


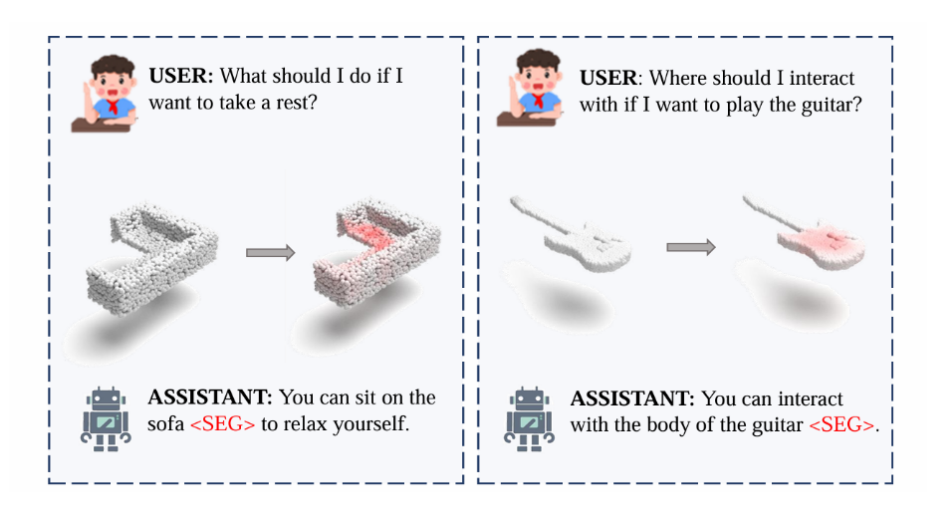
你是否想过,未来的机器人如何真正理解并完成我们日常生活中的各种复杂任务?
想象一下这样的场景:你走进厨房,告诉家中的机器人:“帮我用微波炉热一下碗里的饭。”对人类来说,这似乎再简单不过,但机器人要真正理解并执行这一指令却并不容易。这背后涉及一系列复杂且有序的动作:机器人需要先“拿起碗”,再“打开微波炉”,最后将碗准确地“放进去”。
机器人如何知道要拿起碗的哪个部分?怎么理解微波炉门能打开?其实,这背后隐藏着一个重要的概念——可供性(Affordance)。可供性是物体本身提供给人或机器人执行某种动作的能力或属性,例如,椅子的可供性可以是“坐”,杯子的可供性可以是“握”,微波炉的可供性可能是“打开”或“放入物品”。
因此,对机器人而言,理解物体的可供性,意味着知道对环境中的哪个部分进行怎样的操作,从而精准地完成我们给出的具体指令。
然而,目前的 AI 方法通常只能识别单个物体的单个动作,比如“抓住杯子”或“打开抽屉”,当需要理解和执行涉及多个物体、多个步骤的复杂指令时,却往往无法有效处理。
为了解决这一挑战,我们首次提出了一种全新的框架——Sequential 3D Affordance Reasoning(SeqAfford),即序列化 3D 可供性推理。
该框架创新性地将 3D 视觉与多模态大语言模型相结合,使 AI 具备将复杂的语言指令精准拆解为一系列具体可执行的 3D 可供性区域的能力,从而让机器人真正做到精准理解并高效执行人类的意图。该论文已被 CVPR 2025 接收。

论文标题:
SeqAfford: Sequential 3D Affordance Reasoning via Multimodal Large Language Model
论文链接:
https://arxiv.org/pdf/2412.01550
项目链接:
https://seq-afford.github.io/
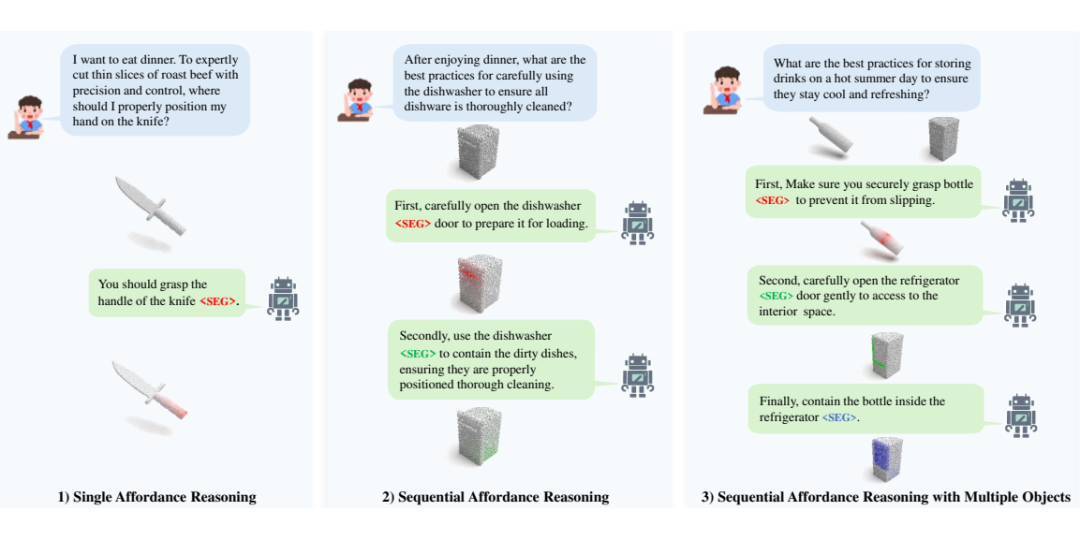
▲ 图1. 序列化 3D 可供性推理任务,涵盖不同类型的交互场景。我们提出了 SeqAfford,一个能够根据人类指令进行序列化可供性推理的多模态语言模型(MLLM),具体包括以下三种任务场景:1)单一可供性推理;2)序列化可供性推理;3)多物体场景下的序列化可供性推理

数据集
序列化 3D Affordance 数据集
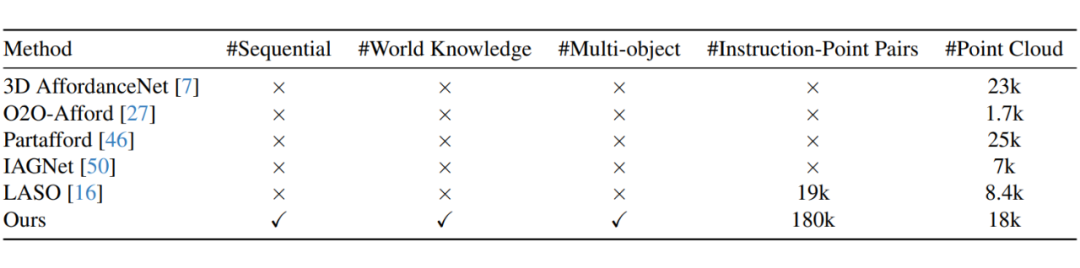
▲ 表1. 现有 3D 可供性数据集与我们构建的数据集的对比
为了让模型真正理解连续、多步操作任务,我们构建了首个 Sequential 3D Affordance 指令微调数据集,共包含超过 18 万个指令与点云数据对。
与传统单一物体单一指令的数据集不同,我们的 Sequential 3D Affordance Benchmark 专注于捕捉人类复杂意图,从简单的“抓起杯子”到复杂的“用微波炉热饭”等多步任务,涵盖了 23 个物体类别和丰富的交互动作序列。

▲ 图2. 指令数据生成流程。 为了更好地利用 GPT-4 模型的世界知识,我们设计了四种不同的系统提示,以生成多样化的交互指令。
我们的数据集通过 GPT-4o 结合四种不同类型的输入方式自动生成多样的指令:
(a)纯文本提示,通过指定物体类别和具体功能生成指令;
(b)文本加 3D 物体渲染图,提升视觉上下文的准确性;
(c)文本加物体 3D 渲染图与人类实际交互图片,增加真实世界交互细节;
(d)文本加 3D 物体渲染图以及具体场景描述,进一步提高任务的情景理解能力。
这种多模态数据构建方式不仅保证了指令的多样性,也强化了 AI 对真实世界的理解能力。

方法
2.1 3D 多模态大语言模型(3D MLLM)
我们选择了预训练的 3D 多模态大语言模型 ShapeLLM 作为基础模型,并在此基础上进行了针对序列化可供性任务的监督微调(Supervised Fine-tuning)。ShapeLLM 通过大规模数据的预训练,已经实现了初步的 3D 视觉信息与文本特征的对齐,具备较好的开放世界(Open-world)泛化能力和语言推理能力。
相比于现有的可供性方法(一般仅采用纯视觉或分离的视觉-语言编码器),这种统一的 3D 多模态架构使得 SeqAfford 能够更好地利用语言模型丰富的常识知识,进一步提升了模型在序列化 3D 可供性任务上的泛化性与灵活性。
2.2 基于分割词汇的序列化可供性推理
尽管 3D MLLM 具有较强的常识推理能力,但原始设计并不具备直接进行密集可供性区域分割的能力。为此,我们受 LISA 方法启发,在模型的输出中引入了一系列特殊的分割词汇(<SEG> Tokens),以有效衔接语言推理与密集分割任务。
具体而言,当 SeqAfford 接收到复杂的人类语言指令与点云数据时,3D MLLM 首先将语言指令进行语义理解,并拆解为多个带有空间语义的 <SEG> Tokens。
这些 Token 分别对应于指令中不同的可供性区域和动作顺序,使模型能够准确地预测一系列清晰且具有实际意义的交互动作区域,从而真正实现语言推理与视觉感知任务之间的紧密衔接。
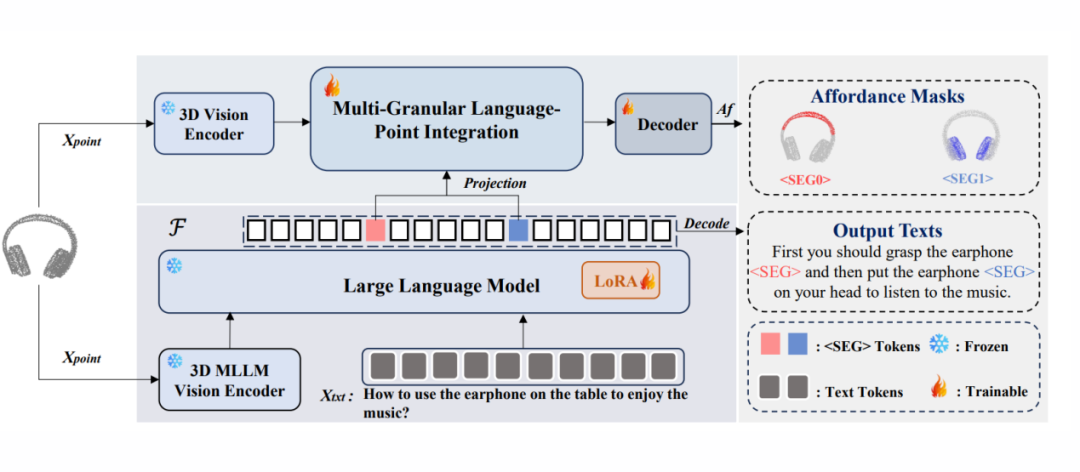
▲ 图3. SeqAfford 总体框架示意图
2.3 多粒度语言-点云融合模块(Multi-Granular Language-Point Integration)
为了进一步精准地将语言模型推理的结果映射到点云空间,我们提出了多粒度语言-点云融合模块,该模块包含两个关键阶段:
1)多粒度特征传播阶段:我们通过逐级特征上采样的方式,获得了从粗略到精细的多粒度点云特征表示,使得模型能够同时兼顾语义的完整性和局部区域的精细定位能力。
2)语言-点云跨模态融合阶段:在这一阶段,我们使用语言模型产生的 <SEG> Tokens 作为查询(Query),对密集点云特征进行跨模态注意力融合,有效地将语言模型高层次的语义知识精确投影到视觉空间中,最终实现细粒度的 3D 可供性分割。
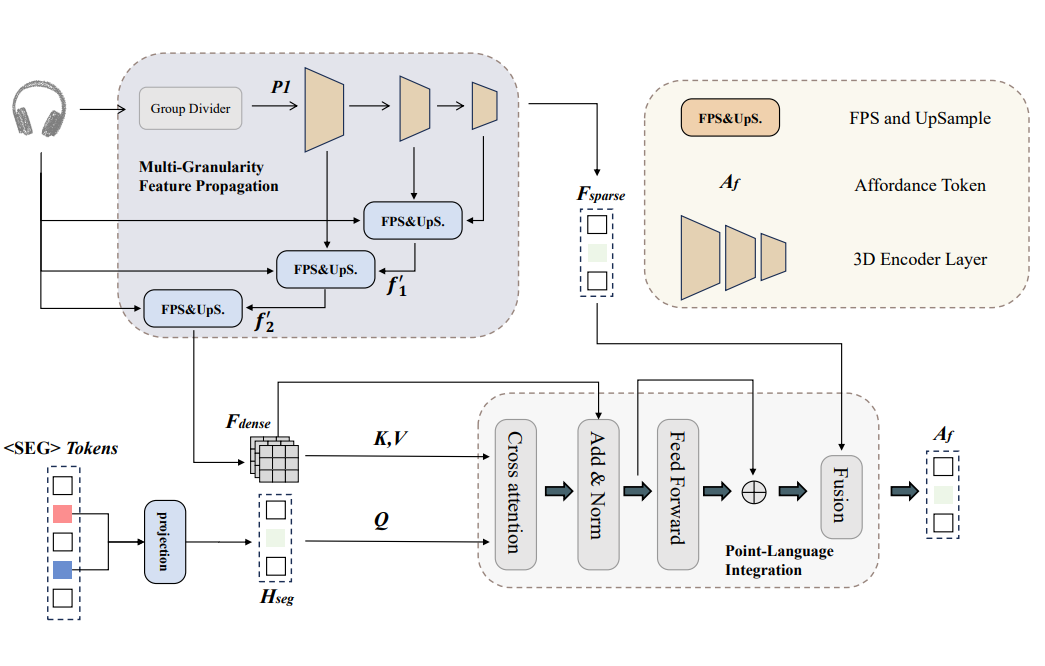
▲ 图4:多粒度语言-点云融合模块

实验
3.1 可供性推理性能评估
我们在所构建的 Sequential 3D Affordance Benchmark 上,针对 Seen、Unseen 和 Sequential 三种评测设置,对 SeqAfford 进行了性能评估,主要指标包括 mIoU、AUC、SIM 和 MAE。
实验结果如表 2 所示:
-
在 Seen 设置下,SeqAfford 的 mIoU 达到 19.5%,相比次优方法 PointRefer(16.3%)有明显提升,且其他指标也取得了更好的表现,表明模型能够更准确地识别和分割目标可供性区域。
-
在 Unseen 设置下,模型依然取得了 13.8% 的 mIoU,高于次优方法 PointRefer(12.4%),体现出较好的泛化能力。
-
在关键的 Sequential 设置中,模型也取得了最佳表现(mIoU 为 14.6%),证明了 SeqAfford 具备有效的序列化推理能力。
通过可视化对比(如图所示),我们进一步验证了 SeqAfford 相较于现有先进方法(如 LASO)更能准确地定位和理解用户指令中对应的交互区域。

3.2 消融实验分析
为了进一步探讨模型各组件对性能的贡献,我们进行了详细的消融实验:
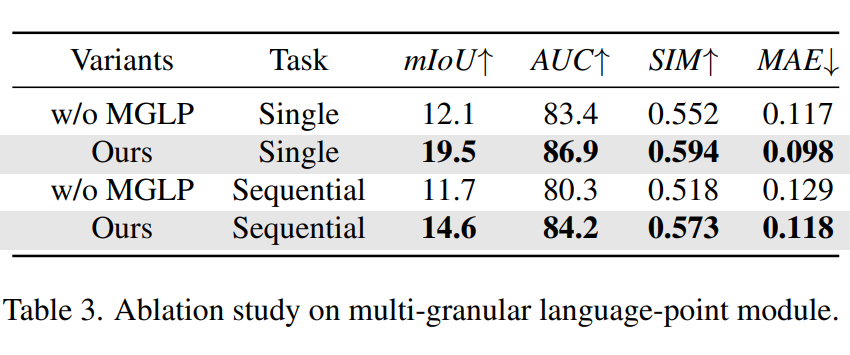
多粒度语言-点云融合模块(MGLP)的有效性:
实验表明,去除 MGLP 模块后,模型的性能明显下降。单步任务 mIoU 从 19.5% 下降至 12.1%,序列任务 mIoU 则从 14.6% 下降至 11.7%。这一结果证实了 MGLP 模块对于语言模型推理结果向视觉空间的精确映射带来明显增益。
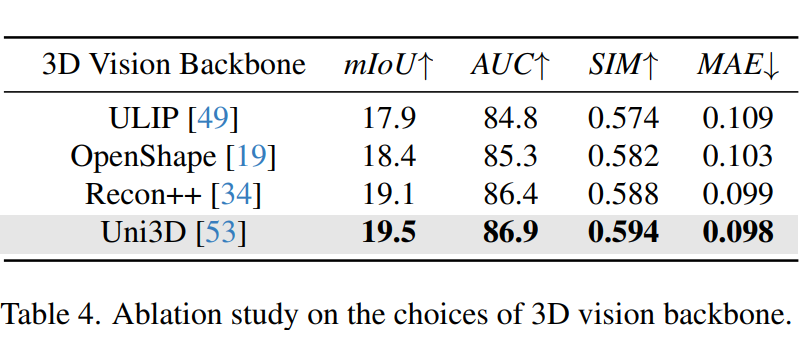
不同视觉骨干网络的对比:
我们对多种不同的 3D 视觉编码器进行了实验对比,结果显示,Uni3D 视觉编码器的表现(mIoU 19.5%)超过了 Recon++(19.1%)、OpenShape(18.4%)和 ULIP(17.9%),因此最终选择了 Uni3D 作为我们模型的视觉编码骨干网络。
泛化能力分析:
此外,我们还在 ModelNet40 数据集上进行了泛化能力的定性分析(如图所示)。结果表明,SeqAfford 能较好地泛化到未训练过的数据,理解并预测目标物体的可供性区域,展现出良好的泛化潜力。
▲ 图5. 模型在 ModelNet40 数据集上的可视化结果

结论
综上所述,我们借助多模态大语言模型的语义理解与常识推理能力,首次提出了「从语言指令到序列化可供性分割」的 SeqAfford 框架,并通过创新的分割标记(SEG Token)机制,有效实现了语言推理与视觉空间分割的精准对齐,显著提升了 3D 物体可供性区域的预测质量。
与已有的可供性方法相比,SeqAfford 在序列化 3D Affordance 数据集的多个评测设置上均取得了明显的性能提升。此外,我们通过充分的消融实验与泛化分析验证了模型设计的合理性与有效性。
未来,我们将进一步探索场景级别的序列化可供性推理,以支持更复杂、更贴合真实需求的机器人交互任务。
(文:PaperWeekly)