

原文发布于 2025 年 2 月 10 日
我们启动 Open R1 项目已经两周了,这个项目是为了把 DeepSeek R1 缺失的部分补齐,特别是训练流程和合成数据。
这篇文章里,我们很高兴跟大家分享一个大成果:
除此之外,我们还聊聊社区里一些让人兴奋的进展,比如怎么整理出小而精的高质量数据集来微调模型,以及如何在训练和推理时控制推理模型的“思考步数”。
一起来看看吧!
OpenR1-Math-220k 数据集
DeepSeek R1 的厉害之处在于,它能把高级推理能力“传授”给小模型。DeepSeek 团队生成了 60 万条推理记录,用来微调 Qwen 和 Llama 系列模型,结果证明,不用强化学习,直接从 R1 “蒸馏”出来的效果也很棒。比如,DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上拿下了 55.5% 的成绩,比更大的 QwQ-32B-Preview 还强。
不过,这些推理记录没公开,这就促使社区自食其力,重新创建了几个类似的数据集。比如
-
OpenThoughts-114k https://hf.co/datasets/open-thoughts/OpenThoughts-114k -
Bespoke-Stratos-17k https://hf.co/datasets/HuggingFaceH4/Bespoke-Stratos-17k -
Dolphin-R1 https://hf.co/datasets/cognitivecomputations/dolphin-r1/viewer/reasoning-deepseek -
LIMO https://hf.co/datasets/GAIR/LIMO
🐳 隆重介绍 OpenR1-Math-220k!这是一个用 512 台 H100 机器本地跑出来的大规模数学推理数据集,每个问题还配了好几个答案。我们跟
-
Numina https://projectnumina.ai -
NuminaMath-CoT https://hf.co/datasets/AI-MO/NuminaMath-CoT
这个 OpenR1 数据集跟其他的有啥不一样:
-
80 万条推理记录: 我们用 DeepSeek R1 为 40 万道题各生成了两个答案,筛完后剩下 22 万道题,每道题都有靠谱的推理过程。https://hf.co/deepseek-ai/DeepSeek-R1 -
512 台 H100 本地跑: 没用 API,我们靠 vLLM 和SGLang 在自家科学计算集群上搞定,每天能生成 18 万条推理记录。https://github.com/vllm-project/vllm/ https://github.com/sgl-project/sglang? -
基于 NuminaMath 1.5 : 我们主攻数学推理,针对 NuminaMath 1.5 (NuminaMath-CoT 的升级版) 里的题目生成答案。https://hf.co/datasets/AI-MO/NuminaMath-1.5 https://hf.co/datasets/AI-MO/NuminaMath-CoT -
自动筛选: 用 Math Verify 只留下至少一个正确答案的题目,还请Llama3.3-70B-Instruct 当“裁判”,捞回更多靠谱答案 (比如有些答案格式乱了,规则解析器认不出来)。https://github.com/huggingface/Math-Verify https://hf.co/meta-llama/Llama-3.3-70B-Instruct -
性能追平 DeepSeek-Distill-Qwen-7B : 我们在数据集上微调Qwen-7B-Math-Instruct ,效果不输原版 DeepSeek-Distill-Qwen-7B。https://hf.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B https://hf.co/Qwen/Qwen2.5-Math-7B-Instruct
我们希望这个可扩展、高质量的推理数据生成方法,不仅能用在数学上,还能拓展到代码生成等领域。
数据怎么来的
为了搞出 OpenR1-220k,我们让
“请一步步推理,最后把答案写在 \boxed{} 里。”
每道题最多给 16k token ,因为我们发现 75% 的题 8k token 就能搞定,剩下的基本得用满 16k。一开始用 vLLM 跑推理,每台 H100 一小时能生成 15 个答案,脚本也在之前的更新和 Open R1
-
Open R1 仓库 https://github.com/huggingface/open-r1 -
SGLang https://github.com/sgl-project/sglang
每道题我们生成了两份答案,有些甚至四份,这样筛选和训练时更灵活。这种做法跟 DeepSeek R1 的拒绝采样差不多,还能支持 DPO 这种偏好优化方法。
生成脚本:
未筛过的数据集:
数据怎么筛的
为了确保只留下高质量、正确的推理过程,我们用
结果发现,55% 的题至少有一个正确答案。但 NuminaMath 1.5 里有些标准答案是空的,或者格式没法自动校验,挺麻烦的。虽然我们升级了 Math-Verify,让它能更好地处理这些怪格式 (后面会讲改进),但还是找了个备用方案: 用 Llama-3.3-70B-Instruct 当“裁判”,从被拒的答案里救回一些靠谱的。先把不完整或标准答案空的样本筛掉,只看格式 OK、答案框得清楚的,最后救回了 2.8 万道题。
我们给 Llama3.3-70B-Instruct 的指令是:
你是数学答案的检查员。给你一道题,你得对比标准答案和模型的最终答案,看看是不是一个意思,哪怕格式不一样。
题目:
{problem}
标准答案:
{answer}
模型答案:
{generation}
只看模型给的最终数学答案,别管这些差别:
- 格式 (比如 \boxed{} 和普通文本)
- 多选题形式 (比如 “A” 和完整答案)
- 坐标对或答案的顺序
- 等价的数学表达或符号差异
- 如果模型答案乱七八糟,就说“结果: 不确定”
先简单说两三句你的对比思路,然后给出结论,用这几种格式:
- “结果: 一样”
- “结果: 不一样”
- “结果: 不确定”
结合规则校验 (Math Verify) 和 LLM 判断,我们既保证了数据质量,又没牺牲规模。最终数据集有 22 万道题,推理过程都经过验证,是个训练推理模型的好资源。每道题多份答案也方便社区筛选更好的结果,或者根据 NuminaMath 的数据来源和题型再做调整。
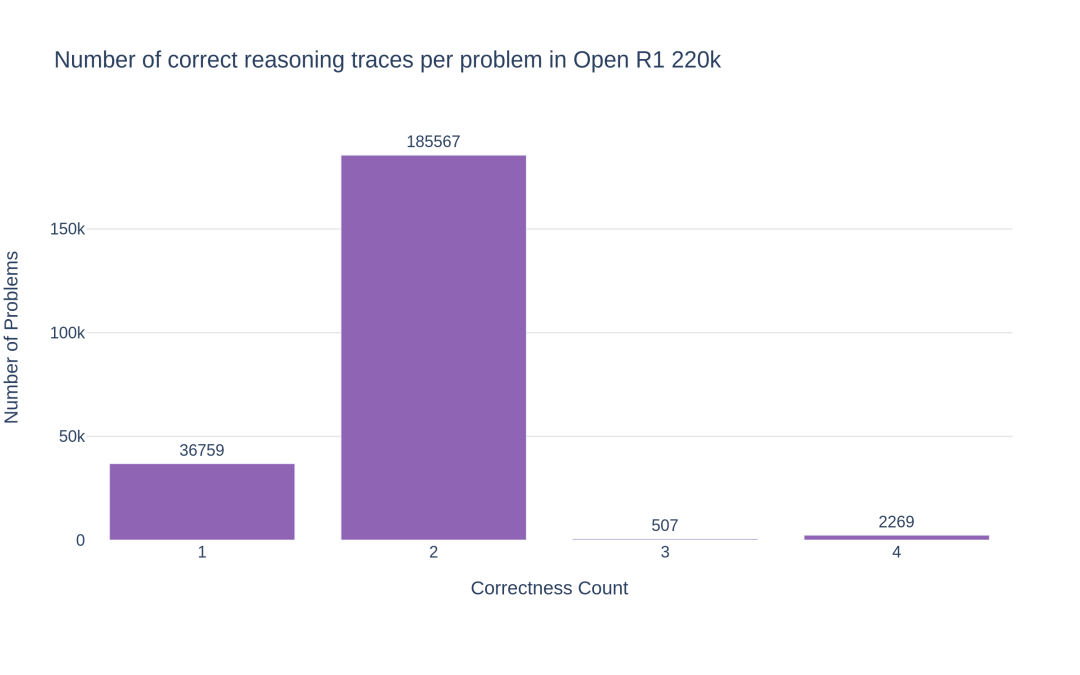
数据集分两块:
-
default(9.4 万道题): SFT 微调后效果最好。 -
extended(13.1 万道题): 加了 NuminaMath 1.5 的其他来源,比如cn_k12,推理记录更多。但在这部分微调后效果不如default,可能是cn_k12的题太简单了。
对于多正确答案的题,我们还试了用奖励模型 (RM) 挑最好的。每道题如果 R1 给了好几个正确答案,我们去掉思考过程 ( <think>…</think> ),把问题和答案丢给
跟 DeepSeek-Distill-Qwen-7B 比比性能
我们用 5e-5 的学习率,在 default 数据集上微调了 Qwen2.5-Math-Instruct 三轮。为了把上下文长度从 4k 拉到 32k,我们把 RoPE 频率调到 300k。训练用的是线性学习率,前面 10% 是预热。下面是用
-
lighteval https://github.com/huggingface/open-r1?tab=readme-ov-file#evaluating-models -
OpenR1-Qwen-7B https://hf.co/open-r1/OpenR1-Qwen-7B -
DeepSeek-Distill-Qwen-7B https://hf.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B -
OpenThinker-7B https://hf.co/open-thoughts/OpenThinker-7B
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这版数据集只是个起点,社区还能再优化,比如用 DeepSeek R1 的拒绝采样法提高质量。
Math-Verify 升级了啥
我们在检查 Math-Verify 的结果时发现了一些问题,就做了大修。强烈建议大家升到最新版 (0.5.2),体验这些改进:
pip install math-verify==0.5.2
主要升级有:
-
改进了纯文本答案的解析和验证 (比如 和 算一样)。
-
改进了答案列表的解析 (比如 和 和 跟 等价)。
-
修了个 bug,单个 LaTeX 里多个框的答案也能认了 (比如 等于 {1,2})。
-
加了有序元组。因为判断列表是元组还是集合非常困难,我们靠标准答案来定:
-
(1,2,3) ≠ {3,2,1}; 1,2,3 == {3,2,1}; {3,2,1} == {1,2,3}。 -
支持标准答案的关系表达 (比如小于) 和预测的区间 (比如 等价于 )。
社区热点
这周社区从各种角度玩转了 GRPO,还有研究表明,只要 1000 个优质样本,就能让现有开源模型引发推理。
GRPO 的一些实践
-
nrehiew 证明 把 GRPO 用在 Qwen2.5-0.5B 基础模型上,在 GSM8k 测试中拿下 51% 的准确率,比 Qwen2.5-0.5B-Instruct 高了 10 个点。这成绩太亮眼,引发了大家对预训练中指令数据作用的热议 。不过,把 GRPO 用到其他基础模型 (比如 Llama 3) 上还没啥大突破。Sea AI Lab (SAIL) 的研究 发现,基础模型稍微提示一下就能自我反思,DeepSeek-R1 论文里的“开悟”可能更多是模型本身牛,而不是 RL 优化的功劳。https://x.com/nrehiew_/status/1887874867225063543 https://x.com/abacaj/status/1888644577604563240 https://www.notion.so/Open-R1-Update-2-1961384ebcac80efb364e947cec44c91?pvs=21 -
Unsloth 施展 优化魔法 ,让 15B 参数的模型只用 15GB 显存就能跑 GRPO 🤯。这下 Google Colab 免费也能玩了!https://unsloth.ai/blog/r1-reasoning -
Axolotl 的 Wing Lian 发现DoRA 比 LoRA 和全微调收敛快 。https://github.com/axolotl-ai-cloud/axolotl https://x.com/winglian/status/1888951180606202028 -
Alexander Doria 搞出了 给诗歌设计的奖励函数 ,这很酷,因为 GRPO 第一次公开跳出“可验证”领域。https://x.com/Dorialexander/status/1886176543593894387
测试表现
这周
-
2025 AIME I https://artofproblemsolving.com/wiki/index.php/2025_AIME_I?srsltid=AfmBOoqknvf_6DwLAOY55UF1k21ilYYaSwo7QWzl9impFvE_XXMpfY7r -
ETH Zurich 的研究人员测了一堆模型,发现性能波动 远小于预期,只有 10-20 个百分点。https://x.com/mbalunovic/status/1887962694659060204 https://x.com/9hills/status/1888742869625905536 -
但
Dimitris Papailiopoulos 发现 AIME 2025 有几道题网上早就有了!这可能不小心泄了题,凸显了给 LLM 出新题有多难 。https://x.com/DimitrisPapail/status/1888325914603516214 https://x.com/hyhieu226/status/1888653916663132319
LLM 必须用自然语言推理吗?
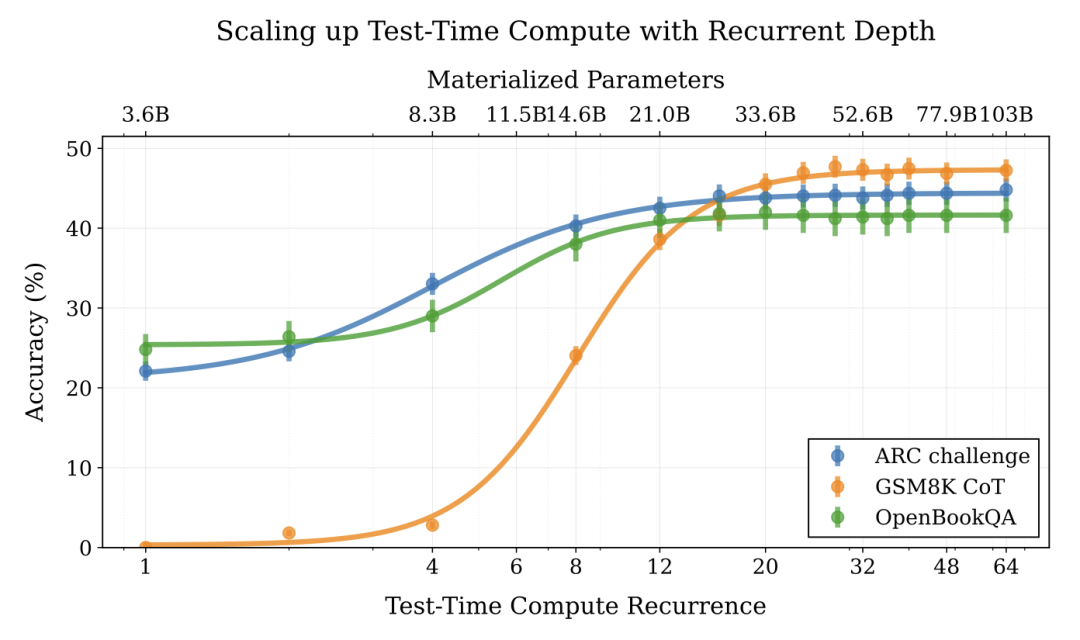
一篇新
-
论文 https://arxiv.org/abs/2502.05171 -
Meta 的 Coconut 项目 https://arxiv.org/abs/2412.06769
小而精的推理数据成趋势?
DeepSeek R1 用 60 万条推理记录搞蒸馏,但最近研究发现,不用海量训练,少量精心挑的样本也能让模型学会复杂推理。
比如
-
s1K https://hf.co/datasets/simplescaling/s1K -
Gemini Flash https://deepmind.google/technologies/gemini/flash-thinking/
另一个
控制思维链长度: 预算强制和奖励设计
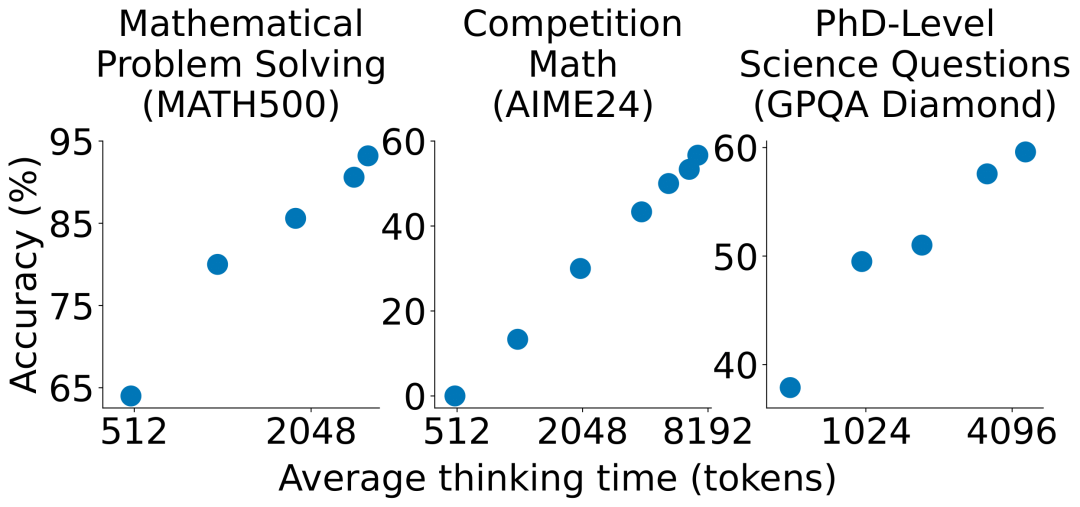
类似地,
下一步干啥?
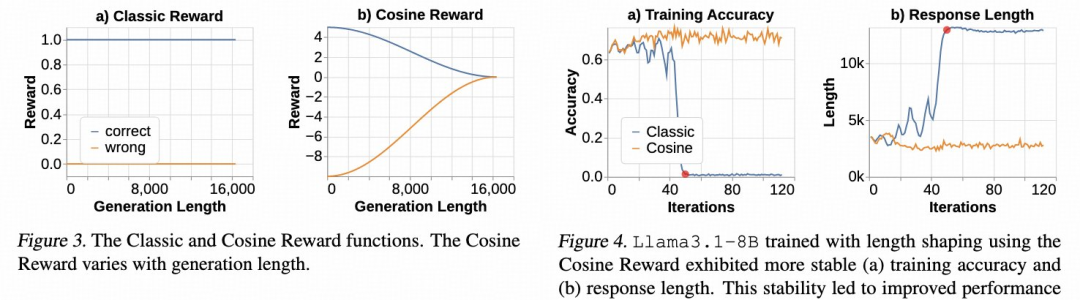
GRPO 在 TRL 里跑得挺顺,我们正在大干一场实验,看看哪些超参数和奖励函数最管用。想知道进展,可以去
想加入我们?去
-
GitHub 的 open-r1 仓库 https://github.com/huggingface/open-r1 -
Hugging Face 的 open-r1 组织 https://hf.co/open-r1
英文原文:
https://hf.co/blog/open-r1/update-2 原文作者: Loubna Ben Allal, Lewis Tunstall, Anton Lozhkov, Elie Bakouch, Guilherme Penedo, Hynek Kydlicek, Gabriel Martín Blázquez
译者: yaoqih
(文:Hugging Face)