


本文介绍了 VideoPainter,一种用于视频修复的双分支框架,旨在实现高质量的视频内容恢复和编辑能力。
通过构建大规模(390K 视频片段)视频修复数据集,结合轻量级上下文编码器(仅占骨干网络参数的 6%)和掩码选择性融合和修复区域 ID 重采样等模型架构来增强可扩展性和长视频 ID 一致性。这些创新显著提升了模型在背景保留和前景生成的平衡能力和时间连贯性,为视频修复和视频编辑设立了新标准。
相关论文 VideoPainter: Any-length Video Inpainting and Editing with
Plug-and-Play Context Control 获得 SIGGRAPH 2025 录用,代码已开源。

论文地址:
https://arxiv.org/abs/2503.05639
Demo 视频:
https://www.youtube.com/watch?v=HYzNfsD3A0s
项目主页:
https://yxbian23.github.io/project/video-painter
项目代码和数据集:
https://github.com/TencentARC/VideoPainter

研究背景
视频修复(Video Inpainting)旨在恢复视频中的损坏区域,同时保持时间和空间上的连贯性,为视觉试穿、电影制作和视频编辑等应用提供支持。近年来,扩散变换器(Diffusion Transformers, DiT)在视频生成领域展现出巨大潜力,由此推动了生成式视频修复的探索。
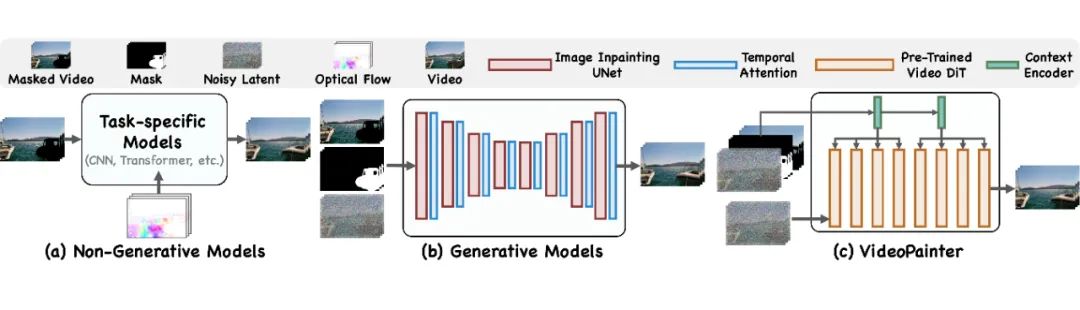
▲ 模型架构对比
然而,如上图所示,现有的视频修复方法主要分为两类:
非生成式方法:依赖有限的像素特征传播(物理约束或模型架构先验),只能接受带掩码的视频作为输入,无法生成完全被分割掩码覆盖的物体。
生成式方法:通过添加时间注意力机制扩展单分支图像修复架构到视频领域,但在单一模型中难以平衡背景保留和前景生成,且与原生视频 DiT 相比时间连贯性较差。
此外,两种范式都忽视了长视频修复,并且在处理长视频时难以保持一致的物体身份。

方法:VideoPainter
基于上述问题,VideoPainter 提出将视频修复分解为背景保留和前景生成两个任务,并在 DiT 中采用双分支架构。具体而言,VideoPainter 引入专用的上下文编码器用于提取掩码视频特征,同时利用预训练 DiT 的能力生成语义连贯的视频内容,同时考虑保留的背景和文本提示。
核心创新
轻量级上下文编码器:仅包含预训练 DiT 骨干网络参数的 6%,实现第一个高效的双分支视频修复架构。
分组式特征融合和掩码选择性融合:确保高效且密集的背景引导。
修复区域 ID 重采样技术:高效处理任意长度的视频,同时保持 ID 一致性。

VideoPainter 核心技术详解
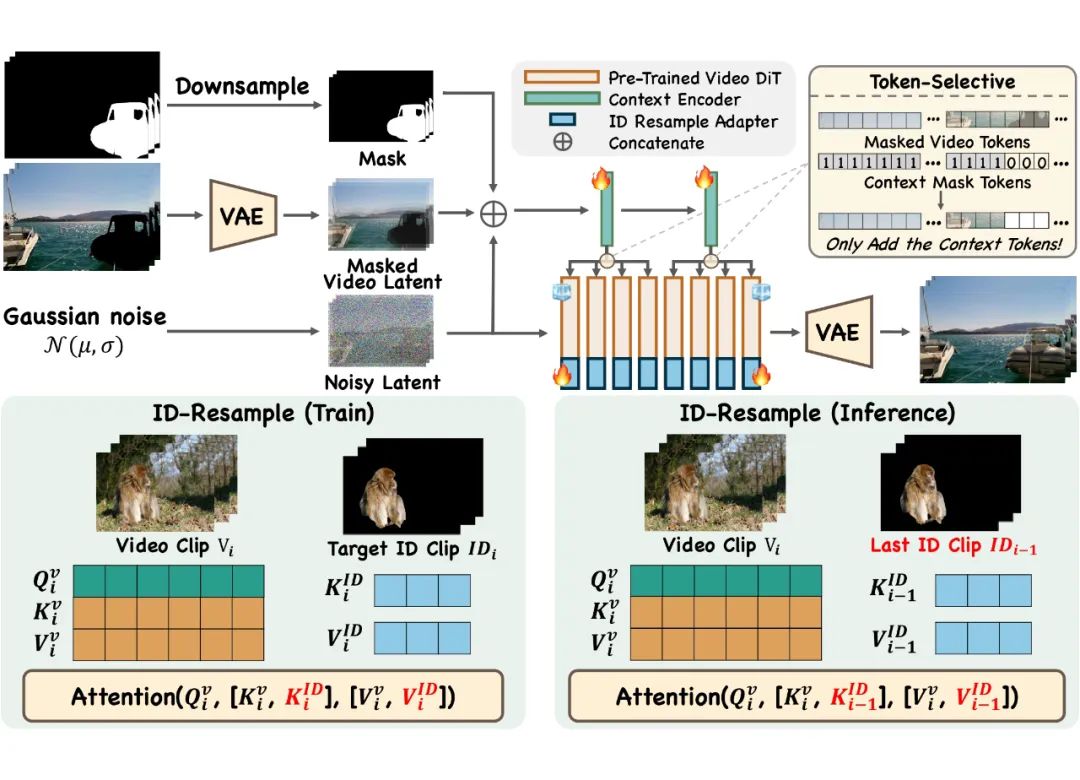
▲ VideoPainter 模型架构
1. 双分支修复控制
VideoPainter 通过高效的上下文编码器将掩码视频特征融入预训练的扩散变换器(DiT),解耦背景上下文提取和前景生成。编码器处理噪声潜变量、掩码视频潜变量和下采样掩码的连接输入。
具体实现:
-
轻量级设计:仅克隆预训练 DiT 的前两层,仅占骨干网络参数的 6%。
-
分组式特征融合:第一层特征添加到骨干网络的前半部分,第二层特征融入后半部分。
-
掩码选择性机制:预过滤过程中,仅添加代表纯背景的标记,确保只有背景上下文融入骨干网络。
2. 目标区域 ID 重采样
为解决长视频中的身份一致性问题,VideoPainter 提出了创新的修复区域 ID 重采样方法:
-
训练阶段:冻结 DiT 和上下文编码器,添加可训练的 ID 重采样适配器。当前掩码区域的标记与 KV 向量连接,通过额外的 KV 重采样增强修复区域的 ID 保留
-
推理阶段:优先保持与前一片段修复区域的 ID 一致性,将前一片段的掩码区域标记与当前 KV 向量连接,有效重采样并维持长视频处理中的身份信息
3. 即插即用控制
VideoPainter 的框架具备两方面的即插即用多功能性:
-
支持各种风格化骨干网络或 LoRA
-
兼容文本到视频(T2V)和图像到视频(I2V)的 DiT 架构
特别是 I2V 兼容性使其与现有图像修复功能无缝集成。使用 I2V DiT 骨干网络时,VideoPainter 只需一个额外步骤:使用任何图像修复模型根据掩码区域的文本描述生成初始帧。
VPData 数据集和 VPBench 基准构建流程
为了支持大规模训练和全面的测试,VideoPainter 开发了一个可扩展的数据集构建流程,创建了迄今为止最大的视频修复数据集 VPData 和基准测试集 VPBench,包含超过 39 万个片段,具有精确的分割掩码和密集的文本描述。
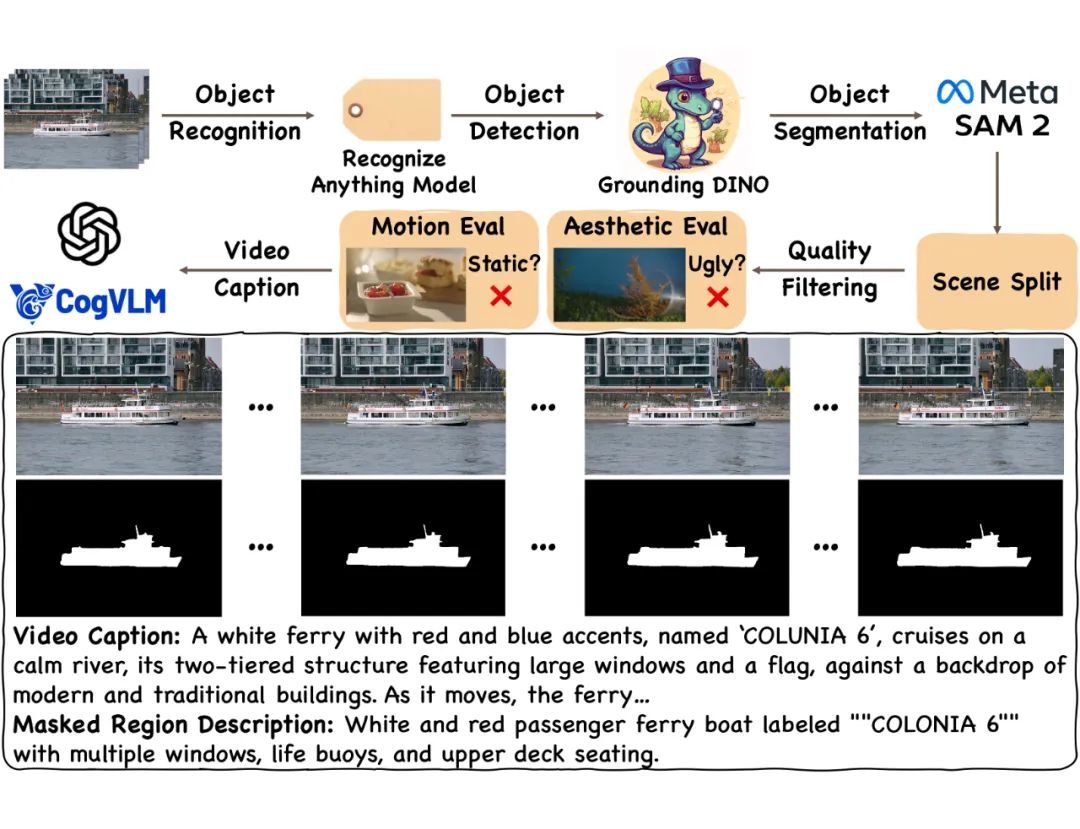
▲ 数据集构建流程
构建流程包括五个关键步骤:
收集:从 Videvo 和 Pexels 等公共视频源获取约 45 万个视频
注释:实现自动化注释流程
-
使用 Recognize Anything Model 进行开放式视频标记以识别主要物体
-
基于检测到的物体标签,使用 Grounding DINO 检测物体边界框
-
将这些边界框作为 SAM2 的提示,生成高质量掩码分割
分割:使用 PySceneDetect 识别场景转换并分割掩码序列,确保每个掩码序列对应单个连续镜头,将序列分割为 10 秒间隔,丢弃短片段(<6 秒)
选择:应用三个关键标准
-
美学质量:使用 Laion-Aesthetic Score Predictor 评估
-
运动强度:使用 RAFT 通过光流测量预测
-
内容安全性:通过 Stable Diffusion 安全检查器评估
生成描述:利用最先进的视觉语言模型 CogVLM2 和 GPT-4o,均匀采样关键帧并生成密集的视频描述和掩码对象的详细描述

实验结果
VideoPainter 在 DAVIS 和 VPBench 两个基准测试集上进行了全面评估。结果表明,VideoPainter 在视频修复和视频编辑任务中均优于现有最先进的方法。

▲ VideoPainterInp
在标准和长视频修复任务中,VideoPainter 都取得了卓越的表现:
-
非生成式方法 ProPainter 无法生成完全被掩码覆盖的物体
-
生成式方法 COCOCO 在修复区域无法保持一致的 ID(如不一致的船只外观和突然的地形变化)
-
VideoPainter 能生成超过一分钟的连贯视频,同时通过 ID 重采样保持 ID 一致性

▲ VideoPainterEdit
在视频编辑任务中,VideoPainter 同样表现优异,能够生成无缝的动画效果,保持平滑的时间过渡和精确的背景边界。

总结与展望
VideoPainter 是第一个具备即插即用控制能力的双分支视频修复框架,其三个关键创新为:
1. 与任何预训练视频 DiT 兼容的轻量级即插即用上下文编码器
2. 维持长视频 ID 一致性的修复区域 ID 重采样技术
3. 可扩展的数据集构建流程
虽然 VideoPainter 在视频修复和编辑任务中取得了卓越的表现,但仍存在一些限制:生成质量受基础模型限制,可能在复杂物理和运动建模方面存在困难;在处理低质量掩码或不匹配的视频描述时效果次优。
(文:PaperWeekly)