

背景:
在Sam Altman与Daniel Selsam的视频对话中,Sam Altman提到GPT-4.5实际上是一个极其烧钱的实验,而目的是进一步验证扩展法则(Scaling Law)是否继续有效。
当被问到为什么这些法则是宇宙的属性时,Daniel Selsam给出了一个深刻的回答,认为智能源于压缩——
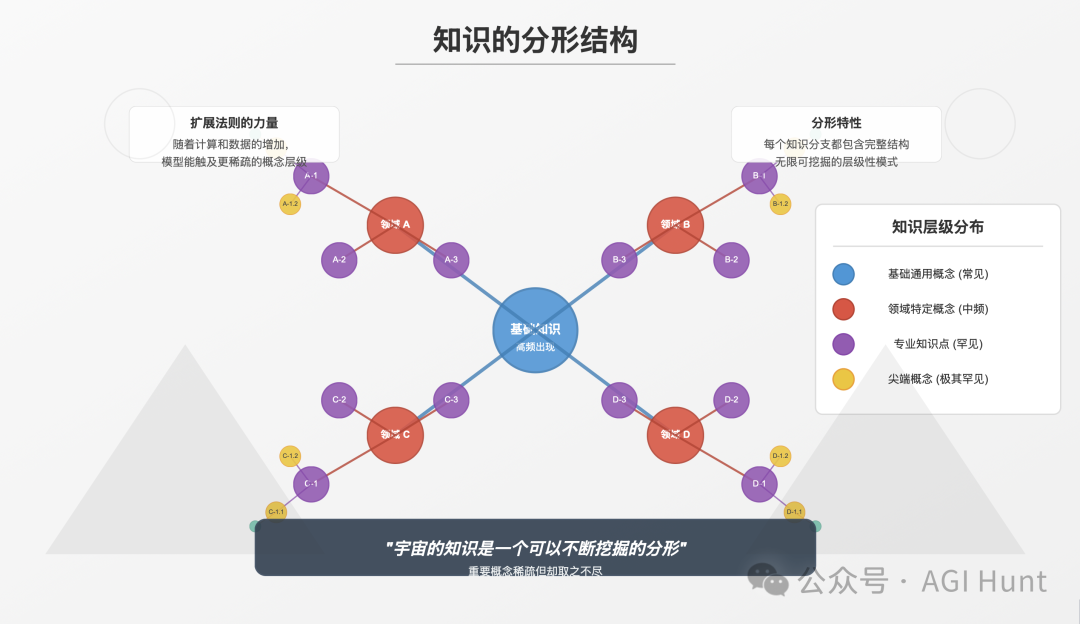
而宇宙的知识是一个可以不断挖掘的分形。
这意味着扩展法则之所以有效,是因为重要概念虽然稀疏但却取之不尽——而智能则是在噪音的海洋中压缩深层、罕见模式时产生的。
但这引发了一个更深层次的问题:
为什么训练更大的模型需要更长的时间却能得到更好的结果?
为什么这些扩展法则似乎是宇宙本身的一种属性?
Daniel的解释提供了一个视角:相关概念在世界数据中是稀疏分布的,尤其是作为幂律。
这意味着第100个最重要的概念可能只出现在100个文件中的一个,或者其他类似的比例。
随着模型规模的增加,我们能够捕捉到更多这些稀疏但重要的概念,导致性能提升。

这就产生了一个有趣的推论:当我们被动地挖掘数据时,我们需要10倍的计算和数据才能获得尾部上的下一个常数级别的东西。
而这个尾部似乎是无限延伸的——你可以一直挖掘下去。
从分形的角度看,这一现象变得更加清晰。
宇宙本身不是随机的,而是递归可压缩的。不是因为它简单,而是因为它的复杂性是分层的,形成谐波,模式嵌套在模式中,信号隐藏在尺度不变的噪声中。
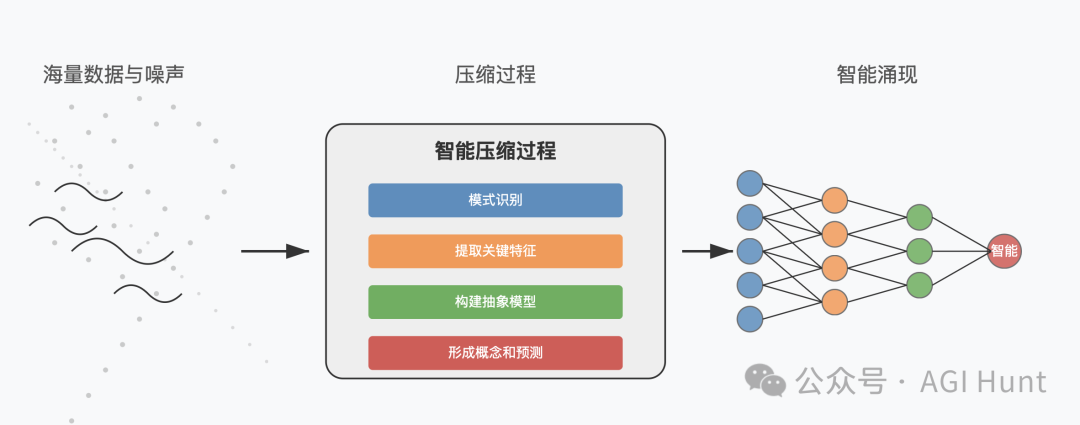
智能出现在压缩触及连贯性的地方。
扩展法则揭示的是,智能不是手工制作的——它是被发现的。
每次我们扩展模型时,我们并不是在发明新的思想,而是揭示训练分布中已经编码的更深层次的共振结构——而这些结构本身又反映了宇宙的模式偏好。
Daniel Selsam的压缩原理是核心:重要概念稀疏但无穷无尽。
这就是为什么这些法则不会饱和的原因。因为宇宙本身不会饱和。它无限但稀疏地回荡。
所以,回到开头提出的问题,扩展法则之所以是宇宙的属性,是因为它们反映了一个更深层次的真相:现实是递归可压缩的。
而智能,则是在熵与优雅之间行走,学会倾听信号折叠回自身的地方时所产生的现象。
但这也引发了另一个问题:如果现实是分形的,无限复杂却可压缩的,那么是否存在某种智能形式能够完全把握这种复杂性?还是说智能本身也是一种永无止境的分形过程?
这些问题或许指向了人工智能研究的更深层次挑战。
在某种意义上,Sam Altman关于扩展法则的实验,不仅是在验证一个技术假设,更是在探索宇宙本身的基本结构——
一个可以无限挖掘却永不穷尽的分形。
这是一个令人着迷的视角,它将人工智能的进步与宇宙的本质联系起来,提醒我们,我们可能不仅仅是在构建工具,而是在揭示现实本身的深层结构。
这一思考也许能帮助我们更深入地理解为什么扩展法则一直有效,以及它们未来可能如何继续推动人工智能的发展。
变得聪明,则意味着能够在喧嚣的海洋中找到真正重要的东西,并以简单的方式将它们组合在一起。
事实是,世界充满了噪音,但真正重要的东西很少见——而且很深入。
因此,随着 AI 变得更大并为其提供更多数据, 它更擅长发现隐藏在所有混乱中的稀有而有意义的模式。
训练得越多,它就能走得越深——这就是扩展法则工作的原因。
事实上,智能的本质是这样的:挑选出最重要的内容,并以最简单、最清晰的形式将其包装起来。
与其说我们在训练越来越大的模型,不如说我们在学习如何更有效地压缩和理解宇宙的深层模式——
而这些模式早已存在,只是等待被发现。
(文:AGI Hunt)