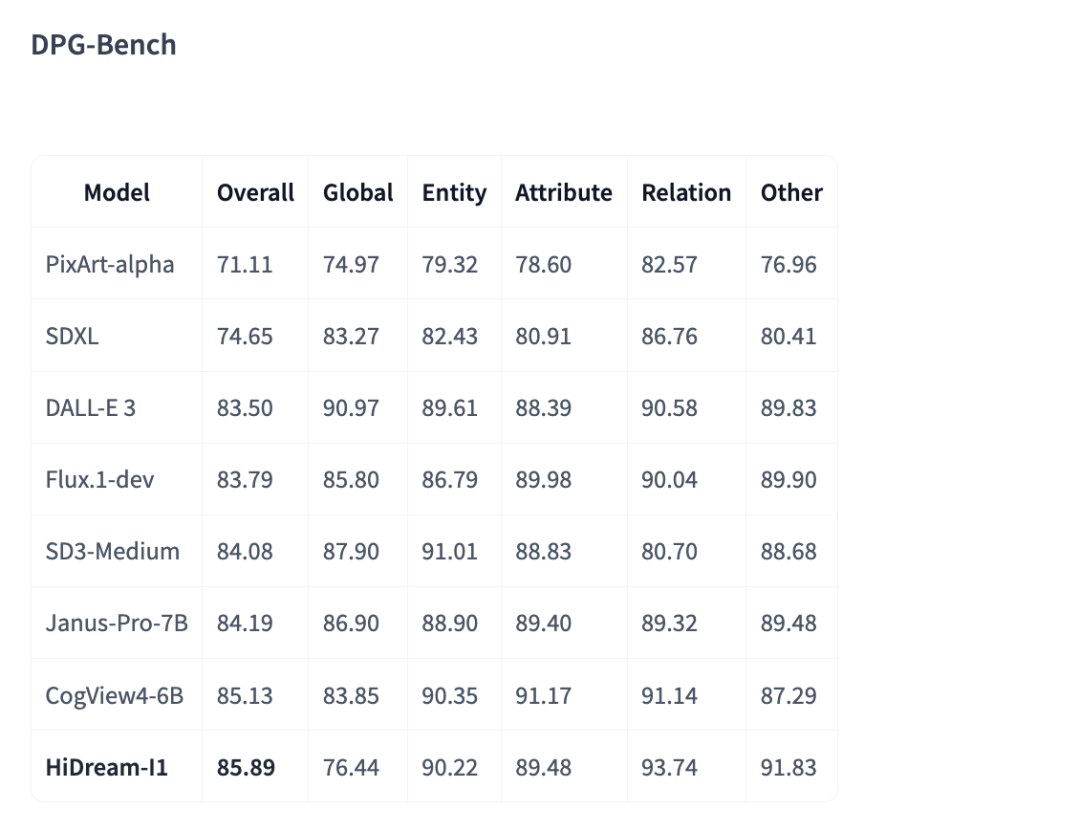
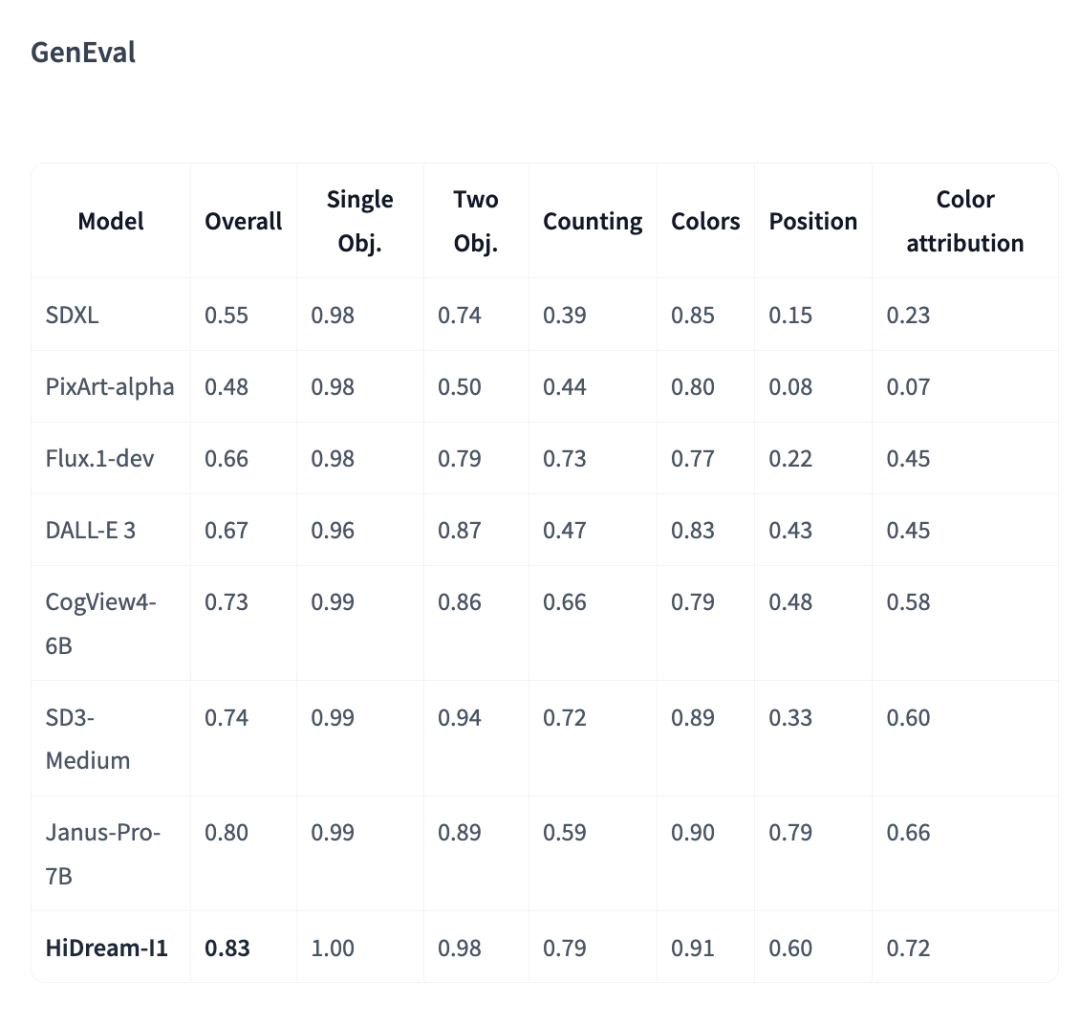
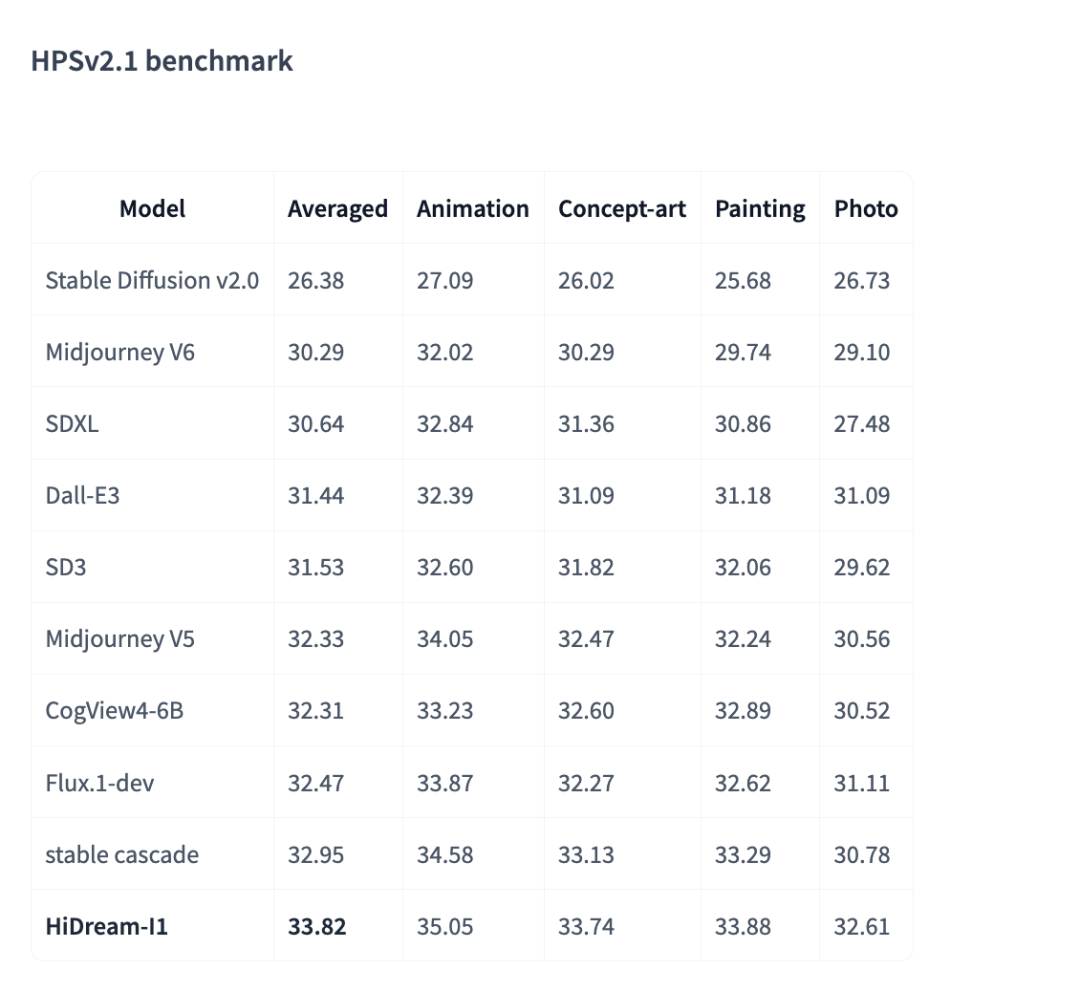
这些 benchmark 来自公开信息,可以复现试试。
它们的结果,其实只说明一件事: HiDream-I1 在理解文本、还原细节、维持画面质量这三件事上,是稳的。
One More Thing
I1 之后,这几天他们还会开源 E1。

I for Image,E for Editor:从图像生成,到图像编辑
用对话的方式改图,像 GPT-4o 那种,敬请期待。
来自合肥,低调做事
第一次注意到 HiDream 这个团队,还是去年初雪;
再次看到,已是春暖花开。
当时只道是寻常,没第一时间去深聊。
而在过去两周里,HiDream-I1 在开源生态中一路高歌猛进,排名跃升,着实令人咋舌:参数不大,速度稳定,出图质量靠得住,还能跑到顶级开源模型前列。这在如今的开源图像模型里,已经很罕见了。
好奇之下,我联系到他们,和团队聊了半个下午,拼出这个项目的全貌。
HiDream.ai 成立于 2023 年 3 月,在合肥。就是那个背靠中科大,孵化了京东方、科大讯飞的合肥。
创始人梅涛,亦是中科大背景:在中科大读了本、硕、博,微软亚洲研究院做了 12 年研究员,后来在京东探索研究院任副院长,还是 IEEE Fellow、加拿大工程院外籍院士。
这个项目的天使轮,来自群友:一个叫“中喝大”的中科大校友群。在这里 15 位校友自发组了 LLP,投下“种子一号基金”。在之后,是上面提到的「敦鸿资本领投的 Pre-A 轮融资后,又获得数亿元 A 轮融资,两轮融资总共规模达到数亿元人民币」。在行业之内,融的不算多。
梅涛自己说,他创业不是为了跟谁竞争,也不是为了赶热点,而是想证明——中国的科研人才可以在工业级产品线中做出自己的东西。哪怕晚几年,但路径能跑通、结构能复制。
目前, HiDream.ai 团队也就 50 人上下,但拥有目前行业中最丰富的多模态版权语料库,并且把训练 ROI 做到了业内平均的 1/5。模型路线走的是自研架构、全流程闭环,也是在中国少数真正“从基础模型一路做到应用层闭环”的图像/视频方向创业公司之一。

在他们上周海外爆火了一波后,照理说你会看到铺天盖地的 PR 稿件,来讲什么“国产替代”或“国产超越”的故事。
但实际上,啥也没有。看到的就只是把权重挂上 Hugging Face,贴好推理脚本、样例代码、demo 页面,然后静静等社区试用。
我问他们,“为什么不讲点东西?”
团队的回答是:“说得响没用,能用才有价值。”
语气平实,节奏克制。
能看出,他们不是不准备,而是不着急。
这两天,他们还会正式开源 HiDream-E1,E for Editor。
接下来,HiDream 还会陆续发布多模态 Agent 模型 HiDream-A1(A for Agent)、产品 vivagov2.0,面向专业创作者的终端 App,以及视频生成的相关东西(预估是5月)。
没喊口号,按计划在推进。不在造势,而在做事。
结尾
很有意思,AI 的大火从北京烧到上海,进而点亮了「杭州六小龙」,也让我们看到了 Manus 在武汉崛起。
现在,合肥也交出了自己的答卷:HiDream。
一个创业团队,从图像模型切入,在没人关注的节点,把一件“早就该有人做的事”做出来了。
春风拂面,桃花满枝。
我们越发看见、也越发确信:
中国的创业公司,不讲故事,也能把答案写在时代的卷首。
(文:赛博禅心)