

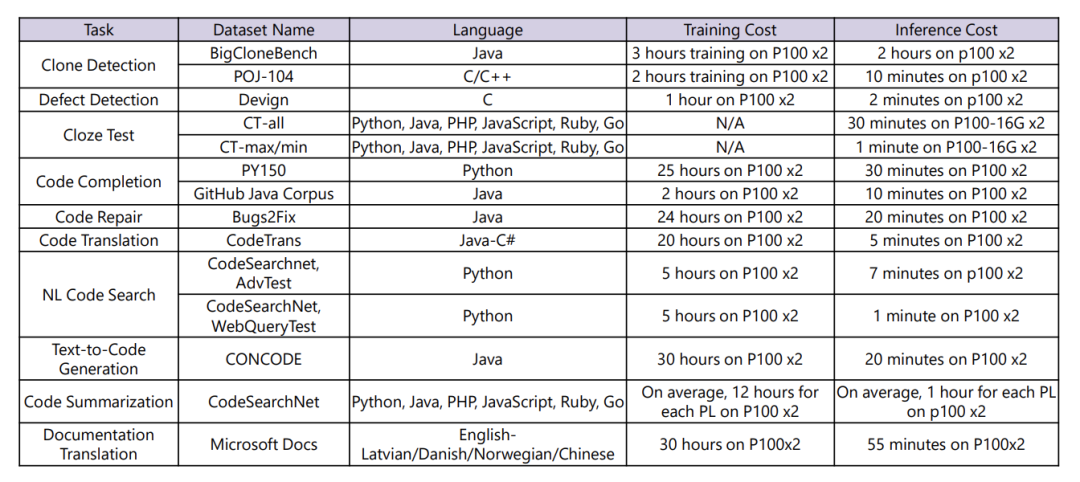
Stack Overflow QA Pairs
数据集链接:http://e8gub.ensl.cn/8d
StaQC (Stack Overflow Question-C ode pairs) 大约有 148K 个 Python 和 120K 个 SQL 域问题代码对,它们是使用 Bi-View 分层神经网络从 Stack Overflow 自动挖掘的
GitHub Code Search
数据集链接:http://e8gum.ensl.cn/a8
CodeSearchNet 是一组数据集和基准测试,用于探索使用自然语言进行代码检索的问题。 这项研究是本博客文章中提出的一些想法的延续,是 GitHub 和 Microsoft Research – Cambridge 的 Deep Program Understanding 小组之间的联合合作。
CodeContests
数据集链接:http://e8gu2.ensl.cn/4f
机器学习编程数据集
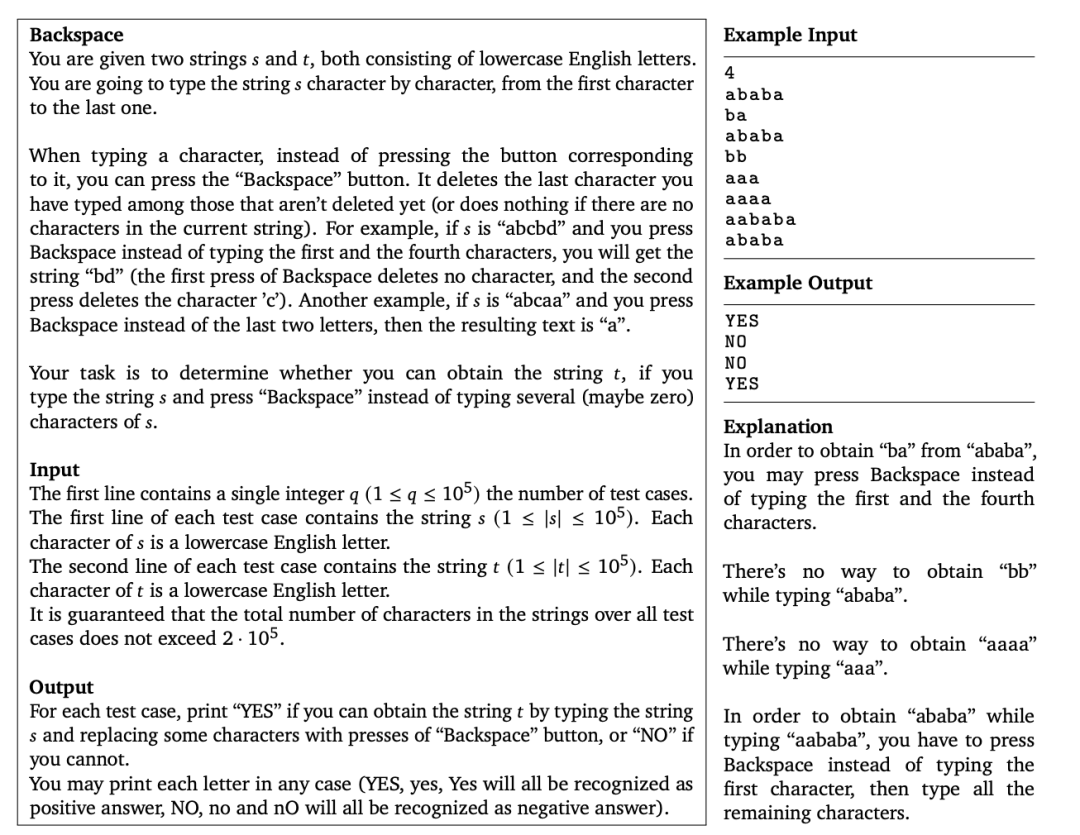
APPS
数据集链接:http://e8guw.ensl.cn/9d
包含5000+编程竞赛题目
HumanEval
数据集链接:http://e8gu9.ensl.cn/9d
BigCode Benchmark
数据集链接:http://e8guk.ensl.cn/77
BigCodeBench 是一个易于使用的基准测试,用于通过代码解决实际和具有挑战性的任务。它旨在在更真实的环境中评估大型语言模型 (LLM) 的真实编程能力。该基准测试专为类似 HumanEval 的函数级代码生成任务而设计,但具有更复杂的指令和多样化的函数调用。
CodeXGLUE
数据集链接:http://e8gux.ensl.cn/21
来自Microsoft Research Asia,开发人员部和Bing的研究人员介绍了Codexglue,Codexglue,一个基准数据集和代码智能的开放挑战。它包括代码智能任务的集合以及用于模型评估和比较的平台。法典代表代码的一般语言理解评估基准。它包括14个针对10种多元化代码智能任务的数据集
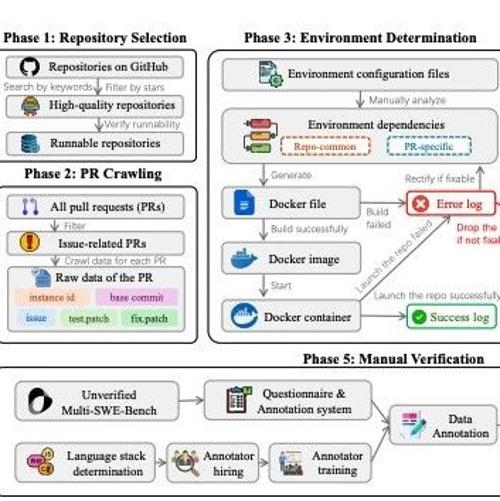
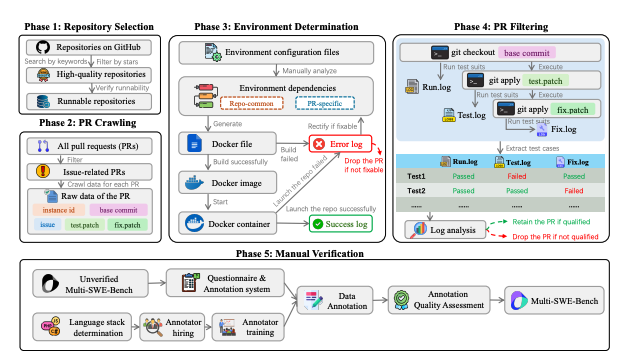
Multi-SWE-bench
数据集链接:http://e8gua.ensl.cn/c0
Multi-SWE-bench 解决了在实际代码问题解决中缺乏用于评估 LLM 的多语言基准的问题。与现有的以 Python 为中心的基准测试(例如 SWE-bench)不同,该框架涵盖 7 种语言(即 Java、TypeScript、JavaScript、Go、Rust、C 和 C++)和 1,632 个高质量实例,由 68 位专家注释者从 2,456 个候选实例中挑选出来,以确保可靠性。
(文:极市干货)